аХДћЗчПиШ§:ШчКЮДюНЈжЊЪЖЭМЦз,ИГФмаХДћвЕЮё
ЭбЬЅгкЫбЫїв§ЧцгХЛЏЕФжЊЪЖЭМЦзММЪѕ,БОжЪЩЯЪЧвЛжжНвЪОЪЕЬхЙиЯЕЕФаХЯЂЭјТч,ШчНёвбЙуЗКгІгУгкИїИіСьгђЁЃдкаХДћСьгђ,жЊЪЖЭМЦзвВОГЃБЛИїМвЛњЙЙБъАёЮЊвЛжжЯШНјЕФДѓЪ§ОнгІгУММЪѕЁЃдкСїСПКьРћЪБДњГЩЮЊЙ§ШЅЪНКѓ,аХДћСьгђЛсдНРДдНЧПЕїЖдПЭЛЇЕФОЋЯИЛЏдЫгЊ,МДЖдПЭЛЇвЊзіЕНЧЇШЫЧЇУцЕФЖЈжЦЛЏЗўЮёКЭВпТд,етОЭвЊЧѓаХДћЛњЙЙЖдПЭЛЇвЊга360ЖШШЋОАЪНЕФАбЮе,ВЛНівЊеЦЮеПЭЛЇЕФЛљБОаХЯЂЁЂааЮЊЦЋКУЁЂН№ШкЬиеї,ИќвЊеЦЮеПЭЛЇМфЕФЙиСЊЙиЯЕКЭаХДћЩъЧыааЮЊЕФОлМЏадЬиеї,ЖјжЊЪЖЭМЦздкЪЖБ№ПЭЛЇЙиЯЕКЭОлМЏадЬиеїЗНУцОЭгазХВЛПЩЬцДњЕФгХЪЦЁЃЫљвдНёЬьЮвУЧОЭМђЕЅСФвЛСФЙигкжЊЪЖЭМЦзЕФМИИіЮЪЬт,вЛ,ШчКЮЙЙНЈвЛИіЦѕКЯаХДћвЕЮёЕФжЊЪЖЭМЦз;Жў,жЊЪЖЭМЦздкаХДћвЕЮёжаЕФгІгУгХЪЦгаФФаЉ;Ш§,ШчКЮгІгУетЯюММЪѕШЅИГФмаХДћвЕЮё;вдМАЫФ,жЊЪЖЭМЦзгІгУжаашвЊзЂвтЕФвЛаЉЮЪЬтЁЃ
вЛЁЂШчКЮЙЙНЈжЊЪЖЭМЦз
1ЁЂДюНЈжЊЪЖЭМЦзашвЊФФаЉЪ§Он
ДюНЈжЊЪЖЭМЦзЕФФПЕФжЎвЛдкгкЭъШЋЭкОђГіПЭЛЇМфИїжжДэзлИДдгЕФЙиСЊЙиЯЕ,ЫљвдддђЩЯОЭашвЊАбИїжжгаЙиСЊПЩФмЕФЪ§ОнЖМФЩШыНјРДЁЃСэвЛЗНУц,ЮвУЧЭЌбљашвЊАбПЭЛЇЕФЩэЗнБъЪЖЪ§ОнЁЂживЊЪєадЬиеївВФЩШыНјРД,БугкКѓајЮвУЧЖдПЭЛЇЙиЯЕЕФЗжЮіЁЂЛиЫнМАЙиСЊБфСПЕФМгЙЄЁЃЫљвдЮвУЧДгЙиСЊЪ§ОнЁЂживЊЪєадСНИіЮЌЖШеЙПЊРДНВЁЃ
ЙиСЊЪ§ОнжївЊАќРЈетМИИіЮЌЖШ:
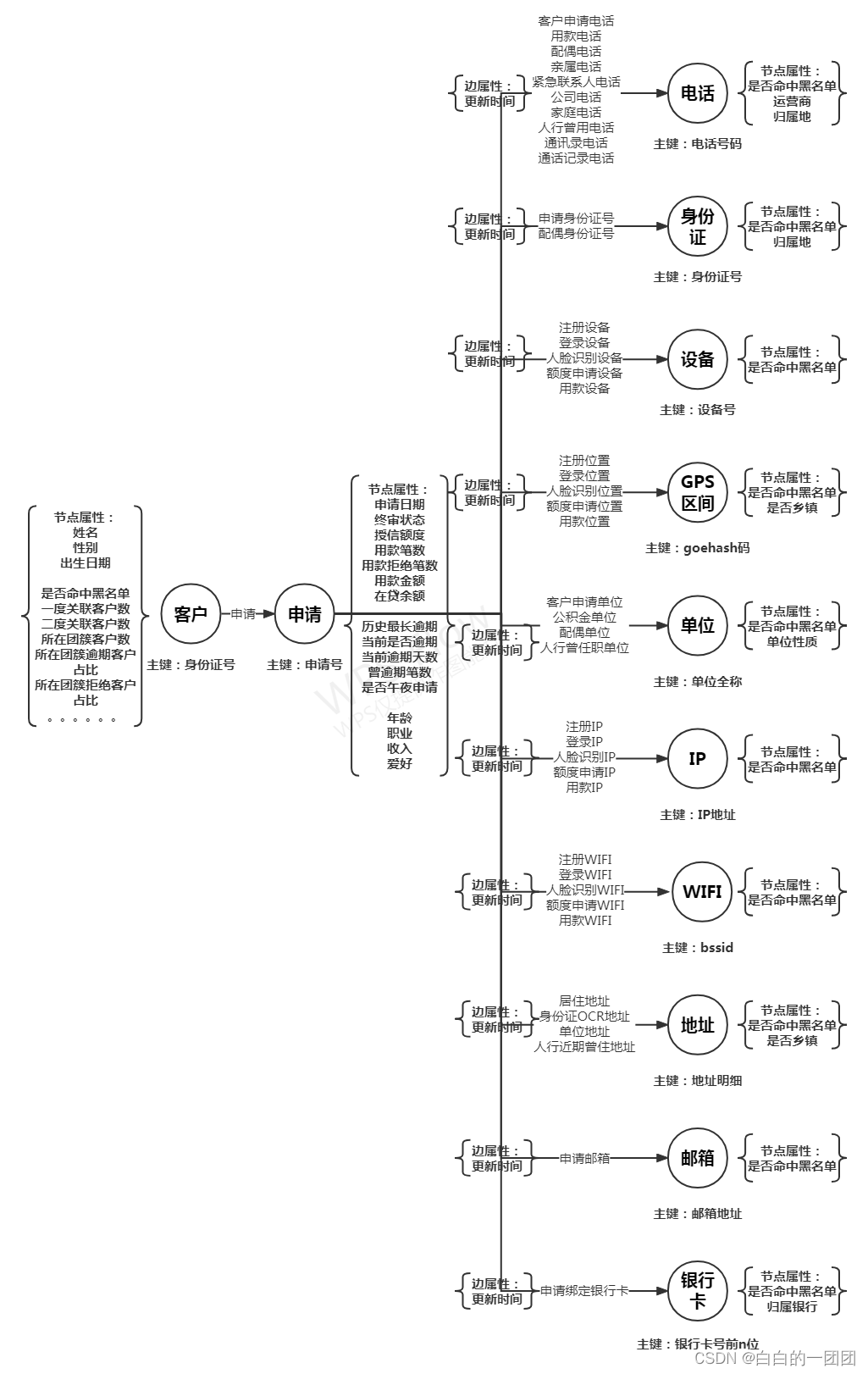
- ЪжЛњКХТыРр:АќРЈПЭЛЇЕФзЂВсЪжЛњКХЁЂгУПюЪжЛњКХЁЂНєМБСЊЯЕШЫЪжЛњКХЁЂХфХМЪжЛњКХЁЂЧзЪєЪжЛњКХЁЂЙЋЫОЕчЛАЁЂМвЭЅЕчЛАЁЂШЫааБЈИцжаНќЦкдјЪЙгУЕчЛА,вдМАЯждкБфЕУвьГЃУєИаЕФЭЈбЖТМЪжЛњКХЁЂЭЈЛАМЧТМЪжЛњКХЕШЕШЁЃетаЉКХТыРрЪ§ОнЗХШыжЊЪЖЭМЦзжаБуФмНЋПЭЛЇжЎМфЕФЧзЪєЙиЯЕЁЂЭЌЕЅЮЛЧщПіЁЂЦНЪБСЊЯЕНєУмЖШЧщПіЗДгГГіРДЁЃетаЉЪ§ОнЗХШыжЊЪЖЭМЦзЧАОЭвЊзЂвтКХТыИёЪНЕФЖдЦыКЭдрЪ§ОнЕФЧхЯДЁЃ
