LSTM����ģ��
������Ҫ�̶�һ���ı���������̡���Ϊ��������:
- ���ݴ������Է����ı����ݼ�����Ԥ������
- ģ����������������һ���Ľ��,�õ�ģ�͵�����������
- ģ�ʹ��ѵ�����̡�
����ܹ�����:
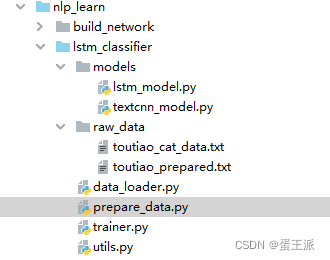
��Ҫ����һ��ԭʼ�ķ����ļ�(ͷ������)��
һ��Ԥ�����ű�prepare_data.py
һ�����ݴ����ű�data_loader.py
һ��ѵ�����̽ű�trainer.py
һ��ģ���ļ�lstm_model.py
��������
����Ԥ����
��ԭʼ���ı�����Ԥ����,ԭʼ�ļ���ʽ����:

�������ļ�����,��ʽΪ �����ı�\t�������

ֻ��Ҫ���� prepare_data.py�������ɴ�������ļ���ע������·�����������Ϊ
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 11:44
@Auth : hcb
@File :prepare_data.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import os
from tqdm import tqdm
class PrepareData(object):
def __init__(self):
self.base_dir = os.path.join(os.path.dirname(__file__), "raw_data")
self.raw_data_path = os.path.join(self.base_dir, "toutiao_cat_data.txt")
self.prepared_data_path = os.path.join(self.base_dir, "toutiao_prepared.txt")
def obtain_raw_data(self):
""""""
with open(self.raw_data_path, "r", encoding="utf8") as reader:
all_lines = reader.readlines()
prepared_data = []
print("���ڴ�������...")
for line in tqdm(all_lines):
info = self.deal_data(line)
if info:
prepared_data.append(info)
# ���洦���õ�����
with open(self.prepared_data_path, "w", encoding="utf8") as writer:
for info in prepared_data:
# print(info)
writer.write(info + "\n")
@staticmethod
def deal_data(line):
""""""
line_split = line.split("_!_")
label_name = line_split[2]
content = line_split[3]
desc = line_split[4]
text = content + " " + desc
text = text.replace("\t", " ")
text = text.replace("\n", " ")
if text and label_name:
return text + "\t" + label_name
else:
return None
if __name__ == '__main__':
prepared_obj = PrepareData()
prepared_obj.obtain_raw_data()
ģ����������
����һ�����ļ���һ������,�õ�ģ�͵�����Cѵ���Ͳ��ԡ��м��漰�ʵ����ɡ��Զ���������Ȳ�����Ŀ����self.train_dataloader��self.test_dataloader���������Ϊ:
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 11:44
@Auth : hcb
@File :data_loader.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import torch
import os
import jieba
from torch.utils.data import DataLoader, Dataset
import numpy as np
from tqdm import tqdm
from sklearn.cross_validation import train_test_split
class BaseData():
__doc__ = "����ѵ�����Ͳ��Լ����ݵ�����"
def __init__(self, args):
self.base_dir = os.path.join(os.path.dirname(__file__), "raw_data")
self.raw_data_path = os.path.join(self.base_dir, "toutiao_prepared.txt")
# self.prepared_data_path = os.path.join(self.base_dir, "toutiao_prepared.txt")
self.use_char = True
self.word2id = {}
self.id2word = {}
self.label2id = {}
self.id2label = {}
self.batch_size = args.batch_size
self.max_seq_len = args.max_seq_len
self.enforced_sorted = True
self.train_dataloader = None
self.test_dataloader = None
self.trainset_idx, self.testset_idx = self.obtain_dataset() # ������
self.obtain_dataloader()
def obtain_dataset(self):
"""
��������
:return: ѵ�����Ͳ��Լ�����������
"""
with open(self.raw_data_path, "r", encoding="utf8") as reader:
all_lines = reader.readlines()
# �����������ͱ�ǩ
dataset = []
for line in tqdm(all_lines, desc="��������"):
sample_text, sample_label = self.clean_data(line)
dataset.append((sample_text, sample_label))
# ����ѵ�����Ͳ��Լ�
train_set, test_set = train_test_split(dataset, test_size=0.5, random_state=10) # ѡ������һ����Ϊ���ݼ�
train_set, test_set = train_test_split(train_set, test_size=0.15, random_state=10)
# ����ѵ��������vocab
self.build_vocab(train_set)
trainset_idx = self.trans_data(train_set)
testset_idx = self.trans_data(test_set)
