Mobile-Former:连接MobileNet与Transformer?form
CVPR2022
?Microsoft & USTC
Abstract
本文提出的Mobile-Former是一种并行的将MobileNet与Transformer桥接在一起的结构,这种结构一方面利用MobileNet局部特征提取的优势另一方面利用Transformer在全局建模的优势,允许局部和全局特征的双向融合。而且不像近期的工作包含token数目很少,Mobile-Fromer计算效率很高,因为是一种轻量级网络,可以设置更多的token数目,因此表征能力更强。与MibileNetV3相比,在拥有更少FLOP基础上获得了更好的精度,在ImageNet数据集上,FLOP=294M时top-1精度为77.9%,与MobileNetV3相比节省了17%的算力,性能提升1.3%;并且通过将DETR中的encoder和decoder替换为本文的基准框架,比原始的DETR做目标检测性能提升1.1AP,同时计算成本减少了52%,参数量减少了36%。
Section I Introduction
近期ViT在提取全局依赖等方面超过了CNN,但是将FLOPs限制在1G以内ViT的优势就消失了,仍然是MobileNet的天下,尤其是在300M FLOPs量级,用于ImageNet分类,主要得益于MobileNet中采用的深度可分离卷积,自然就产生一个问题:?如何设计高效的网络可以有效同时处理局部和全局的交互关系?
???一种可行的办法就是将卷积与ViT相结合,也有一些工作验证了将二者串行在一起的有效性。本文将串行连接变为并行,提出一种新的将并行的MobileNet和Transformer桥接的网络-Mobile-Former,具体结构参见Fig 1.
???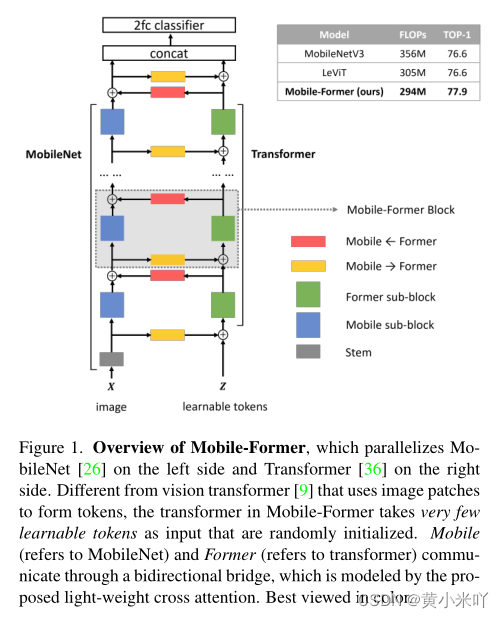
Mobile部分将输入通过深度可分离卷积处理来提取局部特征,Transformer设置一定数量的token,堆叠注意力模块和FFN模块来编码全局信息。
Mobile和Former之间通过一个双向桥接器进行通信,进行局部和全局的融合,这一步至关重要,这样将局部特征也作为Former的token输入,同时Former提取的全局特征也会加入到特征图谱的每一个像素中。本文提出一个轻量级的交叉注意力来建模这一双向桥接,在(a)通道数较少的瓶颈处计算交叉注意,并且(b)Mobile段删除Q-K-V的投影。?这种并行的结构同时利用了两种网络的优点,更重要的是局部-全局的信息交换是通过一个轻量级的稀疏Transformer实现,进展总计算成本的20%,但却能显著提升性能。
?Mobile-Former在分类和目标检测任务中均取得了有益的性能。?分类: 294M flops时达到了77.9%的top-1精度,优于MobileNetV3和LeViT;并且在25M-500M flops范围内内Mobile-Former一直优于CNN和ViT模型。?
