文章目录
han_attention(双向GRU+attention)
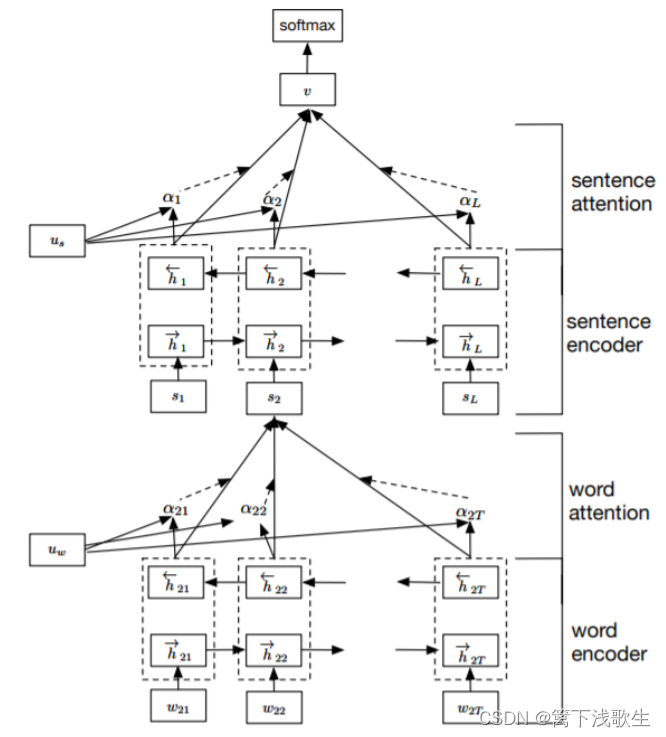
词编码:

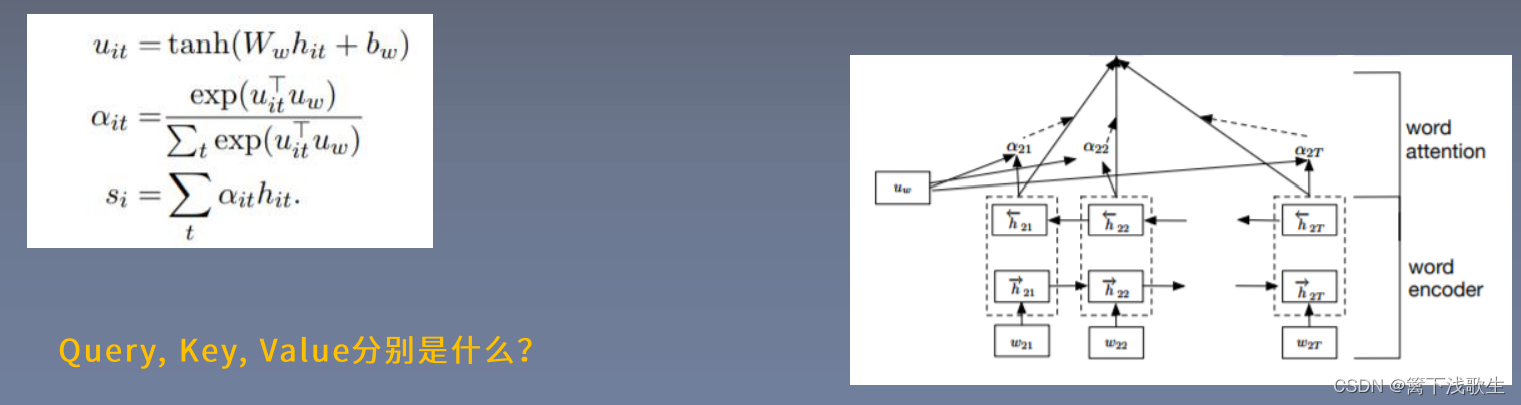
词级别的注意力机制:
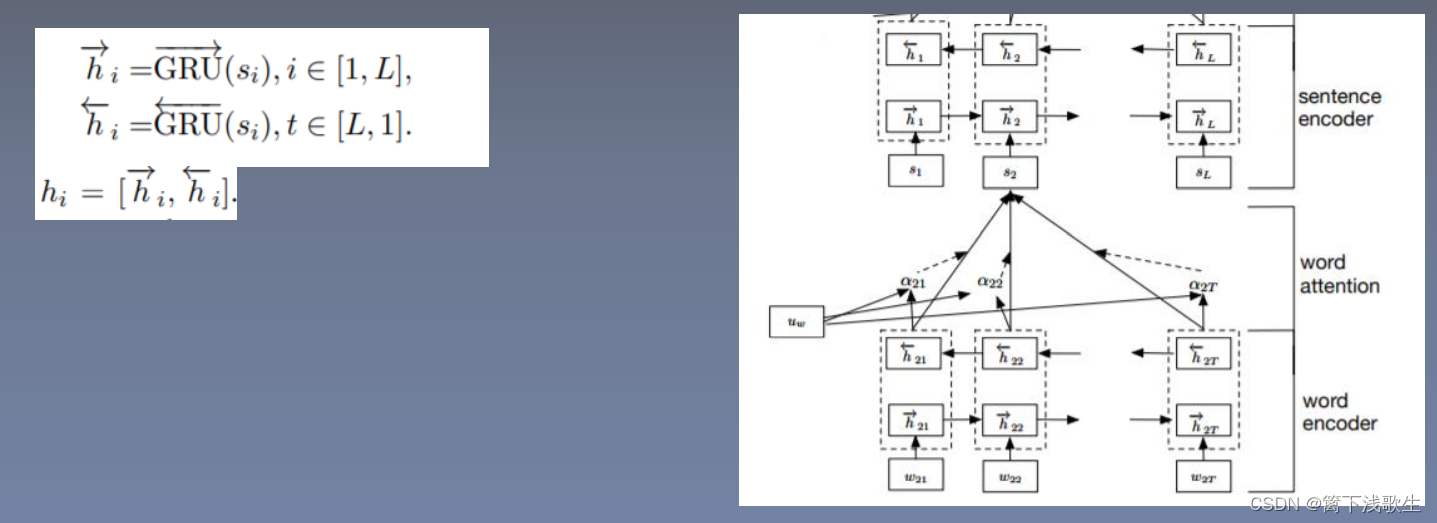
句子编码:
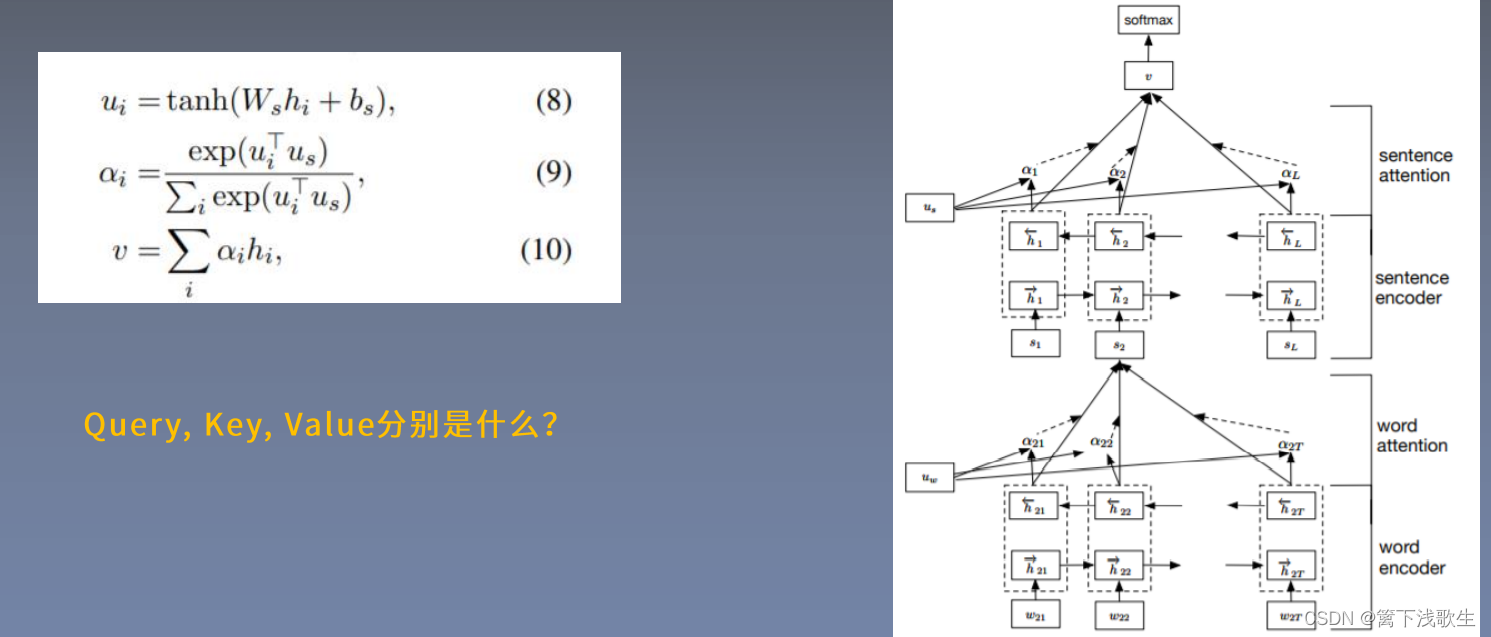
句子级别的注意力机制:
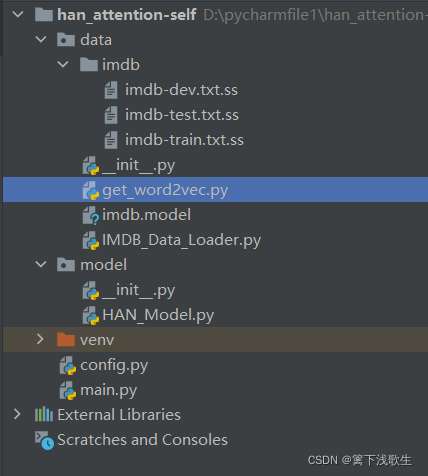
一、文件目录
二、语料集
数据集: http://ir.hit.edu.cn/~dytang/paper/emnlp2015/emnlp-2015-data.7z
三、数据处理(IMDB_Data_Loader.py)
1.数据集加载(排序,分句)
2.读取标签和数据
3.创建word2id(源语言和目标语言)
???3.1统计词频
???3.2加入 pad:0,unk:1创建word2id
4.将数据转化成id(源语言和目标语言)
5.添加目标数据的输入(target_data_input)
from gensim.models import KeyedVectors
from torch.utils import data
import os
import torch
import numpy as np
class IMDB_Data(data.DataLoader):
def __init__(self,data_name,min_count,word2id=None,max_sentence_length=100,batch_size=64,is_pretrain=True):
self.path = os.path.abspath(".")
if "data" not in self.path:
self.path += "/data"
self.data_name = "/imdb/"+data_name
self.min_count = min_count
self.word2id = word2id
self.max_sentence_length = max_sentence_length
self.batch_size =batch_size
self.datas,self.labels = self.load_data()
if is_pretrain:
self.get_word2vec()
else:
self.weight = None
for i in range(len(self.datas)):
self.datas[i] = np.array(self.datas[i])
# 数据集加载
def load_data(self):
datas = open(self.path+self.data_name,encoding="utf-8").read().splitlines()
datas = [data.split(" ")[-1].split() + [data.split(" ")[2]] for data in datas] # 取出数据并分词+标签
# 根据长度排序
datas = sorted(datas, key=lambda x: len(x), reverse=True)
labels = [int(data[-1]) - 1 for data in datas]
datas = [data[0:-1] for data in datas]
if self.word2id == None:
self.get_word2id(datas)
# 分句
for i, data in enumerate(datas):
datas[i] = " ".join(data).split("<sssss>")
for j, sentence in enumerate(datas[i]):
datas[i][j] = sentence.split()
datas = self.convert_data2id(datas)
return datas,labels
# word2id
def get_word2id(self, datas):
word_freq = {}
for data in datas:
for word in data:
word_freq[word] = word_freq.get(word, 0) + 1
word2id = {"<pad>": 0, "<unk>": 1}
for word in word_freq:
if word_freq[word] < self.min_count:
continue
else:
word2id[word] = len(word2id)
self.word2id = word2id
# 将数据转化为id,句子必须一样的长度,每个文档的句子一样多
def convert_data2id(self, datas):
for i, document in enumerate(datas):
if i % 10000 == 0:
print(i, len(datas))
for j, sentence in enumerate(document):
for k, word in enumerate(sentence):
datas[i][j][k] = self.word2id.get(word,self.word2id["<unk>"])
datas[i][j] = datas[i][j][0:self.max_sentence_length] + \
[self.word2id["<pad>"]] * (self.max_sentence_length - len(datas[i][j]))
for i in range(0, len(datas), self.batch_size):
max_data_length = max([len(x) for x in datas[i:i + self.batch_size]])
for j in range(i, min(i + self.batch_size, len(datas))):
datas[j] = datas[j] + [[self.word2id["<pad>"]] * self.max_sentence_length] * (max_data_length - len(datas[j]))
return datas
def get_word2vec(self):
print("Reading word2vec Embedding...")
wvmodel = KeyedVectors.load_word2vec_format(self.path + "/imdb.model", binary=True)
tmp = []
for word, index in self.word2id.items():
try:
tmp.append(wvmodel.get_vector(word))
except:
pass
mean = np.mean(np.array(tmp))
std = np.std(np.array(tmp))
print(mean, std)
vocab_size = len(self.word2id)
embed_size = 200
np.random.seed(2)
embedding_weights = np.random.normal(mean, std, [vocab_size, embed_size]) # 正太分布初始化方法
for word, index in self.word2id.items():
try:
embedding_weights[index, :] = wvmodel.get_vector(word)
except:
pass
self.weight = torch.from_numpy(embedding_weights).float()
def __getitem__(self, idx):
return self.datas[idx], self.labels[idx]
def __len__(self):
return len(self.labels)
if __name__=="__main__":
imdb_data = IMDB_Data(data_name="imdb-train.txt.ss",min_count=5,is_pretrain=True)
training_iter = torch.utils.data.DataLoader(dataset=imdb_data,
batch_size=64,
shuffle=False,
num_workers=0)
for data, label in training_iter:
print (np.array(data).shape)
四、模型(HAN_Model.py)
import torch
import torch.nn as nn
import numpy as np
from torch.nn import functional as F
from torch.autograd import Variable
class HAN_Model(nn.Module):
def __init__(self,vocab_size,embedding_size,gru_size,class_num,is_pretrain=False,weights=None):
super(HAN_Model, self).__init__()
if is_pretrain:
self.embedding = nn.Embedding.from_pretrained(weights, freeze=False)
else:
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.word_gru = nn.GRU(input_size=embedding_size,hidden_size=gru_size,num_layers=1,
bidirectional=True,batch_first=True)
#自己设的query Uw
self.word_context = nn.Parameter(torch.Tensor(2*gru_size, 1),requires_grad=True)#将一个固定不可训练的tensor转换成可以训练的类型parameter
self.word_dense = nn.Linear(2*gru_size,2*gru_size)
self.sentence_gru = nn.GRU(input_size=2*gru_size,hidden_size=gru_size,num_layers=1,
bidirectional=True,batch_first=True)
# 自己设的query Us
self.sentence_context = nn.Parameter(torch.Tensor(2*gru_size, 1),requires_grad=True)
self.sentence_dense = nn.Linear(2*gru_size,2*gru_size)
self.fc = nn.Linear(2*gru_size,class_num)
def forward(self, x,gpu=False):
sentence_num = x.shape[1]
sentence_length = x.shape[2]
x = x.view([-1,sentence_length]) # x: bs*sentence_num*sentence_length -> (bs*sentence_num)*sentence_length 转成二维
x_embedding = self.embedding(x) # (bs*sentence_num)*sentence_length*embedding_size
word_outputs, word_hidden = self.word_gru(x_embedding) # word_outputs.shape: (bs*sentence_num)*sentence_length*2gru_size
word_outputs_attention = torch.tanh(self.word_dense(word_outputs)) # (bs*sentence_num)*sentence_length*2gru_size
weights = torch.matmul(word_outputs_attention,self.word_context) # (bs*sentence_num)*sentence_length*1
weights = F.softmax(weights,dim=1) # (bs*sentence_num)*sentence_length*1
x = x.unsqueeze(2) # (bs*sentence_num)*sentence_length*1 加维度
# 权值矩阵:有值的地方保留,pad部分设为0
if gpu:
weights = torch.where(x!=0,weights,torch.full_like(x,0,dtype=torch.float).cuda())
else:
weights = torch.where(x != 0, weights, torch.full_like(x, 0, dtype=torch.float)) # (bs*sentence_num)*sentence_length*1
# 和恢复为1
weights = weights/(torch.sum(weights,dim=1).unsqueeze(1)+1e-4) # (bs*sentence_num)*sentence_length*1
sentence_vector = torch.sum(word_outputs*weights,dim=1).view([-1,sentence_num,word_outputs.shape[-1]]) #bs*sentence_num*2gru_size
sentence_outputs, sentence_hidden = self.sentence_gru(sentence_vector)# sentence_outputs.shape: bs*sentence_num*2gru_size
attention_sentence_outputs = torch.tanh(self.sentence_dense(sentence_outputs)) # sentence_outputs.shape: bs*sentence_num*2gru_size
weights = torch.matmul(attention_sentence_outputs,self.sentence_context) # sentence_outputs.shape: bs*sentence_num*1
weights = F.softmax(weights,dim=1) # sentence_outputs.shape: bs*sentence_num*1
x = x.view(-1, sentence_num, x.shape[1]) # bs*sentence_num*sentence_length
x = torch.sum(x, dim=2).unsqueeze(2) # bs*sentence_num*1
if gpu:
weights = torch.where(x!=0,weights,torch.full_like(x,0,dtype=torch.float).cuda())
else:
weights = torch.where(x != 0, weights, torch.full_like(x, 0, dtype=torch.float)) # bs*sentence_num*1
weights = weights / (torch.sum(weights,dim=1).unsqueeze(1)+1e-4) # bs*sentence_num*1
document_vector = torch.sum(sentence_outputs*weights,dim=1)# bs*2gru_size
output = self.fc(document_vector) #bs*class_num
return output
han_model = HAN_Model(vocab_size=30000,embedding_size=200,gru_size=50,class_num=4)
x = torch.Tensor(np.zeros([64,50,100])).long()
x[0][0][0:10] = 1
output = han_model(x)
print (output.shape)
五、训练和测试
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from model import HAN_Model
from data import IMDB_Data
import numpy as np
from tqdm import tqdm
import config as argumentparser
config = argumentparser.ArgumentParser()
torch.manual_seed(config.seed)
if config.cuda and torch.cuda.is_available(): # 是否使用gpu
torch.cuda.set_device(config.gpu)
def get_test_result(data_iter,data_set):
# 生成测试结果
model.eval()
true_sample_num = 0
for data, label in data_iter:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
else:
data = torch.autograd.Variable(data).long()
if config.cuda and torch.cuda.is_available():
out = model(data, gpu=True)
else:
out = model(data)
true_sample_num += np.sum((torch.argmax(out, 1) == label).cpu().numpy())
acc = true_sample_num / data_set.__len__()
return acc
# 导入训练集
training_set = IMDB_Data("imdb-train.txt.ss",min_count=config.min_count,
max_sentence_length = config.max_sentence_length,batch_size=config.batch_size,is_pretrain=True)
training_iter = torch.utils.data.DataLoader(dataset=training_set,
batch_size=config.batch_size,
shuffle=False,
num_workers=0)
# 导入测试集
test_set = IMDB_Data("imdb-test.txt.ss",min_count=config.min_count,word2id=training_set.word2id,
max_sentence_length = config.max_sentence_length,batch_size=config.batch_size)
test_iter = torch.utils.data.DataLoader(dataset=test_set,
batch_size=config.batch_size,
shuffle=False,
num_workers=0)
if config.cuda and torch.cuda.is_available():
training_set.weight = training_set.weight.cuda()
model = HAN_Model(vocab_size=len(training_set.word2id),
embedding_size=config.embedding_size,
gru_size = config.gru_size,class_num=config.class_num,weights=training_set.weight,is_pretrain=False)
if config.cuda and torch.cuda.is_available(): # 如果使用gpu,将模型送进gpu
model.cuda()
criterion = nn.CrossEntropyLoss() # 这里会做softmax
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
loss = -1
for epoch in range(config.epoch):
model.train()
process_bar = tqdm(training_iter)
for data, label in process_bar:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
else:
data = torch.autograd.Variable(data).long()
label = torch.autograd.Variable(label).squeeze()
if config.cuda and torch.cuda.is_available():
out = model(data,gpu=True)
else:
out = model(data)
loss_now = criterion(out, autograd.Variable(label.long()))
if loss == -1:
loss = loss_now.data.item()
else:
loss = 0.95*loss+0.05*loss_now.data.item()
process_bar.set_postfix(loss=loss_now.data.item())
process_bar.update()
optimizer.zero_grad()
loss_now.backward()
optimizer.step()
test_acc = get_test_result(test_iter, test_set)
print("The test acc is: %.5f" % test_acc)
实验结果
生成测试集和验证集的blue值(翻译的评价指标),将测试集的原始数据和翻译数据都存入文件。