return trainset_idx, testset_idx
def obtain_dataloader(self):
"""
�������������������ݵĵ�����
:return:
train_dataloader: ѵ����������
test_dataloader: ���Լ�������
"""
train_dataset = MyData(self.trainset_idx)
test_dataset = MyData(self.testset_idx)
# droplast��ΪTrue ��ֹ���һ��batch��������
self.train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=self.batch_size, drop_last=True,
collate_fn=self.coll_batch)
self.test_dataloader = DataLoader(test_dataset, shuffle=True, batch_size=self.batch_size, drop_last=True,
collate_fn=self.coll_batch)
def clean_data(self, line):
"""
�ִʲ���ϴ����
:param line:
:return:
sample_text: ["�����", "Ư��",����Ů��]
label: "����"
"""
text, label = line.split("\t")[0], line.split("\t")[1]
if self.use_char:
sample_text = list(text)
else:
sample_text = jieba.lcut(text)
return sample_text, label
def build_vocab(self, data_info):
"""
�����ʻ���ֵ�
:param data_info:
:return:
"""
tokens = []
labels = set()
for text, label in data_info:
tokens.extend(text)
labels.add(label)
tokens = sorted(set(tokens))
tokens.insert(0, "<pad>")
tokens.insert(1, "<unk>")
labels = sorted(labels)
self.word2id = {word:idx for idx, word in enumerate(tokens)}
self.id2word = {idx:word for idx, word in enumerate(tokens)}
self.label2id = {label: idx for idx, label in enumerate(labels)}
self.id2label = {idx: label for idx, label in enumerate(labels)}
def trans_data(self, data_set):
"""
���ݴʻ���ֵ佫�ı�ת����������
:param data_set:
:return:
"""
data_set_idx = []
for text, label in data_set:
text_idx = [self.word2id[word] if word in self.word2id else self.word2id["<unk>"] for word in text]
label_idx = self.label2id[label]
data_set_idx.append((text_idx, label_idx))
return data_set_idx
def coll_batch(self, batch):
"""
��ÿ��batch���д���
:param batch:
:return:
"""
# ÿ�������ij���
current_len = [len(data[0]) for data in batch]
if self.enforced_sorted:
index_sort = list(reversed(np.argsort(current_len)))
batch = [batch[index] for index in index_sort]
current_len = [min(current_len[index], self.max_seq_len) for index in index_sort]
# ��ÿ��batch����padding
max_length = min(max(current_len), self.max_seq_len)
batch_x = []
batch_y = []
for item in batch:
sample = item[0]
if len(sample) > max_length:
sample = sample[0:max_length]
else:
sample.extend([0] * (max_length-len(sample)))
batch_x.append(sample)
batch_y.append([item[1]])
return {"sample": torch.tensor(batch_x), "label": torch.tensor(batch_y), "length": current_len}
class MyData(Dataset):
def __init__(self, data_set):
self.data = data_set
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return len(self.data)
# if __name__ == '__main__':
# data_obj = BaseData(args=1)
ģ����
������ֻ��Ϊ�˴һ����������̿�ܡ�ģ��ѡ���˼�lstmģ�͡����������Լ���������ģ�͡�
lstm_model.py
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 14:30
@Auth : hcb
@File :lstm_model.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import torch
import torch.nn as nn
import torch.autograd as autograd
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class LSTMClassifier(nn.Module):
def __init__(self, args):
super(LSTMClassifier, self).__init__()
self.args = args
self.hidden_dim = args.hidden_dim
self.word_embeddings = nn.Embedding(args.vocab_num, args.embedding_dim)
self.lstm = nn.LSTM(args.embedding_dim, args.hidden_dim, batch_first=True)
self.hidden2label = nn.Linear(args.hidden_dim, args.class_num)
self.hidden = self.init_hidden()
def init_hidden(self):
# the first is the hidden h
# the second is the cell c
return (autograd.Variable(torch.zeros(1, self.args.batch_size, self.hidden_dim)),
