STUGCN:A Social Spatio-Temporal Unifying Graph Convolutional Network for Trajectory Prediction���ڹ켣Ԥ������ʱ��ͳһͼ��������
Abstract-��̬�����н��������Ĺ켣Ԥ��,Ҳ��Ϊ�켣Ԥ��,������Ӧ�õĹؼ�����,����������ϵͳ���Զ���ʻ����������֮��ĸ��ӽ���,������������ش���ս��Ϊ��Ԥ��δ�������˹켣,���������һ�ֻ���ʱ��ͼ��������ܹ���ʱ��ͳһͼ��������(STUGCN)����ÿ��ʱ�䲽,��ʱ����Ծ���Ӳ����ʱ�ս��������,�ھۺ�������ʱ��ά����,ʹ��ʱ������������������ (TXP-CNN) ��Ԥ�����˵�δ���켣�������Ƚ��ķ������,���ǵ�ģ���������������õ���Ⱥ���ݼ�(ETH �� UCY)����������,��ʵ�������Ƚ�������
1. Introduction
Ԥ������·�����ڰ����Զ���ʻ�����ͼ��ϵͳ���ڵĸ���Ӧ��������Ҫ��ֻ��ȷԤ�����˹켣,�Զ���ʻ��������������Ч�ı�������,��Ϊ���ι켣�滮ģ���ṩ�ؼ���Ϣ[1]��
���������˶��������,����ȷԤ�����˵Ĺ켣�������е���ʮ��·��,������ʱ���ܸı��н�����,���ǵ��ƶ����뿼�ǵ����������˵Ļ���������,ͬ�����ߵ����˿��ܻ���ͬһ�������ƶ�,���˱������������˱��ְ�ȫ���롣
��Ȼ�Ѿ��۲쵽�������ģʽ,�����ѽ�������ȫ�������ڡ��Ѿ�������һЩʵ����ϵͳ��������ģ�������ģ��ʹ���ֹ������������ཻ��,���ֹ����������ڸ��ӵĽ����������ƹ㡣ijЩ��Ʒ�����罻����Ԥ��������Ⱥ�Ĺ켣��
|2-5|�����罻�ز���,������ʹ�����ɶԿ����硣��Щ��������ѭ���ܹ���
��Ϊģ����ύ���仯��ͼ�α�ʾ�� [2, 3] ���,�ǽ�һ�����о��������ǵķ���������һ��,�������з������������������ǵ�Ч�ʡ�
SocialSTGCNN [3] ͨ��ʹ��ͼ������ (GNN) �����ƹ켣����Ϊ����ʱȥ���ռ��ϵ,STGCNN ʹ��ͼ������,Ȼ���� TCN ��ʱ�䶯̬���н�ģ���������ַֽ��ṩ����Ч�ij��ڽ�ģ,�����谭����Ϣ��ʱ���ֱ�������Բ����ӵ�����ռ�ʱ�������ԡ�
**Ϊ�˽����������,���������һ����ӱ�� STUGCN �ܹ�(Spatio-Temporal Unifying Graph Convolutional Network)������������ͳһ�� G3D ͼ����ģ��,��ģ���ܹ���ʽ�ؽ�ģʱ��������ϵ��
G3D ͨ���ڡ�3D��ʱ�����а���ͼ�α�Ե������Ϊ�����谭����Ϣ������Ծ������ʵ����һ��,�����ż���ѧϰ��������ʱ��������ϵ�Ĺ��̡�ʱ������������������ (TXP-CNN) ʹ����� GNN ��������Ϊ����ʱ��ά�ȵ�Ԥ���������**���������ݼ��Ͻ����˹㷺��ʵ��,��ȷ�������ģ�͵���Խ�� ETH [4] �� UCY [5] ,���ǵ�ģ�����������ݼ��϶��ﵽ��������ܡ�
2. Related Works
Human trajectory prediction using deep models.