?目标检测任务中也优于MobileNetV3做backbone的RetinaNet,获得了8.2AP的性能提升,同时计算成本更低。与DETR相比,在同样的queries设置下获得了1.1AP的性能提升,同时FLOPs更少,模型规模更小。?本文想强调的是Mobile-Former的最优参数配置-如网络宽度、深度等并不是本文的目标,而是想阐明这种并行的设计是一种高效且有效的网络结构。
Section II Related Work
Light-weight convolutional neural networks
MobileNet通过堆叠深度可分离卷积来编码局部特征;ShuffleNet则通过组卷积和通道shuffle简化pointwise convolution;MicroNett提出使用微分解卷积的方法扩大网络宽度,降低阶段连接性来搭建FLOPs基底的情况。Dynamic operators则研究使用动态算子来提升MobileNet的性能,还有的其他优化提出使用butterfly transform,GhostNet提出使用简便的线性变换,AdderNet使用了加法来替代乘法;MixConv则看就混合卷积核大小的计算。
??## Vision Transformer
?? ?近期ViT及其变体在诸多计算机视觉任务中取得了惊人的性能,最初的ViT需要在大规模数据集上预训练的结果,比如JFT-300M,DeiT提出在中小型数据集上有效训练的策略;随后Swin Transformer通过在移动局部窗口内计算自注意力使得可以处理高分辨率输入,CSWin则是使用cross-shaped window,T2T-ViT通过递归的聚合相邻的token,逐步将图像转换为标记;HaloNet则是通过注意力降采样和阻塞局部注意力提升速度、内存利用率等。
CNN 与 ViT结合
近期也有诸多工作研究如何将CNN与ViT结合,比如BoTNet通过将ResNet最后三层替换为自注意力有效提升了做实例分割和目标检测的精度;ConViT提出一种门控的位置相关的注意力来引入软性卷积偏置;CvT则是在多头注意力之前引入了深度可分离卷积;LeViT则使用卷积来替代自注意力之前的切patch方式。
?? ?本文提出一种不同的以并行的方式来结合MobileNet与Transformer,并且可以双向传递。最终以更低的FLOPs达到了超过CNN和ViT变体的性能。
Section III Our Method: Mobile-Former
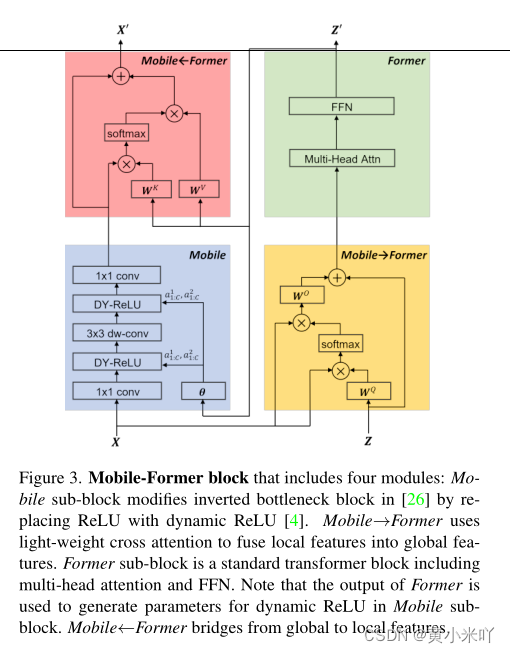
Part 1 Overview
Fig 3展示了Mobile-Former的模块结构,Fig 1展示了Mobile-Former的整体框架。?Parallel structure:?MobileNet与Transformer是并行的,并且通过双向交叉注意将他们连接起来。Mobile将输入通过倒置模块来提取特征,Former以token作为输入,最开始是随机初始化的。与ViT不同的地方在于ViT使用线性投影,本文的token数目更少,每一块都代表图像的全局先验,这样计算成本更小。
?? ????Low cost rwo-way bridge:
?? ?????Former和Mobile通过一个双向桥进行交互,二者是双向融合的,分别表示为Mobile->Former和Former->Mobile,本文使用一个轻量级的交叉注意力来建模,Mobile->Former计算过程如下:
?? ?????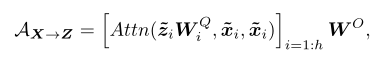
Former->Mobile计算过程如下:
?? ???????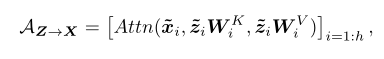
X代表局部特征,Z代表Former部分的token序列,交叉注意力计算的就是二者之间的关联。?可以看到key和value在Mobile端的计算中是移除的,只保留query矩阵;而Former端则是仅保留Mobile的key,value部分。
??## ?????????Part 2 Mobile-Former Block?
?? ?????????Mobile-Former通过堆叠Mobile-Former模块组成,每一个模块包含四部分:Mobile子块,Former子块,两路交叉注意力:Mobile->Former和Former->Mobile?
?? ?????????输入和输出:
?? ??????????Mobile->Former有两个输入:局部特征X(CxHxW)和全局序列Z(Mxd)。M和d对于所有模块都是一样的,模块的输出作为更新后的输入特征X’和全局序列Z’
Mobile sub-block:?
Mobile自块的输入是特征图谱,输出则作为Mobile->Former的输入,与原始的倒置瓶颈模块区别在于将ReLU激活替换为dynamic ReLU,参数是对特征图平均池化结果再经过两层MLP生成,块找那个卷积核大小为3x3.?Former sub-block:?Former子块则是标准的Transformer模块,包含MHSA和FFN,FFN中的扩展率为2,不是原始设置的4,并且在模块后使用层归一化。
?Mobile -> Former:?
?Mobile -> Former提出的轻量级交叉注意力负责将局部特征融合到全局标记序列中,与标准的注意力计算相比,移除了Wk和Wv这部分的投影矩阵,来降低计算量。
??Former->Mobile:?
??Former->Mobile负责将全局特征融合到局部特征图中,局部特征保留的是query矩阵,token保留的是key和value。
???计算复杂度:
????对于输入特征图HW x C,token维度Mxd?Mobile部分计算量最大 为O(HWC^2)?Former计算量为O(M2d+Md2)?双向交叉注意力的计算量分别为O(MHWC+MdC)