前言
ResNest被称为最强的resnet变体,而ResNest的主要设计思想就是考虑两个方面。一方面想利用Inception中多分支结构带来模型学习能力的提升。另一方面想利用SENet和SKNet中提出的通道注意力思想,使网络可以学习通道间的信息,使网络根据目标,有选择的去选择有重要性的通道内容。
下面的内容基于本人对搜索的一些资料和源代码的理解,有可能会有所偏差和理解不当。
一、回顾Resnet和Resnext
在学习Resnset之前,我觉得还是比较有必要回顾一下Resnet和Resnext中涉及的内容及其网络结构。方便后续讲解。
Resnet的Residual结构
Resnet的最大贡献在与其提出的残差结构有效的解决gradient vanish的问题,使网络的深度得以有效加深。
 ?
?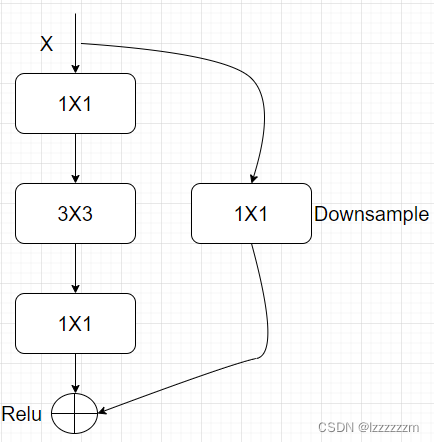
?其中比较经典的结构如上图,采用两头小中间大的结构,所以也被称为Bottelnet。这里其中的细节在与,在pytorch实现的resnet中,是在3X3的conv中来降低图片尺寸,因为如果在1x1的卷积核中降低图片尺寸,势必会导致信息的丢失。
而在Downsample的操作,目的是保证block和block连接时残差可以连接而使用的,而在原始的resnet中,这里是直接采用1X1去降图片尺寸的,而这也是会导致信息丢失的,所以后面就有Resnet-D的变种,主要是针对Downsample结构进行改进。
? ? ? ? ? ? ? ? ? ? ? ??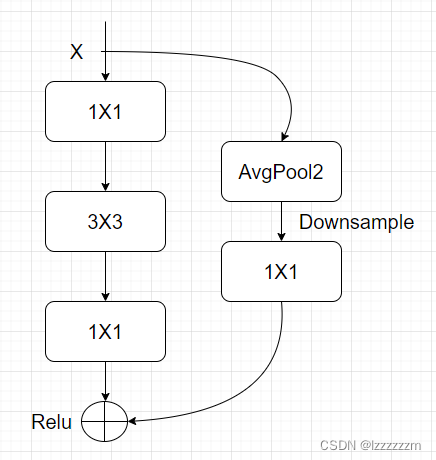
在Resnet-D中,采用全局平均池化的方式进行尺寸的减半操作,再经过1X1的卷积核去在维度上进行变换,这样就防止了信息丢失的问题,在后面Resnest也是使用这个downsample的方式。?