- вјааПЈЪ§Он:ЯждкаХДћвЕЮёЖМЛсНјааnвЊЫибщжЄ,вЛАувјааПЈЖМЪЧБОШЫЪЙгУ,ВЛЛсГіЯжЖрШЫЙВгУвЛеХвјааПЈЕФЧщПі,ФЧЮЊЪВУДЛЙвЊЗХвјааПЈЪ§ОнФи?етвЊПДдѕУДЗХ,ЮвУЧдквдЭљЕФвЕЮёжаЗЂЯжСЫвдетбљвЛИіЭХЛяЦлеЉАИР§,ЭХЛяжаЕФМИШЫЭЌЪБдкЭЌвЛвјааИїздаТАьСЫвјааПЈгУгкДћПюЗЂЗХ,етОЭЕМжТетМИШЫЩъЧыЪБЕФвјааПЈКХЪЧСЌКХЕФЁЃШчЙћЮвУЧНЋвјааПЈФЉМИЮЛШЅЕєжЎКѓдйЗХЕНжЊЪЖЭМЦзРя,етжжвьГЃвјааПЈОлМЏЬиеїОЭФмЯдЯждкЭМЦзжаСЫЁЃ
- ЩшБИРрЪ§Он:жївЊАќРЈзЂВсЩъЧыЩшБИКЭгУПюЩшБИСНРр,ЕБШЛвВПЩвдНјвЛВНЯИЛЏЕНЩъЧыУПИіЛЗНк,АќРЈзЂВсЪзвГЩшБИЁЂШЫСГЪЖБ№ЩшБИЁЂЬсНЛЩъЧывГЩшБИЕШЕШЁЃЩъЧыШЫЙВгУЩшБИЪЧЭХЛяЦлеЉЕФвЛжжЕфаЭЬиеї,ЫљвдЪЧЗРЗЖЦлеЉвЊЙизЂЕФЪЎЗжживЊЕФвЛИіЮЌЖШЁЃ
- ЕЅЮЛРрЪ§Он:АќРЈЩъЧыЪБЬюаДЕЅЮЛЁЂХфХМЕЅЮЛЁЂЙЋЛ§Н№НЩФЩЕЅЮЛЁЂШЫааБЈИцжаНќЦкдјШЮжАЕФЕЅЮЛЕШЕШ,ЕЅЮЛРрЪ§ОнЫфШЛАќКЌживЊЕФЙиСЊаХЯЂ,ЕЋзлКЯПМСПвВПЩвдВЛЗХ,жївЊЪЧетбљСНИідвђ,вЛЪЧФкШнЖрЮЊЪжаД,ИёЪНЛьТв,ЖдЦыФбЖШКмДѓ;ЖўЪЧЩъЧыПЭЛЇдкЕЅЮЛЩЯОлМЏКмЖрВЛЪЧвьГЃ,БШШчПЭЛЇОРэЕНвЛИіДѓЦѓвЕеЙвЕ,вЛЖЮЪБМфИуЖЈЪЎМИЁЂМИЪЎИіПЭЛЇвВКме§ГЃЁЃ
- ЮЛжУРрЪ§Он:АќРЈЩъЧыЪБЕФGPSДђЕуЮЛжУЁЂгУПюЪБЕФДђЕуЮЛжУЁЂЕЅЮЛЕижЗЮЛжУЁЂМвЭЅЕижЗЮЛжУЕШЕШЁЃвЛАуЮвУЧЛсНЋИїжжЮЛжУзЊЛЏЮЊЭЌвЛзјБъЯЕЯТЕФОЮГЖШ,ВЂЪЙгУgeohashЫуЗЈНЋОЮГЖШзЊЛЏЮЊЕиРэЭјИёКѓдкЗХШыЭМЦз,вЛАуЕФЭјИёДѓаЁЮЊАйУзГЫвдАйУзСПМЖ,ЕБШЛвВвЊИљОнЪ§ОнОЋЖШКЭвЕЮёашвЊРДШЗЖЈЁЃ
- WIFIЪ§Он:АќРЈЩъЧыЁЂгУПюЛђИїИіЛЗНкТёЕуШЁЕНЕФWIFIаХЯЂ,ПЩвдНЋWIFIЕФbssidзіжїМќЗХШыЭМЦзЁЃ
- IPЪ§Он:IPЪ§ОнЪЧЗёПЩгУШдашЕїба,вЛЪЧЕижЗПЩвдздгЩХфжУ,ЖўЪЧгУСїСПКЭгУWIFIЛсЗЂЩњIPБфЖЏвВВЛФмЫЕУїЪВУД,Ш§ЪЧжЎЧАЕїбаЙ§вЛаЉЙВIPЕФПЭЛЇАИР§,ЗЂЯжВЂУЛгаЪЕМЪЙиСЊЁЃЫљвдIPПЩгУгыЗёгаД§ПМСПЁЃ
- ЦфЫќЛЙАќРЈгЪЯфЕижЗЪ§ОнЕШЁЃ
живЊЪєадЪ§ОнжївЊАќРЈ:
- ЩэЗнаХЯЂМАжїМќ:АќРЈЩэЗнжЄКХЁЂаеУћЁЂПЭЛЇЩъЧыКХЁЂгУПюКХЕШЕШЁЃгУгкЮвУЧЖЈЮЛЁЂВщбЏУПИіПЭЛЇЁЃ
