写在前面:两种误差
- 训练误差:模型在训练数据上得误差
- 泛化误差:模型在新数据上的误差
- 泛化误差(generalization error)是指, 模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。
如何计算训练误差和泛化误差:
- 验证数据集:一个用来评估模型好坏的数据集
- 验证数据集一定不能和训练数据集混淆在一起
- 测试数据集:只用一次的数据集
K-则交叉验证:
注意:数据集不大的情况下,通常采用K则交叉验证

 过拟合和欠拟合:
过拟合和欠拟合:
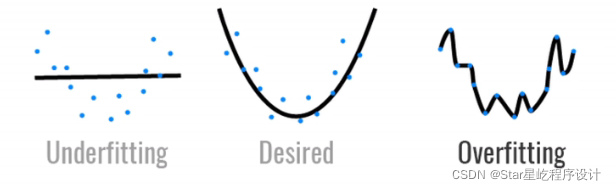
数据简单的时候选择复杂的模型,就会出现过拟合;数据复杂的时候选择简单的模型会出现欠拟合 模型容量的影响:
模型容量的影响:
- 模型容量需要匹配数据复杂度,否则可能导致欠拟合或者过拟合。
如果想要确保泛化误差减小,就需要接受一定程度的过拟合,这在深度学习中是情理之中的。
 ?正态、欠拟合、过拟合代码模拟:
?正态、欠拟合、过拟合代码模拟:

数据准备:
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
#power(x, y) 函数,计算 x 的 y 次方
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
#同样,存储在poly_features中的单项式由gamma函数重新缩放, 其中 Γ(n)=(n?1)! 。
# 从生成的数据集中查看一下前2个样本, 第一个值是与偏置相对应的常量特征。
# NumPy ndarray转换为tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=
torch.float32) for x in [true_w, features, poly_features, labels]]
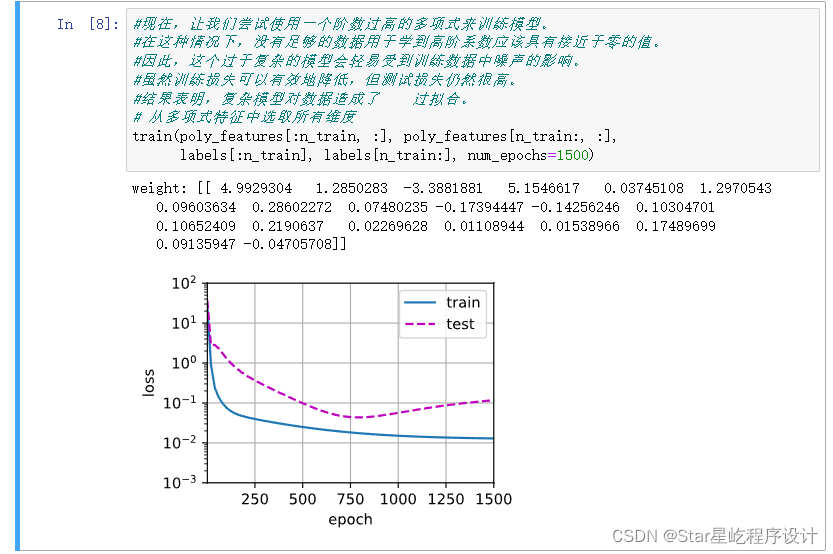
print(features[:2], poly_features[:2, :], labels[:2])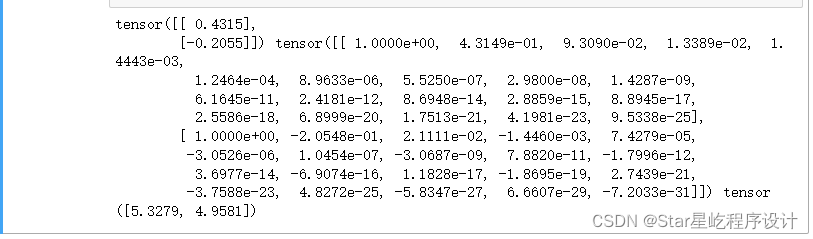
损失评估和训练函数:

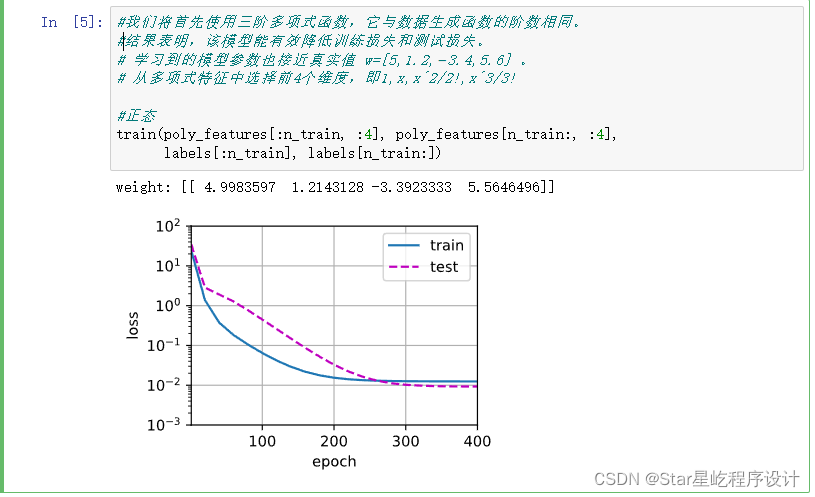
正态情况:
?欠拟合情况:
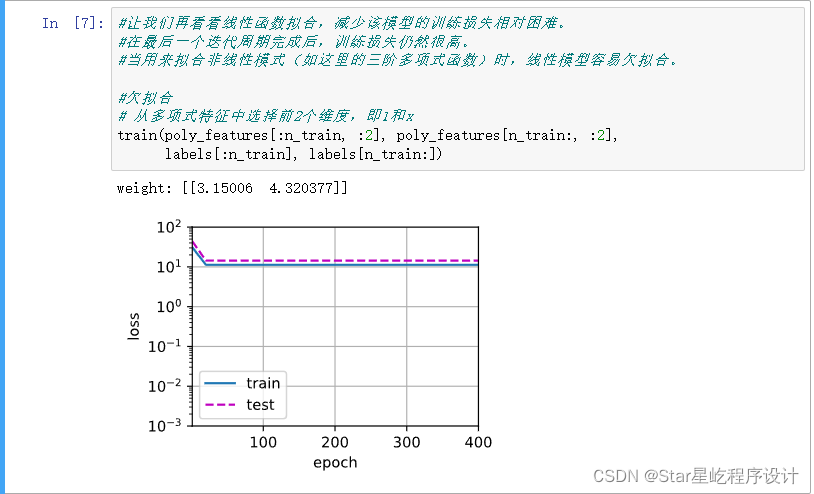
?过拟合情况:
注意:用于对抗过拟合的技术称为正则化(regularization)