1.ģ�ͺͲ�������
ģ��:2��������+1��ȫ���Ӳ�
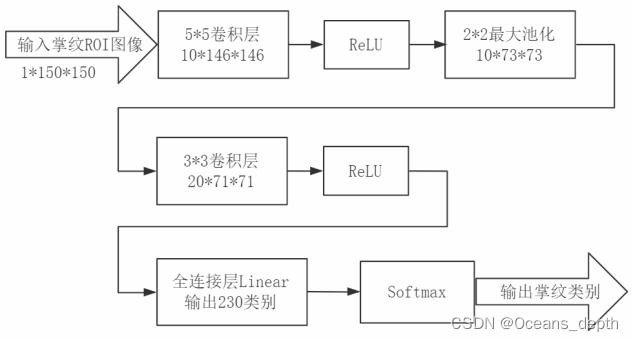
����:
BATCH_SIZE = 32 # ���峬����,ÿ�δ���32��ͼƬ
EPOCHS = 20 # �����ݼ�ѵ��20��
LR = 0.01 # ѧϰ��
TRAIN_DIVISION = 3 # ѵ��������ռ��
optimizer = optim.Adam(model.parameters(), lr=LR) # �Ż���
1.1 ��IITD/Left�������ݡ� VS ��IITD/Left+Right���ݡ�

2.��ģ��
ģ��2.1:3��������+2��ȫ���Ӳ� ���:RR=0.9158

ģ��2.2:4��������+2��ȫ���Ӳ� ���:RR=0.9145

ģ��2.3:4��������+3��ȫ���Ӳ� ���:RR=0.8776

ģ��2.4:4��������(���ľ�����)+2��ȫ���Ӳ� ���:RR=0.9158

ģ��2.5:4��������(�������ͨ����)+2��ȫ���Ӳ� ���:RR=0.9237(EPOCH=200)

2.5�ƺ�����õ�,��֮ǰ��ģ�Ϳ�������Ϊû����ȫ����.
3. �IJ���
�ۺϽ��,ģ��ѡ��2.5�ġ�
3.1 �Ż���
֮ǰȫ����Adam��Ϊ�Ż���,�����ٶȿ�(20�ε����ھ��ܴﵽ�ܸߵ�RR),��2.5��ģ����186�ε����ﵽRR=0.9237��

3.2 Batch_size
�Ż���ѡ��Adam,LR=0.001��

3.3 Learning Rate
�Ż���ѡ��Adam,Batch_size=64��

4.BN
�������������:
1)ͳ��ÿ��ͨ�����е������ֵ�ľ�ֵ�ͷ���;
2)ÿ��ͨ��������ֵ����ֵ������;
BN:Max RR: 0.951316��Running time: 12049.209277153015 s

5. ���ݼ�
ͬ�÷ǽӴ�ʽ�������ݼ�:
Max RR: 0.999500��Running time: 39925.49079298973 s
(Train Epoch:22 Loss:0.000003
Test �C Average loss:0.2042,RR:0.265000)��Ϊʲô?
Max RR: 0.999250��Running time: 39227.911673784256 s
(Train Epoch:114 Loss:0.000000
Test �C Average loss:0.1773,RR:0.197000)Ϊʲô?