- ЪБМфаХЯЂ:ЗЧГЃживЊ!!жївЊАќРЈЩъЧыЪБМфЁЂгУПюЪБМфЁЃКѓЦкашвЊЖдЭМЦзМАЙиСЊБфСПНјааЛиЫнОЭЪЧвЊвРРЕетаЉЪБМфаХЯЂЁЃ
- ЬиеїЦЋКУаХЯЂ:БШШчФъСфЁЂадБ№ЁЂжАвЕЁЂЪеШыЁЂАЎКУЕШИїжжЛЯёБъЧЉЕШЕШЁЃПЩгУгкПЬЛећИіЭХДиЕФЪєадЬиеї,БШШчвЛИіЭХДиОлМЏЕФМИИіШЫЖМгаЮчвЙЛюдОЁЂЭјТчгЮЯЗЕФЬиеї,ФЧЪЧВЛЪЧжЕЕУЮвУЧЬиБ№ЙизЂвЛЯТФиЁЃ
- гтЦкРраХЯЂ:АќРЈгтЦкЬьЪ§ЁЂгтЦкБЪЪ§ЁЂЕБЧАЪЧЗёгтЦкЕШЕШЁЃЪЧЮвУЧЖЈадОлМЏЭХДиаджЪЕФживЊЮЌЖШЁЃ
- ЩъЧызДЬЌМАдвђ:АќРЈЭЈЙ§ЁЂЗХЦњЁЂОмОјЕШзДЬЌвдМАОмОјдвђ,БШШчЦлеЉОмОјЁЂЖрЭЗОмОјЁЂаХгУЦРЗжОмОјЕШЕШ,вВЪЧПЬЛЭХДиаджЪЕФживЊЮЌЖШЁЃ
- КкЁЂЛвУћЕЅаХЯЂ:АќРЈаХгУКкУћЕЅЁЂгЊЯњКкУћЕЅЁЂЦлеЉКкУћЕЅЕШЕШ,ЮЌЖШАќРЈЪжЛњКХЁЂЩэЗнжЄЁЂЩшБИ,ЩѕжСWIFIЁЂЮЛжУЖМПЩвдЁЃКѓЦквВПЩвдИљОнжЊЪЖЭМЦзЗЂЯжвьГЃЭХДиШЅИќаТКкУћЕЅаХЯЂЁЃ
2ЁЂШчКЮЩшМЦжЊЪЖЭМЦзНсЙЙ
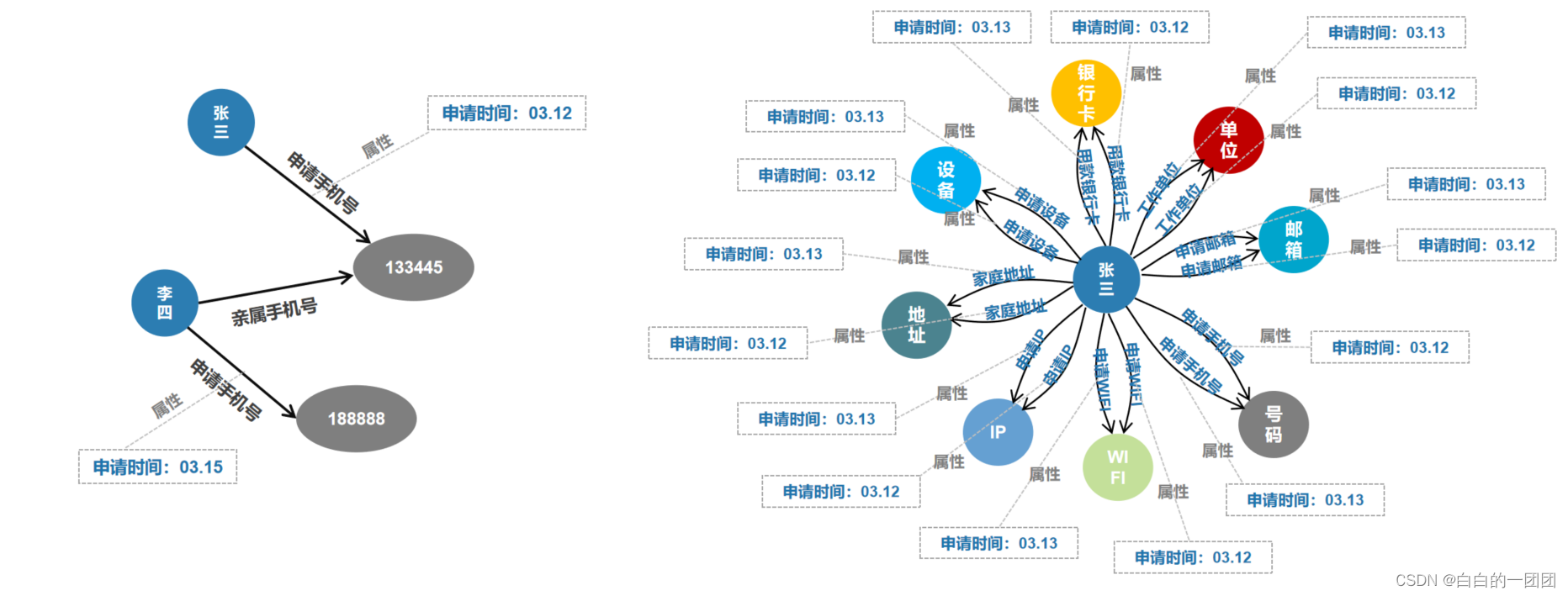
2.1 вўадЩъЧыНкЕуНсЙЙ
ЭМЦзШ§вЊЫиАќРЈ:НкЕуЁЂБпКЭЪєад,ЫљвдЩшМЦжЊЪЖЭМЦзНсЙЙОЭЪЧШЗЖЈШ§ИіЮЪЬт:ФФаЉЪ§ОнзіНкЕуЁЂЩшМЦФФаЉЙиСЊБпЁЂФФаЉЪ§ОнзіЪєадЗХЕНФФаЉЮЛжУЩЯЁЃЛљБОПЩвдзёбетбљвЛИіддђ:ЛсВњЩњЙиСЊЙиЯЕЕФЛљБОЪЕЬхзіНкЕу,ЗЂЩњЕФЖЏзїзїЮЊЙиСЊБп,ВЙГфаХЯЂзіЪєадЁЃБШШчеХШ§гУ133445ЕФЪжЛњКХдк3дТ12ШеЬсНЛСЫвЛБЪЩъЧы,РюЫФгУ188888ЕФЪжЛњдк3дТ15ШеНјааСЫЩъЧы,ЬюаДЕФЧзЪєЪжЛњКХЮЊ133445ЁЃЮЪЬтвЛ,НкЕуЩшжУ:етРяеХШ§ЁЂРюЫФЁЂЩъЧыЪжЛњКХЁЂЧзЪєЪжЛњКХЖМЪЧЛљБОЪЕЬх,ПЩвдЩшМЦЮЊНкЕу;ЮЪЬтЖў,БпЩшжУ:ЪЙгУФГФГЪжЛњКХЩъЧы,ЬюаДЧзЪєЪжЛњКХЮЊФГФГЪЧСНИіЖЏзї,ПЩвдЩшМЦЮЊБп,ЮЪЬтШ§,ЪєадЩшжУ:ЩъЧыЪБМфЪЧВЙГфаХЯЂ,ПЩвдзїЮЊЪєад,ЪєадЗХЕНФФРяФи,етРяНЈвщЗХЕНЩъЧыЪжЛњКХЕФБпЩЯУц,вђЮЊШчЙћЗХЕНПЭЛЇНкЕуЩЯ,МйШчетИіПЭЛЇЖрДЮгУВЛЭЌЪжЛњКХЩъЧыОЭШнвзВњЩњЛьЯ§,гЩДЫЮвУЧОЭПЩвдЕУЕНЯТЭМзѓБпетбљвЛИіМђЕЅЕФЭМЦзНсЙЙЁЃвРееетбљЕФТпМ,ДњШыЫљгаЪ§Он,ЮвУЧОЭФмЕУЕНЛљБОНсЙЙШчЯТЭМгвБпЫљЪОЕФжЊЪЖЭМЦзЁЃетжжНсЙЙЕФЭМЦзИќЧПЕїЕФЪЧПЭЛЇЁЊЁЊЙиСЊНкЕуЁЊЁЊПЭЛЇетжжЙиСЊЙиЯЕЕФМђНрГЪЯжЁЃЖдгкПЭЛЇЕФИїжжЩъЧыЖЏзїЖМЭЈЙ§діМгБпЙиЯЕРДБэДя,ШчЙћПЭЛЇЖрДЮЩъЧы,ОЭЛсШчЭМжаЫљЪО,ЪЙЕУУПИіНкЕуЖджЎМфЕФЙиСЊБпБфЕУЗзЗБИДдг,ЖјЧвЬѕЙиСЊБпЩЯУцЖМгІИУДјзХЪБМфЪєад,вдЖдЖрДЮЩъЧыНјааЧјЗжЁЃ
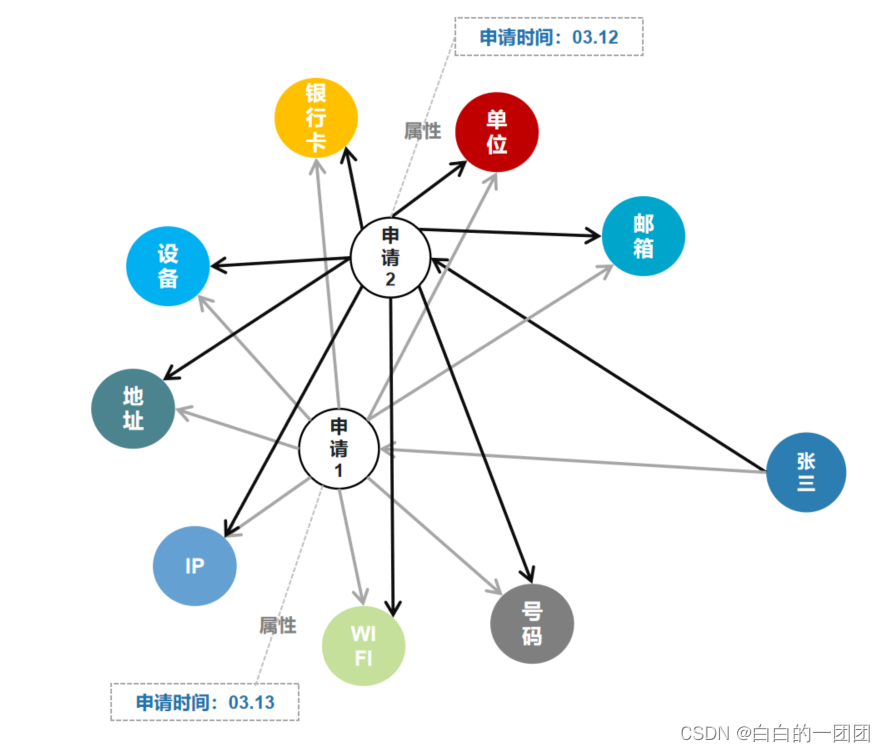
2.2 ЯдадЩъЧыНкЕуНсЙЙ
ЯывЊВЛАбНкЕуЖджЎМфЕФЙиСЊБпИуЕУетУДИДдг,ЖјЧвЦкЭћНЋПЭЛЇЕФЩъЧыЖЏзїБэЯжЕУИќЧхГў,ЮвУЧЛЙгаЕкЖўжжНсЙЙЩшМЦЗНАИ,МДАбПЭЛЇЕФУПДЮЩъЧыЖМгУвЛИіЯдадЕФНкЕуБэЪОГіРД,етжжНсЙЙПЩвдГЦЮЊЯдадЩъЧыНкЕуНсЙЙЁЃАДееетжжНсЙЙНЋЩЯУцЕФжЊЪЖЭМЦзжиЙЙОЭЕУЕНСЫШчЯТЭМЫљЪОЕФНсЙЙЁЃетжжНсЙЙЯТ,НкЕуЖдЕФБпЙиЯЕОЭМђЛЏСЫКмЖр,ЯёЪЧЩъЧыЪБМфЁЂгтЦкзДПіЕШЪєадЮвУЧОЭЖМПЩвдИНМгдкЩъЧыНкЕуЩЯУц,ФмИќЧхЮњЕиПДЕНПЭЛЇСНДЮЩъЧыжЎМфЕФВювьЁЃ
2.3 СНжжжЊЪЖЭМЦзНсЙЙЕФЬиЕуЖдБШ
СНжжЭМЦзНсЙЙИїгагХЪЦ,ЮвУЧЭЈЙ§вдЯТСНИіЗНУцЖдБШвЛЯТЫћУЧИїздЕФЬиад:
вЛЪЧЦѕКЯВЛЭЌЕФвЕЮёГЁОАЁЃгааЉаХДћвЕЮёФЃЪННЯЮЊМђЕЅ,УЛгабЛЗЖюЖШ,ЕЅДЮЪкаХ,ЕЅДЮгУПю,ЪкаХЩъЧыЁЂгУПюЩъЧыВЛзіУїЯдЧјЗжЁЃетбљЕФвЕЮёГЁОАОЭИќЪЪКЯгквўадЩъЧыНсЙЙЕФЙЙНЈ;ЖјгааЉвЕЮёФЃЪНЩдЮЂИДдгвЛаЉ,ЩшжУбЛЗЖюЖШ,вЛДЮЪкаХ,КѓајПЩЖрДЮЩъЧыгУПю,етОЭЕМжТПЭЛЇЕФЩъЧыНЯЮЊИДдг,вЊЧјЗжЪкаХЩъЧыКЭгУПюЩъЧы,ШчЙћдйМгжЎЖрЧўЕР,ЖрВњЦЗЩъЧы,ПЭЛЇЕФЩъЧыааЮЊЕФИДдгЖШОЭИќЩѕ,етИіЪБКђ,гУЯдадЩъЧыНкЕуНсЙЙРДЙЙНЈжЊЪЖЭМЦзОЭФмНЯЮЊЧхГўЕиБэЯжГіПЭЛЇЕФЖрДЮЩъЧыааЮЊ;ЦфДЮ,гаСЫЩъЧыНкЕу,ОЭПЩвдНЋКмЖрЪєаджЛЙщФЩЕНЩъЧыНкЕуЩЯ,БШШчЩъЧыЪБМф,ДгЖјНЋБпЩЯЪєадДѓДѓМђЛЏ,зюКѓ,ЩъЧыНкЕуПЩвдИќОпЬхЕиГЪЯжУПвЛДЮЩъЧыЕФВЛЭЌЪєадзДЬЌ,БШШчУПДЮЩъЧыЕФгтЦкзДЬЌЁЂгУПюБЪЪ§ЕШЕШЁЃ
ЖўЪЧМЦЫуЙиСЊЖШЪ§ИДдгГЬЖШВЛЭЌЁЃЖдгквўадЩъЧыНкЕуНсЙЙ,ДгвЛИіПЭЛЇЙиСЊЕНСэвЛИіПЭЛЇзюЖЬжЛашвЊСНЖШ,МДПЭЛЇЁЊЁЊЙиСЊНкЕуЁЊЁЊПЭЛЇ;ЖјЖдгкЯдадЩъЧыНкЕуНсЙЙ,ДгвЛИіПЭЛЇЙиСЊЕНСэвЛИіПЭЛЇзюЩйашвЊЫФЖШ,МДПЭЛЇЁЊЁЊЩъЧыЁЊЁЊЙиСЊНкЕуЁЊЁЊЩъЧыЁЊЁЊПЭЛЇ,етОЭЕМжТдкзіЭММЦЫуЕФЪБКђСНжжНсЙЙгаЫљВювьЁЃБШШчМЦЫувЛИіПЭЛЇжБНгЙиСЊПЭЛЇЪ§ЁЂМфНгЙиСЊПЭЛЇЪ§,дквўадЩъЧыНкЕуНсЙЙжажЛашвЊжДаа3ЖШКЭ5ЖШЕФМЦЫу;ЖјдкЯдадЩъЧыНкЕуНсЙЙжа,дђдіМгЕН4ЖШКЭ8ЖШЕФМЦЫу,етвВЛсжБНгЕМжТМЦЫузЪдДКЭМЦЫуЪБМфЕФВювьЁЃ
зюКѓ,ЮвУЧвдЯдадЩъЧыНкЕуНсЙЙЮЊР§,АбвЛИіНЯЮЊЭъећЕФЭМЦзМмЙЙзмНсШчЯТ:
зюКѓ,ЭМЦзЗХФФаЉЪ§Он,ШчКЮМмЙЙвВвЊДгИќИпЕФВуУцПМТЧЁЃЗХблећИіЪ§ОнВњЦЗЬхЯЕ,ЭМЦзвВНіНіЪЧЦфжаЕФвЛЛЗ,ЫљвдКмЖрвЕЮёаХЯЂгаУЛгаБивЊЖМЗХЕНЭМЦзжажЕЕУЩЬШЖ,ЭМЦзЩшМЦЕУДѓЖјШЋ,ОЭЛсвЛЖЈГЬЖШЩЯЭЯРлЦфдЫЫуКЭЪЙгУЫйЖШЁЃЭМЦзЕФЬиЕуКЭгХЪЦдкгкОлМЏЙиЯЕЕФЗЂЯжКЭЦлеЉЗчЯеЕФЗРПи,ЦфЫќвЕЮёЮЪЬтЭъШЋПЩвдЗХЕНЦфЫќВњЦЗЬхЯЕжаШЅНтОіЁЃзюжеЕФФПЕФвВЪЧЯывЊШУЭМЦзКЭећИіЪ§ОнЬхЯЕжаЕФЦфЫќВњЦЗаЮГЩСМадЛЅВЙ,ЖјЗЧЯрЛЅШпгрЁЃ
ЖўЁЂжЊЪЖЭМЦзЕФгХЪЦ
жЊЪЖЭМЦзПЩвдБЛПДзіЪЧвЛжжЪ§ОнДцДЂЗНЪН,ШчЙћНіДгЪ§ОнДцДЂЕФНЧЖШРДПДД§Ыќ,ФЧЯрНЯгкДЋЭГЕФЪ§ОнПт,ЫќВЂУЛгаДјРДШЮКЮаТЕФаХЯЂ,жЛЪЧНЋдгаЕФаХЯЂЛЛСЫвЛжжИќВржиЙиЯЕЕФЗНЪННјааДцДЂЁЃе§ЪЧЛљгкетбљЕФдвђ,ЮвУЧдкЦєЖЏжЊЪЖЭМЦзЯюФПЕФЪБКђ,ЭљЭљЛсБЛжЪЮЪ,ДюНЈжЊЪЖЭМЦзЕФБивЊаддкФФРя,вЕЮёжаОПОЙгіЕНСЫЪВУДбљЕФРЇОГ,ЪЧДЋЭГЪ§ОнПтЮоЗЈНтОіЖјвЛЖЈвЊгУЕНжЊЪЖЭМЦзЕФФи?ЮвУЧОЭвдвЛИіЪЕМЪЕФвЕЮёАИР§,ЖдетИіЮЪЬтНјаавЛИіМђЕЅВћЪіЁЃ
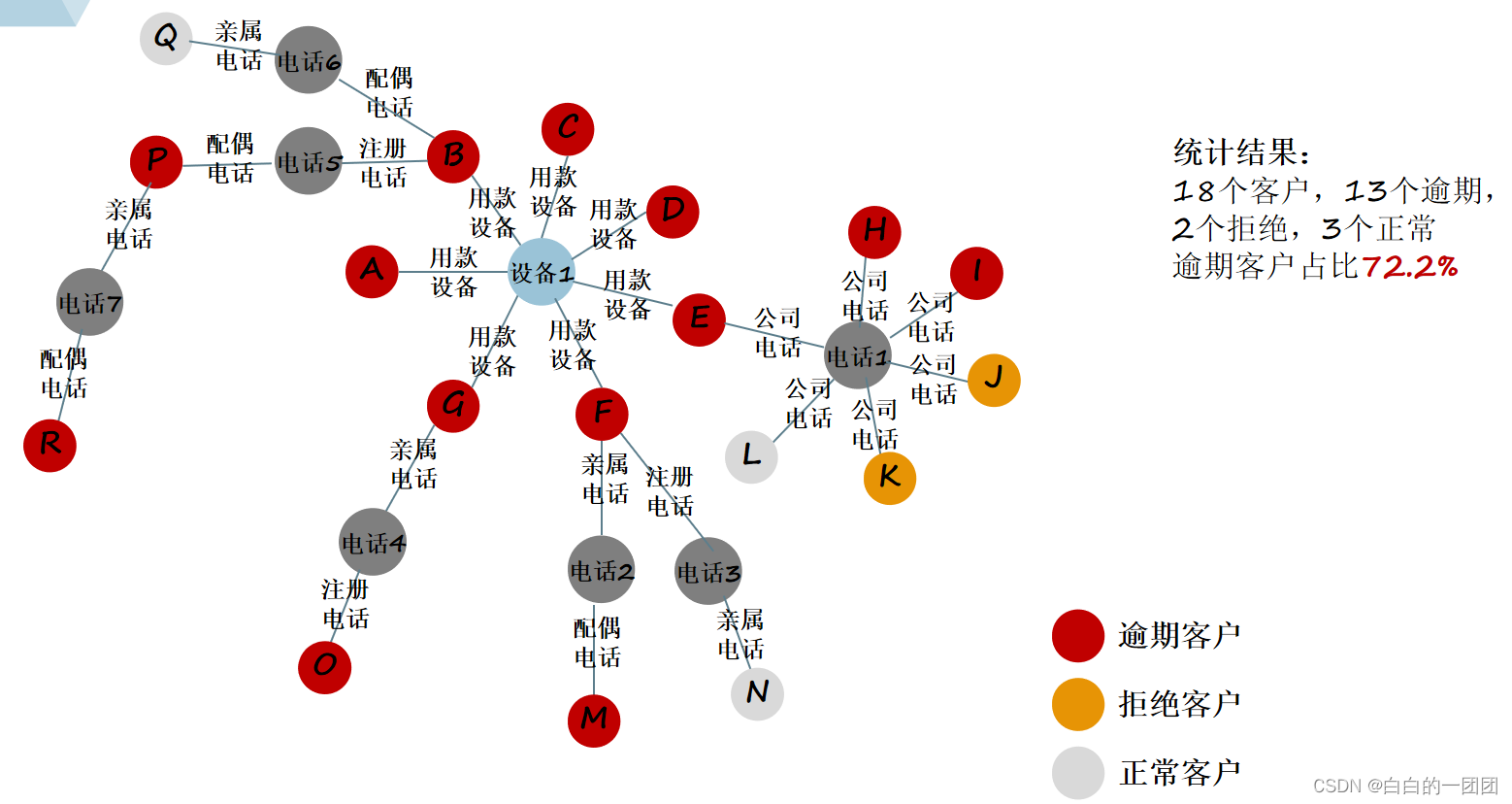
ЩЯЭМеЙЪОЕФЪЧЮвУЧдкецЪЕаХДћвЕЮёжагіЕНЕФвЛИіПЩвЩЭХЛяАИР§ЁЃ18ИіПЭЛЇжЎМфЭЈЙ§гУПюЩшБИЁЂзЂВсЕчЛАЁЂЙЋЫОЕчЛАЁЂЧзЪєЕчЛАЁЂХфХМЕчЛАЕШЙиЯЕгазХДэзлИДдгЕФСЌНг,аЮГЩвЛИіЙиЯЕНєУмЕФаЁЭХЬхЁЃ18ИіПЭЛЇжЎжага13ИіПЭЛЇНшПюКѓЗЂЩњСЫгтЦк,ећИіаЁЭХЬхЕФПЭЛЇгтЦкТЪДяЕНСЫ72.2%ЁЃвЕЮёжа,МАЪБЁЂШЋУцЕиЗЂЯжетбљаджЪвьГЃЕФЭХДиЖдгкНЕЕЭећИіаХДћвЕЮёЦлеЉТЪЁЂБЃеЯзЪВњжЪСПЖМгазХживЊЕФвтвхЁЃФЧНіЪЙгУДЋЭГЪ§ОнПт,ФмВЛФмМАЪБЁЂгааЇЕиЗЂЯжВЂзшРЙетбљЕФЭХДиФи?
1ЁЂЬсИпОлМЏБфСПМЦЫуаЇТЪ
ЪзЯШ,НіЪЙгУДЋЭГЪ§ОнПт,ЮвУЧПЩвдгУвЛжжИќМђЛЏЕФЗНЪНРДЗЂЯжПЭЛЇвьГЃОлМЏааЮЊ,МДПЊЗЂОлМЏадБфСП,БШШчЭЌЩшБИВЛЭЌЩъЧыПЭЛЇЪ§,ЭЌЪжЛњКХВЛЭЌЩъЧыПЭЛЇЪ§ЕШЕШЁЃЖдгкетбљЙиЯЕШЗЖЈЧвЙиСЊЩюЖШНіЮЊвЛЖШЕФОлМЏадБфСП,ЪЙгУДЋЭГЪ§ОнПтПЊЗЂФбЖШВЛДѓ,КмШнвзЪЕЯжЁЃЕЋШчЙћЮвУЧЯывЊЛёЕУИќЩюЖШЕФЙиСЊЙиЯЕ,ФЧДЋЭГЪ§ОнПтЪЕЯжЦ№РДОЭгааЉТщЗГСЫ,БШШчЮвУЧвдЩЯЭМжаЕФOПЭЛЇЮЊР§,ЯывЊЛёШЁДгOЕФзЂВсЪжЛњКХГіЗЂ,ЖўЖШЙиСЊЕФгтЦкПЭЛЇЪ§,ФЧЪЙгУДЋЭГЪ§ОнПтРДМЦЫу,Й§ГЬОЭШчЯТЭМЫљЪО:

ЪзЯШ,ДгПЭЛЇOГіЗЂ,ЮвУЧашвЊКЭШЋСПЩъЧыаХЯЂБэНјааСљДЮЙиСЊЦЅХфдЫЫу,УПДЮЗжБ№ЪЙгУЩъЧыБэжаЕФзЂВсЪжЛњКХЁЂЧзЪєЪжЛњКХЁЂХфХМЪжЛњКХЁЂНєМБСЊЯЕШЫЪжЛњКХЁЂЙЋЫОЕчЛАЁЂжБЯЕЧзЪєЕчЛАКЭПЭЛЇOЕФзЂВсЪжЛњКХНјааЦЅХфЁЃдкЭъГЩ6ДЮШЋСПЩЈУшЦЅХфКѓ,ЮвУЧВХФмЧюОЁПЭЛЇOЩъЧыЪжЛњКХЕФЙВгУЙиЯЕ,ВХФмЗЂОђГіЫљгадкЪжЛњКХЙиЯЕЩЯКЭOгаЙиСЊЕФПЭЛЇ(дкДЫАИР§жаМДПЭЛЇG),жСДЫ,ЮвУЧЭъГЩСЫДгПЭЛЇOГіЗЂЕФвЛЖШЙиСЊЙиЯЕЕФЭкОђ,ЕкЖўВН,ЖўЖШЙиЯЕЭкОђ,ЮвУЧашвЊДгПЭЛЇGГіЗЂ,БщРњЫљгаЙиСЊЙиЯЕ,евЕНгыПЭЛЇGвЛЖШЙиСЊЕФПЭЛЇ,ЮЊДЫ,ЮвУЧашвЊгУПЭЛЇGЕФзЂВсЕчЛАКЭЩъЧыБэЕФзЂВсЁЂЧзЪєЁЂХфХМЁЂНєМБСЊЯЕШЫЁЕчЛАНјааЙиСЊЦЅХф,дйгУGЕФЧзЪєЪжЛњКХКЭЩъЧыБэЕФзЂВсЁЂЧзЪєЁЂХфХМЁЂНєМБСЊЯЕШЫЁЕчЛАНјааЙиСЊЦЅХф,вдДЫРрЭЦ,дйгУПЭЛЇGЕФХфХМЪжЛњКХЁЂНєМБСЊЯЕШЫЪжЛњКХЁЂЙЋЫОЁЕчЛАЗжБ№НјааБщРњ,дкЭъГЩ36ДЮБщРњЦЅХфКѓ,ПЭЛЇGЪжЛњЙиЯЕдђОЭЧюОЁЭъСЫЁЃЕЋЛЙУЛгаНсЪј,НгЯТРД,ЮвУЧЛЙашвЊЖдПЭЛЇGЕФзЂВсЕЅЮЛЁЂЙЋЛ§Н№ЕЅЮЛЁЂХфХМЕЅЮЛЁЂИїжжЕижЗЁЂгЪЯфЕШЙиЯЕНјааБщРњЙиСЊЦЅХф,ШЛКѓЕНТёЕуаХЯЂБэжа,ЖдПЭЛЇGЕФзЂВсЁЂЕЧТМЁЂгУПюЕШЩшБИ,WIFIЁЂIPЁЂGPSЕШЙиЯЕНјааБщРњЦЅХф,ЕБетаЉЙиЯЕЖМБщРњЭъГЩКѓ,ЮвУЧВХЭъШЋЧюОЁСЫДгПЭЛЇGГіЗЂЕФвЛЖШЙиСЊЙиЯЕ,вВОЭЭъГЩСЫДгПЭЛЇOзЂВсЪжЛњКХГіЗЂЕФЖўЖШЙиСЊЙиЯЕ,жСДЫ,ЮвУЧвВОЭевЕНСЫПЭЛЇAЁЂBЁЂCЁЂDЁЂEЁЂF,ШЛКѓХаЖЯетаЉПЭЛЇжагаЖрЩйЪЧгтЦкПЭЛЇ,вВОЭЪЕЯжСЫЁАЭЈЙ§зЂВсЪжЛњКХЖўЖШЙиСЊЕФгтЦкПЭЛЇЪ§ЁБетбљвЛИіБфСПЕФдЫЫуЁЃгЩДЫ,ЮвУЧвВОЭПЩМћвЛАп,дкНјааетбљЖўЖШЙиСЊЙиЯЕБфСПдЫЫуЪБ,ЪЙгУДЋЭГЪ§ОнПтЪЧЖрУДЕФШпГЄКЭЗБИД,ЖдМЦЫузЪдДКЭЪБМфЪЧЖрУДДѓЕФРЫЗбЁЃШчЙћЮвУЧДюНЈСЫжЊЪЖЭМЦзетбљвЛжжЛљгкЙиЯЕЕФЪ§ОнДцДЂПт,МЦЫуетбљЕФЖўЖШЙиСЊБфСПОЭЛсЗЧГЃМђЕЅЪЁСІ,МђЕЅРДЫЕ,МЦЫуЪБШчЭМжаЫљЪО,ПЭЛЇOЩьеЙГіРДЖрЩйЙиСЊБп,дкдЫЫужаОЭжЛашвЊНјааЖрЩйДЮЛљДЁдЫЫу,ЯрЖдДЋЭГЪ§ОнПтРДНВ,аЇТЪПЩЮНЪЧИяУќадЕФЬсЩ§ЁЃ
2ЁЂЪЕЯжвьГЃЭХДиЕФУєНнЪЖБ№
ГЯШчаЬеьЦЦАИвЛбљ,ЕБЮвУЧЫјЖЈвЛИіЯгвЩШЫжЎКѓ,ЮвУЧЯЃЭћЭЈЙ§етИіЯгвЩШЫМАЙиСЊЯпЫї,ФмЙЛАбЦфБГКѓЕФећИіЗИзяЭХЛяШЋВПООГіРДЁЃЭЌбљдкаХДћвЕЮёжа,ЮвУЧвВЯЃЭћФмЙЛПДЕНУПвЛИівьГЃЩъЧыПЭЛЇБГКѓНєУмЙиСЊЕФШКЬх,МАећИіШКЬхЕФЬиеїаджЪЁЃвдДЫАИЮЊР§,ШчЙћЮвУЧЯЃЭћевЕНКЭПЭЛЇIЯрЙиСЊЕФећИіПЭЛЇШК,ЪЙгУДЋЭГЪ§ОнПтвЊШчКЮЪЕЯжФи?

ШчЭМжаЫљЪО,ЪзЯШвЊДгПЭЛЇIГіЗЂ,евЕНгыжЎвЛЖШЙиСЊЕФЫљгаПЭЛЇ,етОЭашвЊШчЧАЫљЪіНЋећИіЩъЧыБэКЭТёЕуБэгУЫљгаЯрЙиЙиЯЕНјааБщРњ,ВХФмЧюОЁевЕН(ДЫР§жаЕФHЁЂJЁЂKЁЂLЁЂEПЭЛЇ),ШЛКѓдйЖдУПвЛИівЛЖШЙиСЊЕФПЭЛЇ,ЭЌбљНјааЫљгаЯрЙиЙиЯЕЕФБщРњЦЅХф,ВХФмЗЂЯжгыПЭЛЇIЖўЖШЙиСЊЕФЫљгаЩъЧыПЭЛЇ(ДЫР§жаЕФAЁЂBЁЂCЁЂDЁЂFЁЂG),ШчДЫбЛЗЭљИДЯТШЅ,жБЕНЫљгаПЭЛЇЖМБЛевЕНЁЃЕЋдкДЋЭГЪ§ОнПтжа,ШчКЮШЗЖЈетбљЕФБпНчЬѕМўФи?МДЮвУЧдѕУДжЊЕРвЊНјааМИДЮБщРњЦЅХфВХФмАбКЭIЯрЙиЕФПЭЛЇЖМевГіРДФи?етдкДЋЭГЪ§ОнПтжаЪЧКмФбШЗЖЈЛђКмФбЪЕЯжЕФЁЃЖјдкжЊЪЖЭМЦзЪ§ОнПтжа,ЛљгкЙиЯЕевЕННєУмСЌНгЕФЭХДиЪЧКмМђЕЅЕФЪТЧщ,ВЛНідЫЫуСПаЁ,ЪЕЯжвВМЋЮЊЗНБу,вЛаЉПЊдДЦНЬЈШчneo4jжБНгЬсЙЉСЫЭъећЗтзАЕФЭМЫуЗЈРДЪЕЯж,ЗЂЯжетбљвЛИіЭХДи,дЫЫуЪБМфжЛгаУыМЖЁЃ
3ЁЂЮЊЙиСЊЙиЯЕЕФЩюЖШЭкОђЬсЙЉЦНЬЈ
- ЩчЧјЗЂЯж:гаЪБ,ЛљгкЫљгаЙиСЊЙиЯЕЭкОђГіЕФЭХДиЖдЮвУЧЖјбдгааЉШпгр,вЛаЉЮвУЧПДРДЙиЯЕВЂВЛНєУмЕФСЌНгвВБЛСЌДјдкРяУцЁЃФЧГ§СЫвЕЮёЩЯздЖЈвхНєУмЙиЯЕЭт,гаУЛгавЛжжММЪѕЪжЖЮ,ЭЈЙ§ПЦбЇМЦЫуевЕНеце§НєУмСЌНгЕФЭХДиФи?етжжММЪѕЪжЖЮОЭЪЧЩчЧјЗЂЯжЫуЗЈ,БШШчlouvainЫуЗЈЁЂlabel propagationЫуЗЈЕШЕШ,етаЉЫуЗЈПМТЧБпЕФШЈжи,ЭЈЙ§бЛЗЕќДњФмЙЛевЕНеце§НєУмОлМЏЕФЭХДиЁЃ
- жааФЖШ:вЕЮёжаЭљЭљгаЭЈЙ§жаНщНјааЭХЛяЦлеЉЕФАИР§,дквЛИіЮЌЖШШЋУцЕФжЊЪЖЭМЦзжа,жаНщдквЛИіЦлеЉЭХЛяжаЕФКЫаФЙиСЊЮЛжУОЭКмШнвзЭЙЯдГіЯж,ФЧгаУЛгавЛжжЫуЗЈФмАяЮвУЧХњСПЕи,ПьЫйЕиевЕНЫљгаЙмРэКЫаФНкЕу,вдБуЮвУЧЗЂЯжЭХЛяжаНщФи?ОЭПЩвдЪЙгУжааФЖШЫуЗЈРДЪЕЯж,БШШчpagerankЁЂarticle rankЫуЗЈЕШЕШЁЃ
- зюЖЬТЗОЖ:вЕЮёжаШчЙћЮвУЧЗЂЯжСНИіПЩвЩПЭЛЇ,ЯывЊбИЫйЖЈЮЛГіетСНИіПЩвЩПЭЛЇМфгаУЛгаЙиСЊЙиЯЕ,ШчЙћгаЖржжЙиСЊЗНЪН,ФЧЦфжазюНєУмЕФЙиЯЕ,МДСНИіНкЕуМфЕФзюЖЬЙиСЊТЗОЖЪЧЪВУДбљЕФ?етбљЕФашЧѓОЭПЩвдЪЙгУзюЖЬТЗОЖЫуЗЈРДЪЕЯжЁЃ
вдЩЯжжжжЖдПЭЛЇЙиСЊЙиЯЕЕФЩюЖШЭкОђЫуЗЈЖМашвЊЪзЯШЛљгкжЊЪЖЭМЦзетбљвЛИіЦНЬЈВХФмЪЕЯжЁЃЖјвЛЕЉгаСЫетбљвЛИіжЊЪЖЭМЦзЦНЬЈ,етаЉЫуЗЈЖМПЩвдЧсвзЪЕЯж,БШШчЮвУЧГЃгУЕФПЊдДЦНЬЈneo4jОЭЬсЙЉСЫећКЯетаЉЭММЦЫуЕФЫуЗЈАќgraph-data-scienceАќ,вдЩЯЫљгаЫуЗЈЖМИпЖШЗтзА,ЛљБОвЛОфгяОфНтОіЮЪЬт,етРяЗХЩЯЫуЗЈАќЕФПЊдДЭјжЗЙЉбЇЯАВщдФ:Neo4j Graph Data ScienceЁЃ
Ш§ЁЂжЊЪЖЭМЦзШчКЮгІгУМАГЃМћЮЪЬт
1ЁЂЭМЦзгІгУЗНЪН
жЊЪЖЭМЦздкаХДћЗчПивЕЮёжаЕФгІгУДѓЬхПЩвдЗжЮЊСНжжЗНЪН,ШчЯТЭМЫљЪО:

ЦфжагІгУЗНЪНвЛЖдЭМЦзЕФЪЕЪБадвЊЧѓВЛИп,МДБуЭМЦзАДT+1ЪБаЇИќаТ,вВВЛгАЯьетжжЕФгІгУЗНЪН,жЛЪЧЕБЬьЩъЧыЕФЭХАИПЭЛЇУЛЗЈЗРЗЖЁЃ
гІгУЗНЪНЖўПЩвдЫЕЪЧжЊЪЖЭМЦзЕФИпНзгУЗЈ,ЗРЗЖЭХАИЦлеЉМАЪБадИп,ЕЋвЊЧѓЭМЦзвЊФмзіЕНЪЕЪБИќаТКЭБфСПЕФЪЕЪБМЦЫуКЭЗДРЁЁЃетОЭвЊЧѓжЊЪЖЭМЦзЁЂОіВпв§ЧцЁЂЙиЯЕЪ§ОнПтШ§епжЎМфФмЙЛЪЕЪБЛЅЖЏ,ПьЫйЗДРЁ,етЖдММЪѕМмЙЙЕФФмСІвЊЧѓЛЙЪЧВЛЕЭЕФ,КмЖрЛњЙЙЖджЊЪЖЭМЦзЕФгІгУЖМФбвдДяЕНетжжГЬЖШЁЃ
2ЁЂжЊЪЖЭМЦзЛиЫнЮЪЬт
ЯывЊНЋЭМЦзжаМЦЫуГіЕФЭХДиБфСПЗХШыЕНДћЧАЗчПиФЃаЭжаНјааЪЕЪБОіВп,ОЭвЊЯШбЕСЗвЛИіДјгаЭМЦзБфСПЕФЗчПиФЃаЭ,етОЭвЊЧѓЮвУЧФмЙЛЖдЭМЦзРрБфСПНјааЛиЫн,МДУПИіПЭЛЇЕФЭМЦзРрБфСПгІИУЪЧИљОнЦфЩъЧыЪБЕуЕФЭМЦззДЬЌМЦЫуГіРДЕФ,ЖјВЛЪЧИљОнЕБЧАЭМЦззДЬЌШЅМЦЫу,ЮвУЧОйР§РДПД:
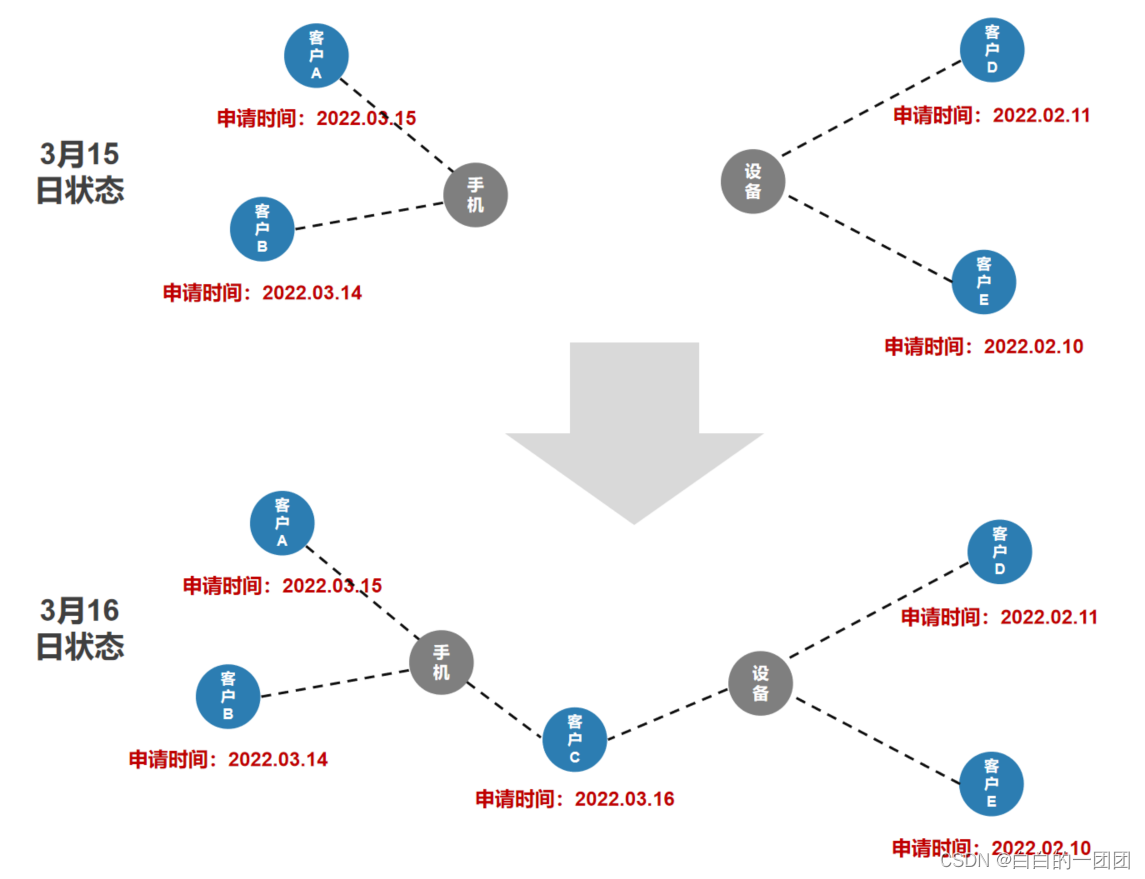
БШШч3дТ15Ше,AПЭЛЇКЭBПЭЛЇЭЈЙ§ЪжЛњКХЙиСЊЦ№РД,аЮГЩвЛИіаЁЭХДи,ЖјDПЭЛЇКЭEПЭЛЇЭЈЙ§ЩшБИЙиСЊЦ№РД,аЮГЩСэЭтвЛИіЭХДи,СНИіЭХДижЎМфВЂУЛгаШЮКЮЙиСЊЁЃДЫЪБ,ШчЙћЮвУЧвЊМЦЫуПЭЛЇAдкЩъЧыЪБПЬЫљдкЭХДиЕФПЭЛЇЪ§,ЮвУЧжЛашвЊвдПЭЛЇAЮЊЦ№Еу,жДааЩчЧјЗЂЯжЫуЗЈ,евЕНЫљгагыAЙиСЊЕФПЭЛЇ,дйЬоГ§етаЉЙиСЊПЭЛЇжаЩъЧыЪБМфдкAжЎКѓЕФПЭЛЇМДПЩ,етЪБКђКмШнвзМЦЫуГіAдкЩъЧыЪБПЬЫљдкЭХДиЕФПЭЛЇЪ§ЮЊ1(ВЛКЌздЩэ)ЁЃ
ЕЋЕБЕНСЫ3дТ16КХ,СэЭтвЛИіаТЩъЧыПЭЛЇCЕФГіЯжНЋжЎЧАСНИіВЛЯрЙиЕФЭХДиСЊЯЕЦ№РДСЫ,ШУAЁЂBЁЂCЁЂDЁЂEПЭЛЇОлМЏГЩСЫвЛИіДѓЭХДиЁЃДЫЪБ,ЮвУЧдйЯывЊЛиЫнПЭЛЇAдкЩъЧыЪБПЬЫљдкЭХДиЕФПЭЛЇЪ§,ФЧМђЕЅгІгУЩЯЪіЗНЗЈОЭгаЮЪЬтСЫ:ЪзЯШДгAГіЗЂжДааЩчЧјЗЂЯжЫуЗЈевДђЫљгаЙиСЊПЭЛЇBЁЂCЁЂDЁЂE,дйЬоГ§ЩъЧыЪБМфдкAжЎКѓЕФПЭЛЇC,ЕУЕНБфСПжЕБфЮЊСЫ3ЁЃУїЯдетИіЗНЗЈЕУЕНЕФБфСПжЕ3ЪЧДэЮѓЕФ,вђЮЊдкAЩъЧыЪБ,ЫћКЭПЭЛЇDЁЂEжЎМфЛЙУЛгаСЊЯЕЁЃЫљвдЯывЊОЋзМЛиЫнПЭЛЇAЩъЧыЪБПЬЕФЭМЦззДЬЌМАБфСПжЕ,РэТлЩЯашвЊДгПЭЛЇAГіЗЂ,ж№ВуЩЈУш,ЩЈУшЕНЩъЧыЪБМфдкAжЎЧАПЭЛЇ,ВХМЬајЯђЯТвЛВуЩЈУш,ЩЈУшЕНЩъЧыЪБМфдкAжЎКѓЕФПЭЛЇдђашвЊЧаЖЯИУПЭЛЇЭљЭтбгЩьЕФЫљгажЇТЗ,вРДЫЗНЗЈЧюОЁевЕНЫљгаЙиСЊНкЕу,ВХФмБЃжЄЛиЫнЕФзМШЗад,ЕЋетдкММЪѕЪЕЯжЩЯОЭвЊФбвЛаЉЁЃ
СэЭтвЛИіФбЕуЪЧгтЦкзДЬЌЕФЛиЫн,МйШчЮвУЧЯывЊМЦЫуПЭЛЇCЩъЧыЪБЁАЫљдкЭХДигтЦк30+ШЫЪ§еМБШЁБетбљЕФБфСП,ОЭашвЊЖдПЭЛЇAЁЂBЁЂDЁЂEдкПЭЛЇCЩъЧыЧАвЛЬьЕФгтЦкзДЬЌНјааЛиЙі,ШЛКѓХаЖЯЪЧЗёгтЦк30+ЁЃЕБШЛ,ШчЙћЮвУЧгаУПИігУПюПЭЛЇУПШеЕФгтЦкзДЬЌЧаЦЌЪ§Он,ФЧетИіЮЪЬтОЭПЩвдНтОі,ОЭЪЧЩдЮЂТщЗГаЉЁЃ
3ЁЂжЊЪЖЭМЦзЗРЗЖЭХЛяЦлеЉЕФМАЪБадЮЪЬт
ЫфШЛЫЕжЊЪЖЭМЦзЪЧЗРЗЖЭХЛяЦлеЉЕФвЛИіРћЦї,ЕЋвВзіВЛЕННЋЭХЛяЦлеЉЯћУ№дквЁРКРяЁЃБШШчМйЩшЮвУЧЗжЮіевЕНвЛИіЗЧГЃгааЇЕФЙцдђВпТд:ЭХДидк5аЁЪБФкГЩГЄЕН4ШЫвдЩЯ,дђЦлеЉЕФИХТЪГЌЙ§50%,МДБуЮвУЧдкЗчПижаЪЕЪБгІгУСЫетЬѕВпТд,вВВЛФмНЋЦлеЉЭХЛяжаЕФЧА3ИіРДЩъЧыЕФШЫЗРПиЯТРД,вђЮЊЧА3ИіПЭЛЇРДЩъЧыЪБЛЙВЛзувдДЅЗЂетЬѕВпТдЁЃЫљвд,жЊЪЖЭМЦзвВОпгаЦеБщЕФОжЯоад,ашвЊКЭЦфЫќЪ§зжЛЏЗчПиВњЦЗЯрХфКЯ,аЮГЩвЛИіЭъећЁЂСМадЕФЗчПиБеЛЗ,ВХФмОЁСПНЋЗчПиЗДЦлеЉзіЕНОЁЩЦОЁУРЁЃ