��Ԥ������켣�����Ѿ���������ʮ����о���Ϊ�˲�����,Social-LSTM [6] ������һ������������������״̬���罻�ء���������һ���뾶�ڵ�������ͬ��Ȩ��,�ڲ�ͬ�ij�����ʹ����ͬ�ijػ���뾶�� SR-LSTM ģ��ʹ�������罻����Ϣ����ǿ����,�����ڴ�����Ϣʱ,ģ�ͻ�����������˵�Ȩ�ء� SceneLSTM[7] ��������˳�����Ϣ�� CIDDN [8] ʹ�ö���֪����ÿ�����˵�λ��ӳ�䵽��ά�����ռ�,����Ϊ�������˷��䲻ͬ��Ȩ�ء� PIF [9] �� Sophie [10] �ӳ�������ȡ�Ӿ���������������ϵ� LSTM ���Խ��г�����֪�켣Ԥ�⡣
STGAT ����ʹ�� LSTM ��ͼע���������������������� Social-BiGAT [2] ��һ������ͼע��������������罻����ģ�͡� Social-BiGAT �� LSTM ������͵�ͼ�С�Ϊ���滻�ۺϲ�,Social-STGCNN ��һ��ʼ�ͽ����˹켣��ģΪʱ��ͼ,��ʹ�û���ŷ����¾���ĺ˺�������ռ�ͼ��Ȼ��,ʹ�� Graph GCN �� TCN,Social-STGCNN ����ʱ��ͼ��
Recent Advances in Convolutional Graph CNNs ����ͼ CNN �����½�չ
ͼ�������� (GCN) ������ڽڵ����Ͷ���ʶ�����,GCN �Ѿ��ڸ���Ӧ���гɹ�ʵ��[11-17]�� GCN ��������ͼƬ�ƹ㵽ͼ��ʹ�û��ھ���IJ�����������ͼ������,Ȼ������Ϊ����ģ�鹹�����յ�ʱ��ͼ��������[3]�� STGCN [18] ��һ����ԵĹ���,ʹ��ʱ��ͼ����������ж���ʶ��2s-AGCN [19] ����ȡ�ռ�����ʱ������ע��������,�����ö�����Ϣ��������ܡ� **MS-G3D [20] ����˿�ʱ����Ծ����������̬ʱ�����Ϲ�ϵ,����ģ��ʹ�ý���ۺϷ���������ͼ������������ϵ��������������Ӧ���ǵ������**�� 3 �ڰ���������Ϣ��
3. THE STUGCN MODEL
��ģ����Ҫ�����������:(1)����Ԥ���ͼ��ʾ,(2)�ռ�ͼ������,�Լ�(3)ʱ������������������ģ�͡�������� STUGCN �����������ͼ1��ʾ ��

A. Graph Representation of Pedestrian Prediction
���ǹ�����һ��ռ�ͼ Gt,��ʾÿ��ʱ�䲽�� t,�����ڳ����е����λ�á�
Gt������Ϊ
G
t
=
{
V
t
,
E
t
}
G_{t}=\left\{V_{t}, E_{t}\right\}
Gt?={Vt?,Et?},
����,
V
t
=
{
v
t
i
�O
?
i
��
{
1
,
��
,
N
}
}
V_{t}=\left\{v_{t}^{i} \mid \forall_{i} \in\{1, \ldots, N\}\right\}
Vt?={vti?�O?i?��{1,��,N}}�dz��������˵Ľڵ㼯����i��������ʱ�䲽��t������������ڽڵ�
v
t
i
v_{t}^{i}
vti?������������.
{
E
t
=
e
t
i
j
�O
?
i
,
j
��
{
1
,
��
,
N
}
}
\left\{E_{t}=e_{t}^{i j} \mid \forall i, j \in\{1, \ldots, N\}\right\}
{Et?=etij?�O?i,j��{1,��,N}}��ͼGt�ı���
e
t
i
j
e_{t}^{i j}
etij?��
v
t
i
v_{t}^{i}
vti?��
v
t
j
v_{t}^{j}
vtj?�м�ıߡ�
Ϊ��ģ�������ڵ��Ӱ��ij̶�,ʹ�ü�Ȩ�ڽӾ��������ڽӾ�������ʹ�÷����ж���� L2 �����ĵ�����������ȷ��������ȡ:
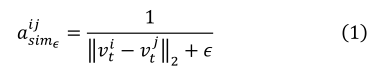
����,����ÿ��ʱ�䲽�� t,���Ƕ��ڽӾ���
A
A
A���й�һ��,��ǰ���� [3][15],�Դٽ�������ȡ:
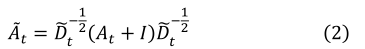
B. Spatial Graph Neural Networks model �ռ�ͼ������ģ��
��ǰ�Ĺ�����ʱ��Ϳռ���Ϣ�ֳ���������,������ͬʱ��ȡ���ǡ�Ϊ�˲�ÿ���ڵ�������ڵ�ǰ������ʱ�䲽�����ھӵ�Ӱ��,���������� G3D:ͳһʱ�ս�ģ��ͨ�������нڵ���ǰһ��ʱ�̺���һ��ʱ����������,G3D �õ�һ��ʱ����ͼ��������ͼ,����ֱ�Ӳ���ÿ���ڵ�����ʱ���ھ�֮�������ԡ�
Cross-Spacetime Skip Connections Ϊ�˽����������֡����Ϣ,�������ȴ���һ��������������֡�����ݵ���ͼ��
G
(
��
)
=
(
V
(
��
)
,
E
(
��
)
)
\mathrm{G}_{(\tau)}=\left(\mathrm{V}_{(\tau)}, \mathrm{E}_{(\tau)}\right)
G(��)?=(V(��)?,E(��)?),����
V
(
��
)
=
V
1
��
?
