从回归到多类分类

从回归到多类分类-均方损失

从回归到多类分类-无校验比例

从回归到多类分类-校验比例

Softmax和交叉熵损失


损失函数
L2 Loss
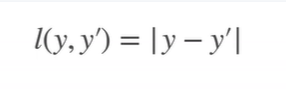
L1 Loss
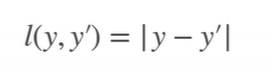
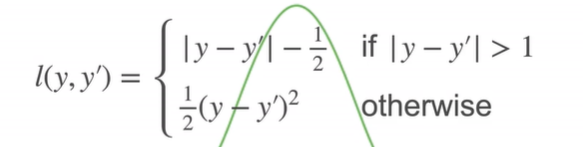
Huber’ s Robust Loss
图像分类数据
(MNIST数据集) :cite:LeCun.Bottou.Bengio.ea.1998 (是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单。 我们将使用类似但更复杂的Fashion-MNIST数据集)
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
读取数据集
我们可以[通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中]。
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()#预处理
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)#train=ture下载的是训练数据集
#transform=trans指的是下载的是pytorch的tensor
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
数据下载…

Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
len(mnist_train), len(mnist_test)
每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。 为了简洁起见,本书将高度 ? 像素、宽度 𝑤 像素图像的形状记为 ?×𝑤 或( ? , 𝑤 )。
mnist_train[0][0].shape#1表示黑白图片
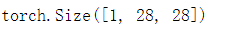
def get_fashion_mnist_labels(labels): #@save
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
创建可视化函数
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
训练集中的前几个样本
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));

为了使我们在读取训练集和测试集时更容易,我们使用内置的数据迭代器,而不是从零开始创建。 回顾一下,在每次迭代中,数据加载器每次都会[读取一小批量数据,大小为batch_size]。 通过内置数据迭代器,我们可以随机打乱了所有样本,从而无偏见地读取小批量。
batch_size = 256
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
timer = d2l.Timer()#测试速度
for X, y in train_iter:
continue
f'{timer.stop():.2f} sec'
