阅读理解本质是一个答案抽取任务,PaddleNLP对于各种预训练模型已经内置了对于下游任务-答案抽取的Fine-tune网络。
以下项目以BERT为例,介绍如何将预训练模型Fine-tune完成答案抽取任务。
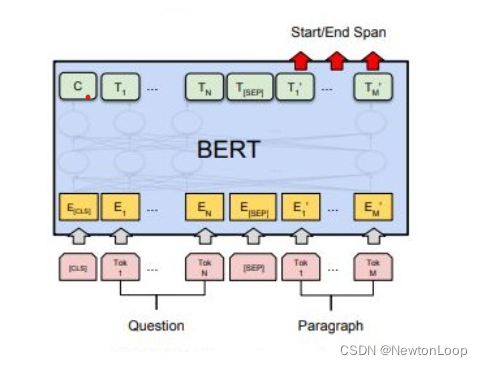
答案抽取任务的本质就是根据输入的问题和文章,预测答案在文章中的起始位置和结束位置。基于BERT的答案抽取原理如下图所示:
# 设置想要使用模型的名称
model = ppnlp.transformers.BertForQuestionAnswering.from_pretrained(MODEL_NAME)
模型配置
设置Fine-Tune优化策略
适用于ERNIE/BERT这类Transformer模型的学习率为warmup的动态学习率。
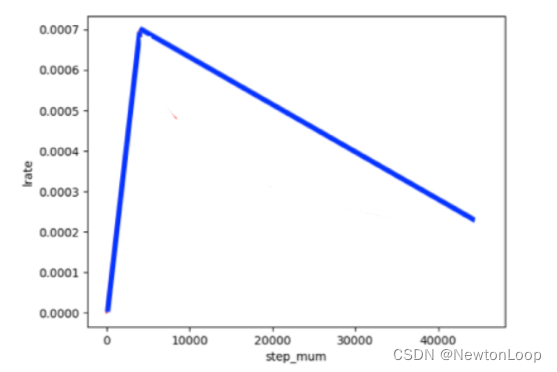
# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 1
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
设计loss function
由于BertForQuestionAnswering模型对将BertModel的sequence_output拆开成start_logits和end_logits进行输出,所以阅读理解任务的loss也由start_loss和end_loss组成,我们需要自己定义loss function。对于答案其实位置和结束位置的预测可以分别成两个分类任务。所以设计的loss function如下:
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForSQuAD, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y # both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False)
start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) / 2
return loss
这一部分未对参考模型进行修改
参考链接AI Studio----基于bert的模型的机器阅读理解