autograd.Variable(torch.zeros(1, self.args.batch_size, self.hidden_dim)))
def forward(self, sentence, lengths=None):
""""""
if not lengths:
self.hidden = self.init_hidden()
embeds = self.word_embeddings(sentence)
x = embeds
lstm_out, self.hidden = self.lstm(x, self.hidden)
y = self.hidden2label(lstm_out[:,-1]) # ����ѡ�������е����һ������
log_probs = F.log_softmax(y)
else:
self.hidden = self.init_hidden()
embeds = self.word_embeddings(sentence)
x = embeds
x_pack = pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=True)
lstm_out, self.hidden = self.lstm(x_pack, self.hidden)
lstm_out, output_lens = pad_packed_sequence(lstm_out, batch_first=True)
y = self.hidden2label(lstm_out[:,-1]) # ����ѡ�������е����һ������
log_probs = F.log_softmax(y)
return log_probs
ѵ������
�����ǿ�ʼѵ���Ͳ���:
# -*- coding: utf-8 -*-
"""
@Time : 2022/2/26 14:38
@Auth : hcb
@File :trainer.py
@IDE :PyCharm
@Motto:ABC(Always Be Coding)
"""
import argparse
import os
from data_loader import BaseData
from models import lstm_model
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from tqdm import tqdm
import torch
from sklearn.metrics import classification_report
def train(args):
# ����ģ���Ż��� ��ʧ������
model = lstm_model.LSTMClassifier(args)
if args.use_cuda:
model = model.cuda()
optimizer = Adam(model.parameters(), lr=args.lr)
loss_function = nn.NLLLoss()
train_dataloader = args.dataloader.train_dataloader
test_dataloader = args.dataloader.test_dataloader
model.train()
for epoch in tqdm(range(args.epoch_num)):
print(f"epoch {epoch}...")
for train_info in tqdm(train_dataloader):
optimizer.zero_grad()
# model.hidden = model.init_hidden()
data = train_info["sample"]
label = train_info["label"]
length = train_info["length"]
if args.use_cuda:
data = data.cuda()
label = label.cuda()
# print("data_size", data.size())
predict_label = model(data, length)
label = label.view(args.batch_size,) # [30, 1] --> [30]
loss_batch = loss_function(predict_label, label)
loss_batch.backward()
# print("loss", loss_batch)
optimizer.step()
print(f"evaluation...epoch_{epoch}:")
true_label, pred_label = [], []
loss_sum = 0.0
with torch.no_grad():
for test_info in test_dataloader:
data = test_info["sample"]
label = test_info["label"]
length = test_info["length"]
label_list = label.view(1, -1).squeeze().numpy().tolist()
true_label.extend(label_list)
predict_label = model(data, length)
predict_label_list = torch.argmax(predict_label, dim=1).numpy().tolist()
pred_label.extend(predict_label_list)
label = label.view(args.batch_size, )
loss_sum += loss_function(predict_label, label)
print(classification_report(true_label, pred_label))
print(f"epoch:{epoch} test data loss: {loss_sum}.")
def main():
args = argparse.ArgumentParser()
args.add_argument("--batch_size", type=int, default=50)
args.add_argument("--lr", type=float, default=0.001)
args.add_argument("--max_seq_len", type=int, default=80)
args.add_argument("--enforced_sorted", type=bool, default=True)
args.add_argument("--embedding_dim", type=int, default=128)
args.add_argument("--hidden_dim", type=int, default=128)
args.add_argument("--num_layer", type=int, default=2)
args.add_argument("--epoch_num", type=int, default=5)
args.add_argument("--use_cuda", type=bool, default=False)
args = args.parse_args()
data_load = BaseData(args)
setattr(args, "dataloader", data_load)
setattr(args, "vocab_num", len(data_load.word2id))
setattr(args, "class_num", len(data_load.label2id))
train(args)
if __name__ == '__main__':
main()
��ע
���������������,���������Ż���չ��ͷ�����ݿ��Դ���������: