In this work we present a simple, unifified approach for estimating maps directly from monocular images using a single end- to-end deep learning architecture. For the maps themselves we adopt a semantic Bayesian occupancy grid framework, allowing us to trivially ccumulate information over multiple cameras and timesteps.
【CC】将图片转化成BEV的语义map; 注意,本文详细在描述单张图片的BEV转换,并没有详细描述camera间的拼接
Construction of birds-eye-view maps is however at present a complex multistage processing pipeline, involving the composition of multiple fundamental machine vision tasks: structure from motion, ground plane estimation, road segmentation, lane detection, 3D object detection, and many more
【CC】语义map的功能定义:motion的结构化表达,地面估计,道路语义,车道线检测,3D目标检测,等等
Given the high cost and limited resolution of LiDAR and radar sensors, the ability to build maps from image sensors alone is likely to be crucial to the development of robust autonomous vehicles. Occupancy grid maps their grid-based structure also makes them highly agreeable to processing by convolutional neural networks,
【CC】本文只关注视觉的处理;Occupancy grid maps 方便CNN网络的处理?!
We propose a novel dense transformer layer which maps image-based feature maps into the birds-eye view space.
【CC】使用transfomer block进行BEV转换
We design a deep convolutional neural network architecture, which includes a pyramid of transformers operating at multiple image scales, to predict accurate birds-eye-view maps from monocular images.
【CC】使用了金字塔模式,去解决多尺度的问题
A common approach is to use inverse perspective mapping (IPM) to map front-view image onto the ground plane via a homography [1, 15].
【CC】好像fusionnet中BEV的转换就是使用的IPM; 另,传统SLAM里面 通过homography求解 旋转阵是常用技巧
Training on real data is crucial to performance in safety critical systems, and we believe we are the fifirst to do so using a directly supervised approach.
【CC】不是很明白为什么不采用自监督/弱监督的方式进行训练??? 是因为loss func的设计吗??
总体网络结构
The pyramid occupancy network consists of four main stages. A backbone feature extractor generates multiscale semantic and geometric features from the image. This is then passed to an FPN inspired feature pyramid which upsamples low-resolution feature-maps to provide context to features at higher resolutions. A stack of dense transformer layers together map the image-based features into the birds-eye view, which are processed by the topdown network to predict the final semantic occupancy grid probabilities. An overview of the approach is shown in Figure 2.
【CC】整个网络有四部分:一个backbone做多尺度的特征提取,喂给FPN层,同时做上采样;一组transfomer block做BEV变换;喂给topdown做reshape和预测. topdown的预测是不是可以换成TNT更有效果??
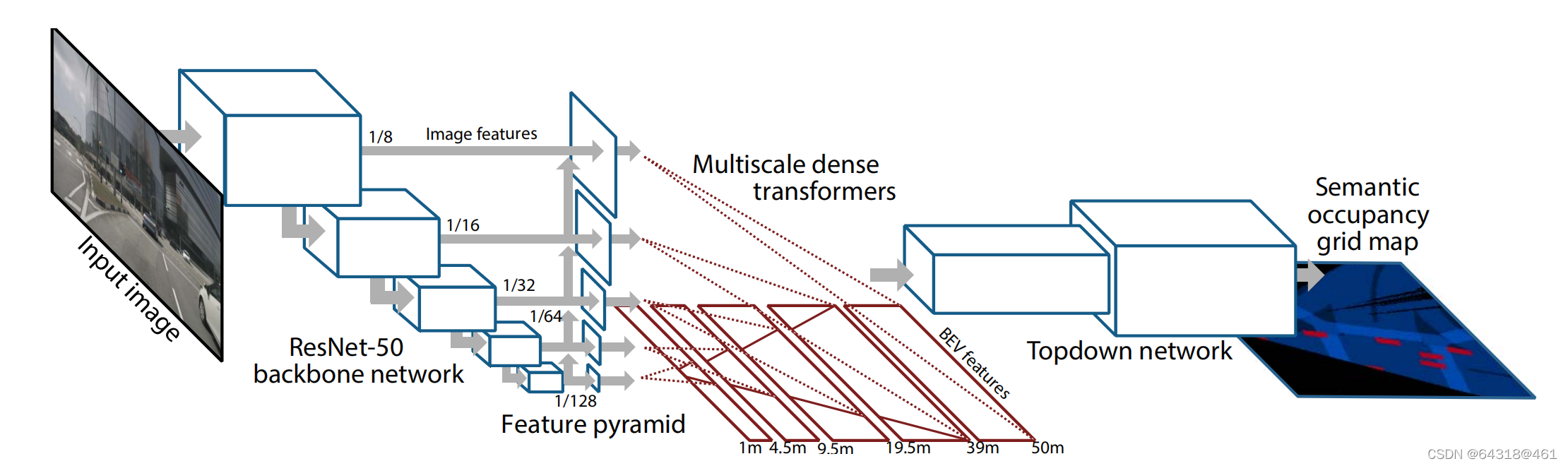
Figure 2. Architecture diagram showing an overview of our approach.
(1) A ResNet-50 backbone network extracts image features atmultiple resolutions.
(2) A feature pyramid augments the high-resolution features with spatial context from lower pyramid layers.
(3) Astack of dense transformer layers map the image-based features into the birds-eye-view.
(4) The topdown network processes the birds-eyeview features and predicts the final semantic occupancy probabilities.
we use a pretrained FPN network, which incorporates a ResNet-50 front-end. The topdown network consists of a stack of 8 residual blocks, including a transposed convolution layer which upsamples the birds eye-view features
【CC】骨干网络是resnet 50, FPN网络是hekaiming 2016年中的经典FPN,topdown是resblock 带转置卷积(上采样)
形式化描述
Occupancy grid maps are a type of discrete random fifield where each spatial location xi has an associated state mi, which may be either occupied (mi = 1), or free (mi = 0),the state mci represents the presence or absence of an object of class c in a given grid cell. We therefore propose to train a deep CNN-based inverse sensor model p(mci |zt) = fθ(zt, xi) which learns to predict occupancy probabilities from a single monocular input image
【CC】基于Occupancy grid结构,通过CNN去模拟每个网格某种分类obj出现的 p(mci |zt)后验估概率密度函数 fθ(zt, xi);注意,这里说的是单张monocular的图片
The binary cross entropy loss encourages the predicted semantic occupancy probabilities p(mci |zt) to match the ground truth occupancies ? m ci . Includes many small objects, we make use of a balanced variant of this loss, which up-weights occupied cells belonging to class c by a constant factor αc:
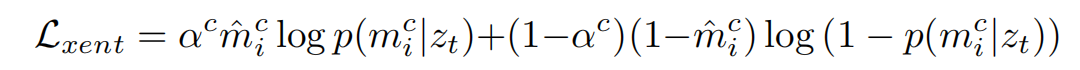
【CC】总体设计还是一个多分类的交叉熵,但是为了处理小物体不均衡的问题加入了αc作为权重因子
To encourage the networks to predict high uncertainty in regions which are known to be ambiguous,we introduce a second loss, which maximises the entropy of the predictions, We apply this maximum entropy loss only to grid cells which are not visible to the network
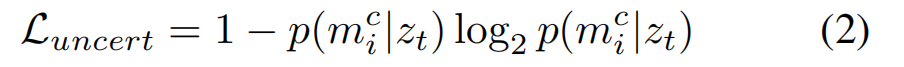
【CC】对于不确定性高的区域,比如遮挡,额外加上这个衡量不确定性的交叉熵;个人比较疑惑,这个loss func的所有项在第一个loss func里面都有,不明白为啥?
The overall loss is given by the sum of the two loss functions
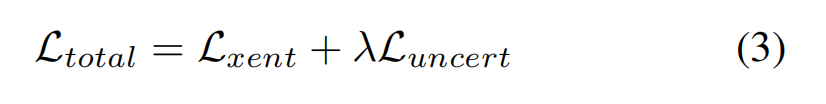
【CC】整个目标函数如上,λ = 0.001
Temporal and sensor data fusion
Consider an image observation zt taken by a camera with extrinsic matrix Mt. We begin by converting our occupancy probabilities p(mci |zt) into a log-odds representation. which conveniently is equivalent to the network’s pre-sigmoid output activations
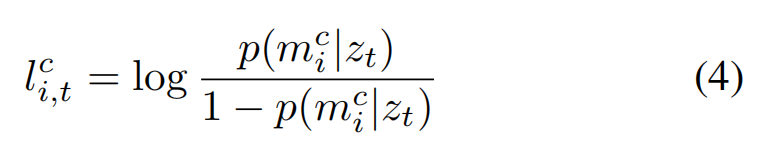
【CC】将后验估加了log,变成了类似sigmoid的形式
The combined log-odds occupancies over observations 1 to t is then given by
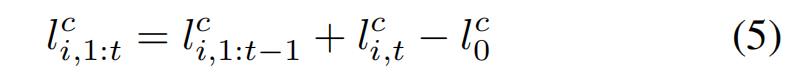
【CC】这里的combine理解成多个sensor更合理一点,参见图一的示意图;还是一个全概率公式,因为加了log形式,其实还是概率相乘
the occupancy probabilities after fusion can be recovered by applying the standard sigmoid function
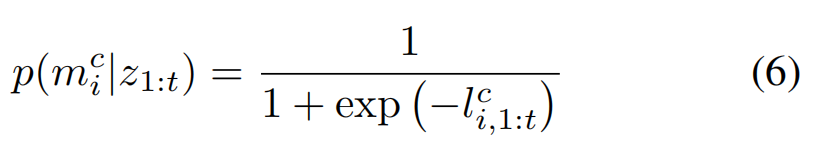
【CC】这里是对公式(4)的倒推,目的是通过sigmoid函数,即L(C, i,1:t),来计算其后验概率
L( c , 0) represents the prior probability of occupancy for class c
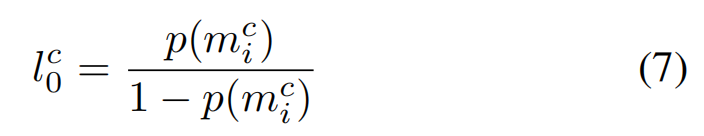
【CC】先验分布,得看代码才知道作者的假设
To obtain the occupancy probabilities in the global coordinate system, we resample the output from our network, which predicts occupancies in the local camera-frame coordinate system, into the global frame using the extrinsics matrix Mt, i.e. p(mi|zt) = fθ(zt, Mt?1xi).
【CC】为了拿到全局坐标系(车辆坐标系)的概率密度,对输入xi前面点乘了Mt的逆,Mt是传感器的外参阵
Dense transformer layer
Our objective is to convert from an image plane feature map with C channels, height H and width W, to a feature map on the birds-eye view plane with C channels, depth Z and width X
【CC】本节的功能就是BEV转换:HWC的图片 -> Z(深度)X(宽)C
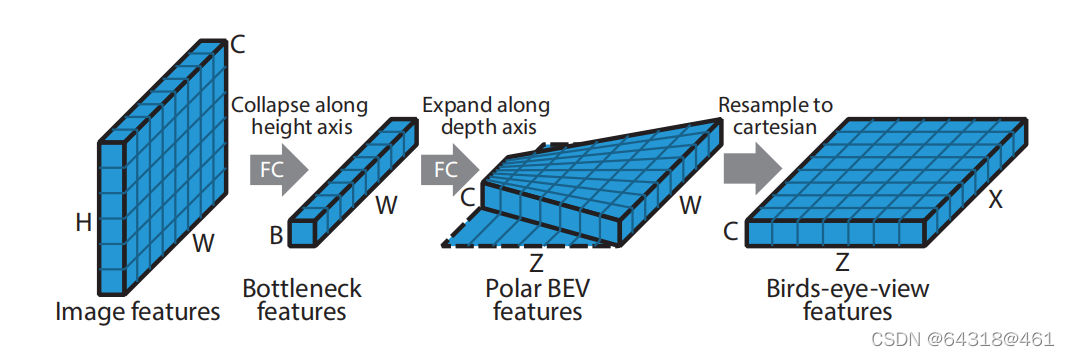
Figure 3. Our dense transformer layer first condenses the imagebased features along the vertical dimension, whilst retaining the horizontal dimension. We then predict a set of features along the depth axis in a polar coordinate system, which are then resampled to Cartesian coordinates.
【CC】首先宽度不变对图片 的纵向(H方向)进行压缩,然后基于车辆坐标原点极坐标系下进行深度方向的预测,最后进行reshape成ZXC的BEV图
Therefore, in order to retain the maximum amount of spatial information, we collapse the vertical dimension and channel dimensions of the image feature map to a bottleneck of size B, but preserve the horizontal dimension W. We then apply a 1D convolution along the horizontal axis and reshape the resulting feature map to give a tensor of dimensions C × Z × W. The final step is to resample into a Cartesian frame using the known camera focal length f and horizontal offset u0
【CC】就是对上面的进一步描述,不再翻译
Multiscale transformer pyramid
a row of grid cells a distance z away from the camera, sampling the polar feature map at intervals of

Δx is the grid resolution and s is the downsampling factor
【CC】根据分辨率,缩放因子对不同尺度的特征图进行采样,这里Δu是采样深度
We therefore propose to apply multiple transformers, acting on a pyramid of feature maps with downsampling factors sk = 2k+3, k ∈ {0, …, 4}.
The kth transformer generates features for a subset of depth values, ranging from zk to zk?1, where zk is given by

Values of zk for a typical camera and grid setting are given in Table 1

【CC】不同尺度的特征图得到不同范围的BEV图
In practice however, we can crop the feature maps to a height
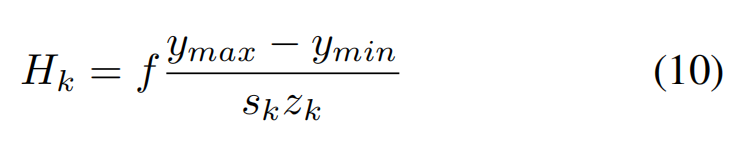
【CC】太高/太矮的特征都不处理,直接裁掉,降低模型参数
对比测试

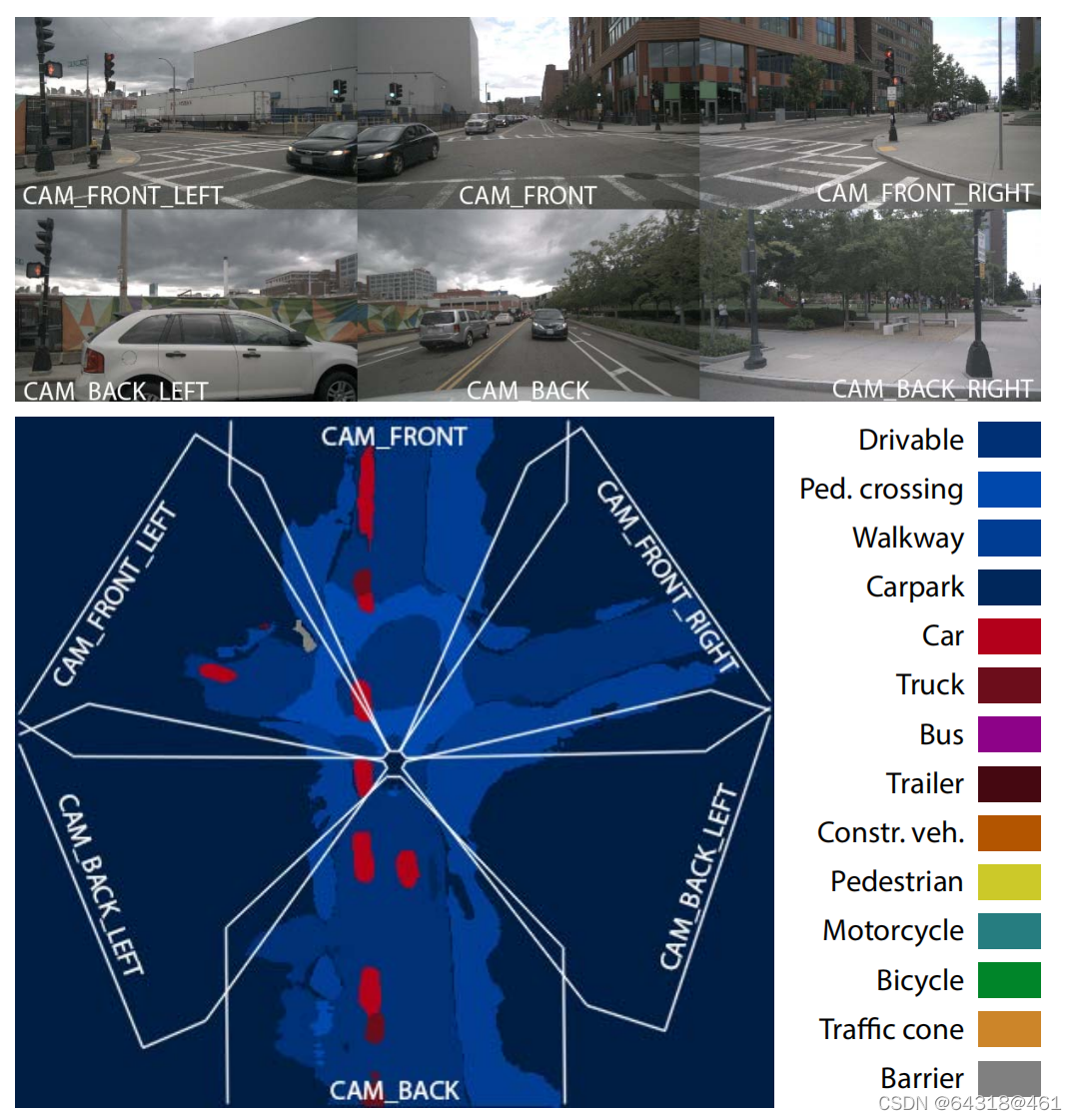
Figure 4. Qualitative results on the Argoverse dataset. For each grid location i, we visualise the class with the largest index c which has occupancy probability p(mci|zt) > 0.5. Black regions (outside field of view or no lidar returns) are ignored during evaluation. for a complete class legend.
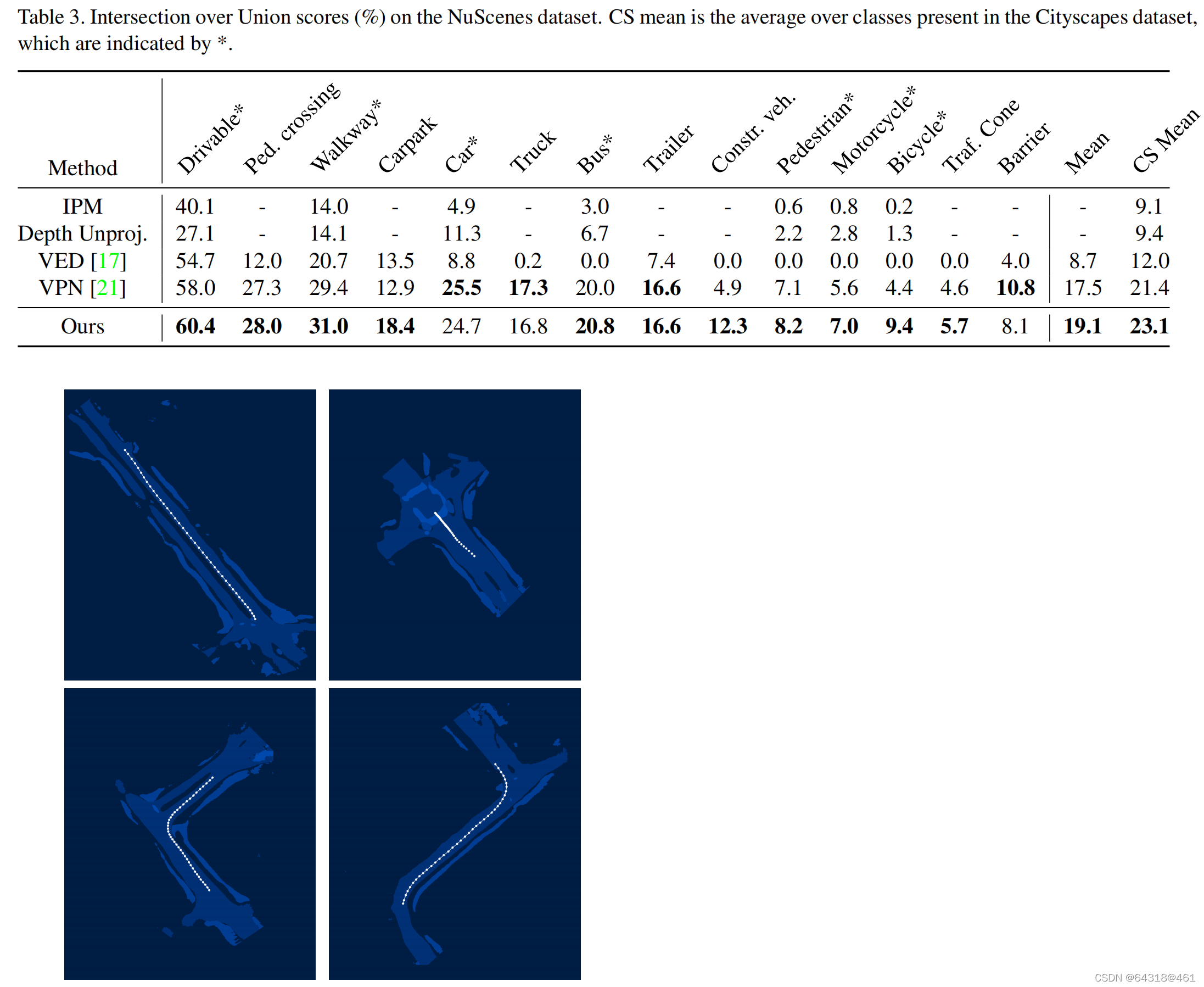
Figure 6. Scene-level occupancy grid maps generated by accumulating occupancy probabilities over 20s sequences. White lines indicate the ego-vehicle trajectory. Note that only static classes(drivable, crossing, walkway, carpark) are visualised.
【CC】虽然这里给了多传感器融合的结果,但是,论文里面没有详细讲解,得看代码里面是怎么做的
源码
https://github.com/tom-roddick/mono-semantic-maps