Resnext中的Multi-branch结构
Resnext和Resnet的实现上,可以完全共用一套代码,因为其就是把上面resnet中3X3的卷积结构,替换成了组卷积的形式。但其值得学习的地方在与,Resnext是利用了组卷积的性质和multi-branch结构等价来更加优美的实现inception中的多分支带来的优势。
作者给出了下面三种结构实质是等价关系
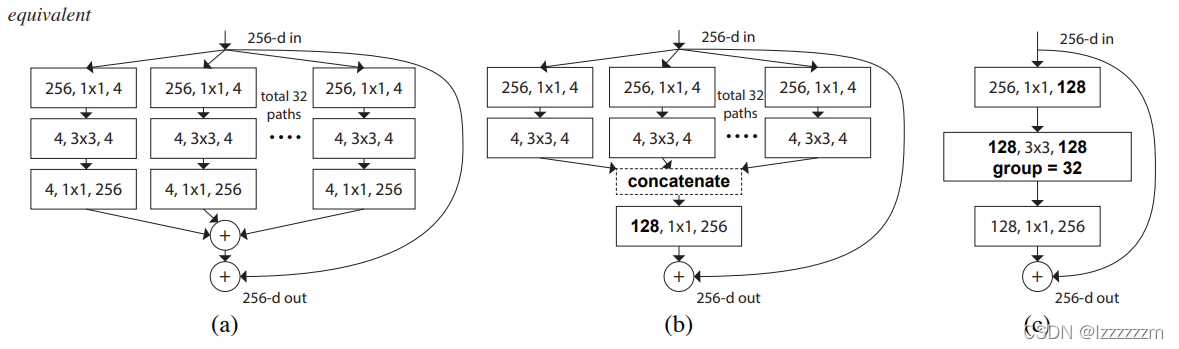
这里等价的原因主要就是利用了卷积分组洗牌等价原理及组卷积的性质,来实现组卷积和multi-branch的等价操作。
? ? ? ? ? ? ? ? ? ? ??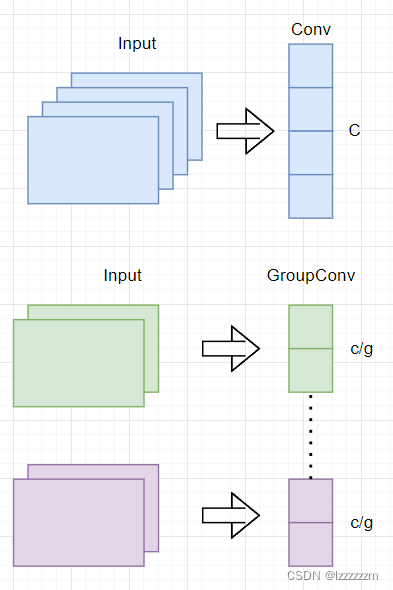
?可以看到使用组卷积其实实质上和multi-branch有一样的性质结构,只不过唯一的不同在与,inception中的multi-branch每个分支的结构不太一样,而使用组卷积实现的话,每个分支结构就是一样的了。
二、Channel-Wise 通道注意力
下面在介绍一个概念,就是通道注意力,因为这里的通道注意力和现在主流的Q,K,V的注意力机制有所不同,但其思想和实现起来也十分简单,其最早提出应该是在SENet中提出的。
注意力机制在我的理解里其实就是交互特征的表现,所以在SENet中提出的通道注意力其实就是两个全连接层的叠加。? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ????
? ? ? ? ? ? ? ? ? ? ? ?? ??
??
?
可以看到两个全连接层其实就是在学习通道相互之间的关系(这里两个全连接层之间还要像relu这种激活函数引入非线性,这里没有画出来),而全连接层之间的权重,通过反向传播,即可以让网络去学习哪些通道是重要的,这就是SEnet提出的通道注意力。
Resnest中的通道注意力也是使用的全连接的形式去构造注意力,而1X1的卷积是可以等效全连接的,所以Resnest中是用1X1的卷积去构造的。
三、Resnest主要涉及思想
有了上面的一系列介绍,其实对与Resnest就可以有一个直观的理解了。下面是作者给出的关键Block的结构,整体看上去挺复杂,但整体可以用三步进行概括,Split(划分),Attention(获得注意力),pooling(汇聚)
?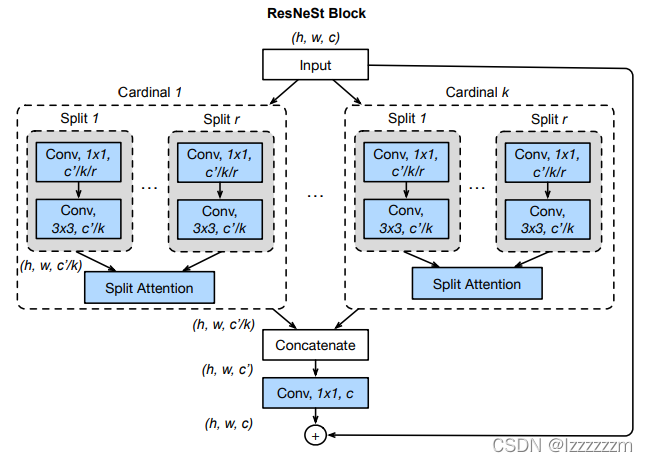
Split和pooling
Resnest将输入先分成K个组,每个组我们称为Cardinal,如果不看Cardinal里面是什么,这一步和我上面介绍Resnext中的(a)图是一样的,那么我们可以用1X1的卷积来简化这一步的划分操作
下面我们看每个Cardinal里面的内容, 每个Cardinal内的block又被划分成R个组,我们称被划分的组为Radix,所以可以看到最后Radix中的输入通道数为C/K/R。
而上面的两次划分,实质上可以由一次1X1的卷积进行划分,所以第一步split即是一个1X1的卷积可以完成。
Attention?
