正则化通过为模型损失函数添加惩罚项使得学出的模型参数值较小,是应对过拟合常用手段
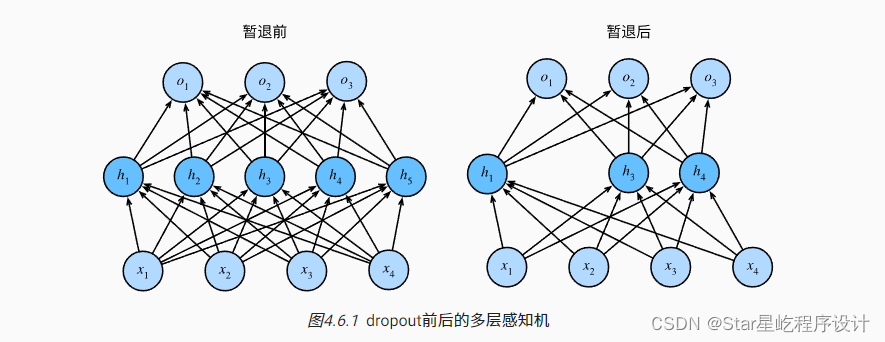
丢弃法(Dropout)是一种在学习的过程中随机删除神经元的方法。训练时随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递。
- 有效抑制过拟合的一种正则化手段
- 通常作用再隐藏全连接层的输出上
- 训练时,每传递一次信号,就会随机选择要删除的神经元(丢弃法将一些输出项随机置为0来控制模型的复杂度)
- 测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出
- 丢弃概率是控制模型复杂度的超参数
Dropout实现:
Dropout随机删除了隐藏层的部分元素,所以输出层的计算无法过度依赖隐藏层的任一个,从而在模型训练时起到了正则化作用。
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)在模型训练的时候,Dropout层将以指定的丢弃概率随机丢弃上一层的输出元素。但是在测试模型中,Dropout不发挥作用
- Dropout层放在全连接层之后?
import torch.nn as nn
input_size = 28 * 28
hidden_size = 500
num_classes = 10
# 三层神经网络
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 输入层到影藏层
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes) # 影藏层到输出层
self.dropout = nn.Dropout(p=0.5) # dropout训练
def forward(self, x):
out = self.fc1(x)
out = self.dropout(out)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size, hidden_size, num_classes)
model.train()
model.eval()