Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
代码
Pattern-Exploiting Training (PET)模式开发训练,一种半监督训练程序,将输入示例重新表述为完形填空式短语,以帮助语言模型理解给定任务。然后使用这些短语将软标签分配给大量未标记的样本。
这个笔记挺好的
介绍
由于大量的语言、领域和任务以及注释数据的成本,在 NLP 的实际使用中通常只有少量标记的示例,这使得小样本学习成为一个非常重要的研究领域.
PET 分三个步骤工作:
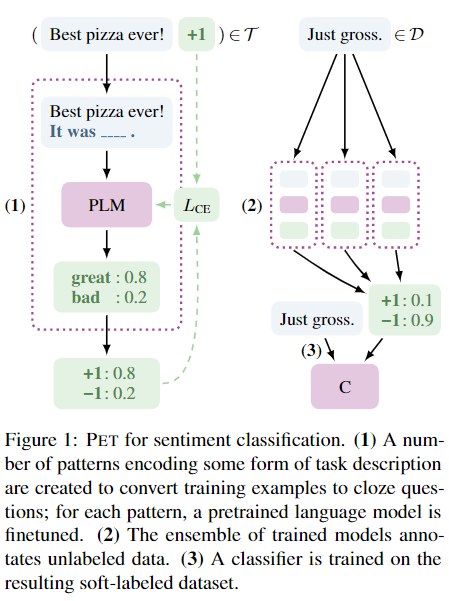
1.对于每个模式,一个单独的预训练语言在一个小的训练集 T 上进行微调。
2.使用所有模型的集合来注释一个带有软标签的大型未标记数据集 D。
3.最后,在软标记数据集上训练标准分类器。
iPET,这是 PET 的一种迭代变体,随着训练集大小的增加,这个过程会不断重复。在多种语言的各种任务中,我们表明,给定少量到中等数量的标记示例,PET 和 iPET 大大优于无监督方法、监督训练和强大的半监督基线
模型
核心是这个pattern-verbalizer pair (PVP).模式-语言器 对
M 是一个掩码语言模型 (MLM)
T 是它的词汇表
- ∈ T 是掩码标记
将语言器定义为一个单射函数 v : L→V,它将每个标签映射到 M 词汇表中的一个单词。
(P,v)定义成PVP
PET 的核心思想是从 v(y) 是 P(x) 中被掩蔽位置的“正确”标记的概率推导出 y 作为 x 的正确输出的概率。
z 表示完形填空格式的输入记录,由至少 k 个掩码组成。对于任务词汇表中的每个标记 t,掩蔽语言模型 M 分配给输入记录 z 中第 k 个掩蔽位置处的标记的概率由 q_k_M(t|z) 给出。对应于 M 的 logit(指数函数)由 s_k_M(t|z) 给出
我们使用 qp(l | x) 和训练样本 (x,l) 的真实分布(one-hot)之间的交叉熵,对所有 (x,l) ∈ T 求和,同时作为 p 微调 M 的损失值。
PET ( Pattern-Exploiting Training ) 模式开发训练的工作原理:
输入 x = (x1, x2) 转换为完形填空题 P(x);x 是一个问题和一个答案,分为一个问题 x1、一个掩码和一个答案 x2。语言器输出需要预测掩码位置 v(y) 中的标记。根据预测的token值,将推断输出(y)。y 有两种选择:包含和不包含(“not_entailment”)。每个 y 的 q_p(y | x) 是从 v(y) 作为掩蔽位置的合理选择的概率得出的。具有最高概率的 y 值将分配给输入 x。
Iterative PET (iPET) 迭代Pet
通过使用训练过的 PET 模型的随机子集标记从 D 中选择的示例来扩大原始数据集 T。然后扩大的数据集上训练新一代的 PET 模型,重复这个过程。
总结
训练数据少,PET 有效!有助于利用预训练语言模型中包含的知识来完成下游任务
其实没太懂