我们以一个Cardinal中如何获得注意力讲解。其实如果熟悉SKNet的话,可以发现其实每个Cardinal里的操作其实就是SKNet的扩展。
上图的Split Attention其实完全可以用SKNet中的结构图来解释(所以也有很多人说,Resnest和SKNet十分像)
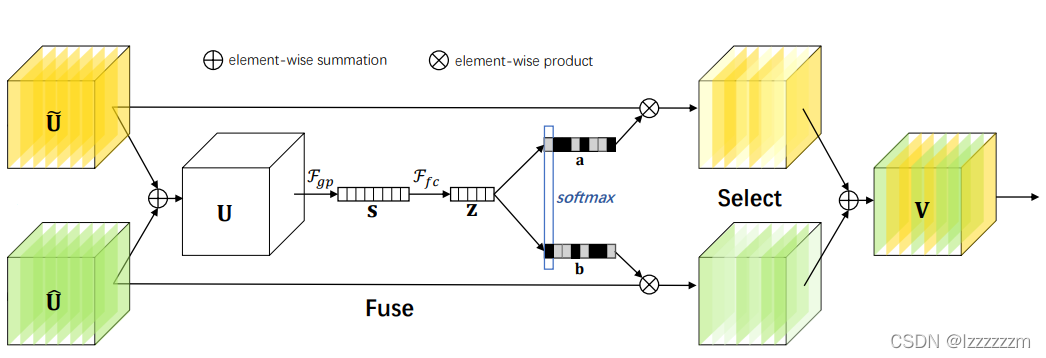
插播一下:SKNet中,是分别用3X3和5X5的卷积核来Split出两个分支。而在ResNest中是用1X1的卷积核平均划分成R个组的,如果我们在这里设置R为2就和上图一样了。
可以看到Split Attention的操作,就是先对划分出的R个组进行相加得到U,然后接上两个全连接层得到注意力权重。对注意力权重经过softmax后Split成R个组和原始的分支进行相乘后再相加就完成了split attention的操作。
这里解释一下为什么注意力权重要经过Softmax函数:我们得到注意力权重的目的就在想要去筛选出哪些通道是重要的,哪些是不重要的,而两个全连接层不能保证得到的注意力权重非负,所以这里要接一个softmax。
经过Softmax后的注意力权重和原始通道相乘,就相对于筛选出了重要性的通道,然后再和组内的其他分支重新组合,就即获得了多通道的优势,又得到了通道间注意力的先验知识。
结合下面的代码,应该会对Split Attention更加了解
class SplAtConv2d(nn.Module):
"""
Split-Attention Conv2d
"""
def __init__(self, in_channels, channels, kernel_size, stride=(1, 1), padding=(1, 1),
dilation=(1, 1), groups=1, bias=True,
radix=2, reduction_factor=4, norm_layer=nn.BatchNorm2d, **kwargs):
super(SplAtConv2d, self).__init__()
# #
inter_channels = max(in_channels * radix // reduction_factor, 32)
self.radix = radix
self.cardinality = groups
self.channels = channels
self.radix_conv = nn.Sequential(
nn.Conv2d(in_channels, channels * radix, kernel_size, stride, padding, dilation,
groups=groups * radix, bias=bias, **kwargs),
norm_layer(channels * radix),
nn.ReLU(inplace=True)
)
self.fc1 = nn.Conv2d(channels, inter_channels, 1, groups=self.cardinality)
self.bn1 = norm_layer(inter_channels)
self.fc2 = nn.Conv2d(inter_channels, channels * radix, 1, groups=self.cardinality)
self.relu = nn.ReLU(inplace=True)
self.rsoftmax = rSoftMax(radix, groups)
def forward(self, x):
# -------------------------------
# 经过radix_conv即组卷积产生multi branch个分支U
# U等分成radix个组,组求和得到gap通道内的值
x = self.radix_conv(x)
batch, rchannel = x.shape[:2]
splited = torch.split(x, rchannel // self.radix, dim=1)
gap = sum(splited)
# -------------------------------
# gap通道内 avgpool + fc1 + fc2 + softmax
# 其中softmax是对radix维度进行softmax
gap = F.adaptive_avg_pool2d(gap, 1)
gap = self.fc1(gap)
gap = self.bn1(gap)
gap = self.relu(gap)
atten = self.fc2(gap)
atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
# -------------------------------
# 将gap通道计算出的和注意力和原始分出的radix组个branchs相加得到最后结果
attens = torch.split(atten, rchannel // self.radix, dim=1)
out = sum([att * split for (att, split) in zip(attens, splited)])
# -------------------------------
# 返回一个out的copy, 使用contiguous是保证存储顺序的问题
return out.contiguous()
# 对radix维度进行softmax
class rSoftMax(nn.Module):
