文章目录
一、概述
- 皮尔森相关系数也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数,是最常用的一种相关系数。记为r,用来反映两个变量X和Y的线性相关程度,r 值介于-1到1之间,绝对值越大表明相关性越强。
- 适用连续变量。
- 相关系数与相关程度一般划分为
?? 0.8 - 1.0 极强相关
?? 0.6 - 0.8 强相关
?? 0.4 - 0.6 中等程度相关
?? 0.2 - 0.4 弱相关
?? 0.0 - 0.2 极弱相关或无相关
二、定义
2.1 总体样本定义
ρ
X
,
Y
=
c
o
v
(
X
,
Y
)
σ
X
σ
Y
=
E
(
X
?
μ
X
)
E
(
Y
?
μ
Y
)
σ
X
σ
Y
\begin{aligned} \rho_{X,Y} = \frac {cov(X,Y)} {\sigma_{X} \sigma_{Y}} = \frac {E(X-\mu_{X}) E(Y-\mu_{Y})} {\sigma_{X} \sigma_{Y}} \end{aligned}
ρX,Y?=σX?σY?cov(X,Y)?=σX?σY?E(X?μX?)E(Y?μY?)??
其中,
σ
X
=
E
{
[
X
?
E
(
X
)
]
2
}
,
σ
Y
=
E
{
[
Y
?
E
(
Y
)
]
2
}
\sigma_{X} = \sqrt{E\{[X - E(X)]^{2}\}},\sigma_{Y} = \sqrt{E\{[Y - E(Y)]^{2}\}}
σX?=E{[X?E(X)]2}?,σY?=E{[Y?E(Y)]2}?
2.2 估算样本定义
-
估算样本的协方差和标准差,可得到样本相关系数(即样本皮尔森相关系数),常用 r 表示:
r = ∑ i = 1 n ( X i ? X  ̄ ) ( Y i ? Y  ̄ ) ∑ i = 1 n ( X i ? X  ̄ ) 2 ∑ i = 1 n ( Y i ? Y  ̄ ) 2 \begin{aligned} r = \frac { \displaystyle \sum_{i=1}^{n} (X_{i} - \overline{X}) (Y_{i} - \overline{Y}) } { \sqrt{ \displaystyle \sum_{i=1}^{n} (X_{i} - \overline{X})^{2} } \sqrt{ \displaystyle \sum_{i=1}^{n} (Y_{i} - \overline{Y})^{2} } } \end{aligned} r=i=1∑n?(Xi??X)2?i=1∑n?(Yi??Y)2?i=1∑n?(Xi??X)(Yi??Y)?? -
还可以由(Xi,Yi)样本点的标准分数均值估计得到与上式等价的表达式
r = 1 n ? 1 ∑ i = 1 n ( X i ? X  ̄ σ X ) ( Y i ? Y  ̄ σ Y ) \begin{aligned} r = \frac{1}{n-1} \sum_{i=1}^{n}{ (\frac {X_{i} - \overline{X}} {\sigma_{X}} ) (\frac {Y_{i} - \overline{Y}} {\sigma_{Y}} ) } \end{aligned} r=n?11?i=1∑n?(σX?Xi??X?)(σY?Yi??Y?)?
其中, X i ? X  ̄ σ X \frac {X_{i} - \overline{X}} {\sigma_{X}} σX?Xi??X? 是样本X的标准分数。
2.3 两种计算方式
-
(1)
ρ X , Y = c o v ( X , Y ) σ X σ Y = E ( X ? μ X ) E ( Y ? μ Y ) σ X σ Y = E ( X Y ) ? E ( X ) E ( Y ) E ( X 2 ) ? E 2 ( X ) E ( Y 2 ) ? E 2 ( Y ) \begin{aligned} \rho_{X,Y} = \frac {cov(X,Y)} {\sigma_{X} \sigma_{Y}} = \frac {E(X-\mu_{X}) E(Y-\mu_{Y})} {\sigma_{X} \sigma_{Y}} = \frac {E(XY) - E(X)E(Y)} { \sqrt{E(X^2) - E^{2}(X)} \sqrt{E(Y^2) - E^{2}(Y)} } \end{aligned} ρX,Y?=σX?σY?cov(X,Y)?=σX?σY?E(X?μX?)E(Y?μY?)?=E(X2)?E2(X)?E(Y2)?E2(Y)?E(XY)?E(X)E(Y)?? -
(2)