def __init__(self, radix, cardinality):
super().__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
# x: [Batchsize, radix, cardinality, h, w]
x = F.softmax(x, dim=1) # 对radix维度进行softmax
x = x.reshape(batch, -1)
return x在每个Cardinal内都执行上述的操作后,对每个Cardinal进行融合和1X1的卷积调整维度后,就得到了最后的输出。所以Resnest的block可以很容易写出,这里给出学习的代码。
class Bottleneck(nn.Module):
"""ResNet Bottleneck
"""
# pylint: disable=unused-argument
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None,
radix=1, cardinality=1, bottleneck_width=64,
avd=False, avd_first=False, dilation=1, is_first=False,
norm_layer=nn.BatchNorm2d):
super(Bottleneck, self).__init__()
# 组卷积中组的个数 = 输出channel * cardinality的个数
group_width = int(planes * (bottleneck_width / 64.)) * cardinality
# 1x1 组卷积
self.conv1 = nn.Conv2d(inplanes, group_width, kernel_size=1, bias=False)
self.bn1 = norm_layer(group_width)
self.radix = radix
# 用来判断是否是block的连接处
self.avd = avd and (stride > 1 or is_first)
self.avd_first = avd_first
if self.avd:
self.avd_layer = nn.AvgPool2d(3, stride, padding=1)
stride = 1
# split attention conv
self.conv2 = SplAtConv2d(
group_width, group_width, kernel_size=3,
stride=stride, padding=dilation,
dilation=dilation, groups=cardinality, bias=False,
radix=radix, norm_layer=norm_layer)
# 1x1 组卷积
self.conv3 = nn.Conv2d(
group_width, planes * 4, kernel_size=1, bias=False)
self.bn3 = norm_layer(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.dilation = dilation
self.stride = stride
def forward(self, x):
residual = x
# ------------------------------------
# 用1x1 组卷积等效 multi branchs
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
if self.avd and self.avd_first:
out = self.avd_layer(out)
# ------------------------------------
# Split attention
out = self.conv2(out)
# ------------------------------------
if self.avd and not self.avd_first:
out = self.avd_layer(out)
# ------------------------------------
# 1X1 conv + bn
out = self.conv3(out)
out = self.bn3(out)
# ------------------------------------
# 跟resnet一样,block和block之间的第一个需要residual需要downsample来降维
# 这里downsample方法为resnet-D中AvgPool(2) + 1x1卷积
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
# ------------------------------------
return out?剩下的组网部分,其实和resnet很相似,这里就不放出了,可以去下载源码学习。(这里吐槽一下,感觉源码写的不是很清楚,光看源码和论文,理解起来花了很多时间)
总结
代码是我为了方便学习进行了一些简化的,另外文中有可能有些概念解释的不是很正确,如果有问题请评论区指正。
作者涉及Resnest的初衷在与想设计一个通用的Strong Backbone,所以Resnest是可以接到很多下游网络上的,比如YOLO,RCNN等目标检测模型中。