ρ X , Y = n ∑ X Y ? ∑ X ∑ Y n ∑ X 2 ? ( ∑ X ) 2 n ∑ Y 2 ? ( ∑ Y ) 2 \begin{aligned} \rho_{X,Y} = \frac {n \sum{XY} - \sum{X}\sum{Y}} { \sqrt{n \sum{X^{2}} - (\sum{X})^{2}} \sqrt{n \sum{Y^{2}} - (\sum{Y})^{2}} } \end{aligned} ρX,Y?=n∑X2?(∑X)2?n∑Y2?(∑Y)2?n∑XY?∑X∑Y??
2.4 皮尔森距离
d X , Y = 1 ? ρ X , Y d_{X,Y} = 1 - \rho_{X,Y} dX,Y?=1?ρX,Y?
三、python 实现
3.1 生成随机数据集
import random
import pandas as pd
n = 10000
X = [random.normalvariate(100, 10) for i in range(n)] # 随机生成服从均值100,标准差10的正态分布序列
Y = [random.normalvariate(100, 10) for i in range(n)] # 随机生成服从均值100,标准差10的正态分布序列
Z = [i*j for i,j in zip(X,Y)]
df = pd.DataFrame({"X":X,"Y":Y,"Z":Z})
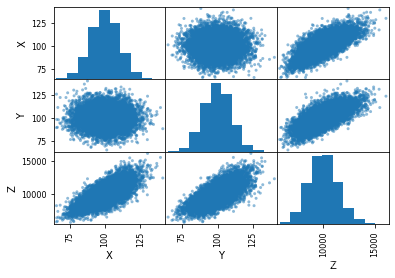
3.2 绘制散点图
import matplotlib.pyplot as plt
# 绘制散点图矩阵
pd.plotting.scatter_matrix(df)
plt.show()
3.3 计算相关系数
3.3.1 自定义函数(无显著性检验)
import math
def PearsonFirst(X,Y):
'''
公式一
'''
XY = X*Y
EX = X.mean()
EY = Y.mean()
EX2 = (X**2).mean()
EY2 = (Y**2).mean()
EXY = XY.mean()
numerator = EXY - EX*EY # 分子
denominator = math.sqrt(EX2-EX**2)*math.sqrt(EY2-EY**2) # 分母
if denominator == 0:
return 'NaN'
rhoXY = numerator/denominator
return rhoXY
def PearsonSecond(X,Y):
'''
公式二
'''
XY = X*Y
X2 = X**2
Y2 = Y**2
n = len(XY)
numerator = n*XY.sum() - X.sum()*Y.sum() # 分子
denominator = math.sqrt(n*X2.sum() - X.sum()**2)*math.sqrt(n*Y2.sum() - Y.sum()**2) # 分母
if denominator == 0:
return 'NaN'
rhoXY = numerator/denominator
return rhoXY
r1 = PearsonFirst(df['X'],df['Z']) # 使用公式一计算X与Z的相关系数
r2 = PearsonSecond(df['X'],df['Z']) # 使用公式二计算X与Z的相关系数
print("r1: ",r1)
print("r2: ",r2)

3.3.2 python 函数
(1)pandas.corr 函数(无显著性检验)
- 参数解析
DataFrame.corr(
??method = ‘pearson’, # 可选值为{‘pearson’:‘皮尔森’, ‘kendall’:‘肯德尔秩相关’, ‘spearman’:‘斯皮尔曼’}
??min_periods=1 ?? # 样本最少的数据量
)
df.corr(method="pearson")

(2)scipy.stats.pearsonr 函数 (有显著性检验)
from scipy.stats import pearsonr
r = pearsonr(df['X'],df['Z'])
print("pearson系数:",r[0])
print(" P-Value:",r[1])

(3)pandas.corr 加 scipy.stats.pearsonr 获取相关系数检验P值矩阵
def GetPvalue_Pearson(x,y):
return pearsonr(x,y)[1]
df.corr(method=GetPvalue_Pearson)