V
��
\mathrm{V}_{(\tau)} = V1 �� ?V��
V(��)?=V1��?V�� �Ǵ����п�
��
\tau
�� ֡�����нڵ㼯�IJ�����
��ͼ 2�� ������ MS-G3D[19] �е� ? ��ͬ,��ʼ��
E
(
��
)
E(��)
E(��) ��ͨ�������������ռ�ͼ�е�
A
~
?
A~ƽ�̳ɿ��ڽӾ���
A
~
(
��
)
?(��)
A~(��) �������,����
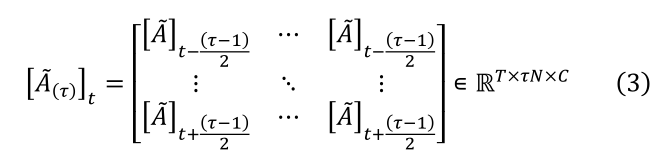
ͨ����ȡ����
(
��
?
1
)
/
2
(��?1) /2
(��?1)/2 �������Ļ����ֲ���,���ǿ��Ժ����ػ��
X
(
��
)
��
R
T
��
��
N
��
C
X(��) �� R ^{T����N��C}
X(��)��RT����N��C��
�ں���������
X
(
��
)
(
l
)
X_{(��)}^{(l)}
X(��)(l)?���ڽӾ���
[
A
(
��
)
]
t
[A_{(��)}]_t
[A(��)?]t?,�������ڵ�ͼ���������ʾΪ:
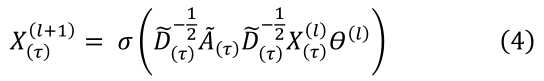

ͼ 2 ��ʱ����Ծ����ʾ��(��)�� G3D ģ�͵��ڽӾ���
C. Time-Extrapolator Convolution Neural Network model
TXP-CNN ּ��ͨ�� GCN �Ľ������δ���켣��������������˶���������������ͨ�������罻����������ֱ�Ӷ� v s t v_{st} vst?���о�������,�ٴεõ����вв�ܹ���Ԥ��켣,��:
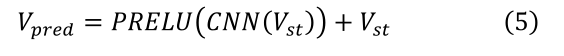
ֵ��ע�����,�ڵ�һ��TXP-CNN��,������Ҫ����һά v s t v_{st} vst?�� T o b s t o T p r e d T_{obs}toT_{pred} Tobs?toTpred?����Ҫ�������֡��
IV. EXPERIMENT
A. Dataset and Metrics
ʹ���������������ݼ� ETH [4] �� UCY [5] �ڸò����в�����������ķ������������ݼ�������ÿ 0.4 ��ɼ�������,���� 8 �롣Ϊ�˱����������������бȽ�,������ķ�����ʵ�������� Social-LSTM[6] �� Graves [25] ��������ͬ����������������������,����Ƶ��Ϊ 0.4s,ǰ 8 ֡�����۲쵽����ʷ�켣,���� 12 ֡��������Ԥ�����ʵ�켣��ʹ�����������õIJ���ָ��:ƽ��λ����� (ADE) [26] ������λ����� (FDE) [6]�� ADE �ع켣ƽ������Ԥ�⾫��,�� FDE �����Ƕ˵��Ԥ�⾫��
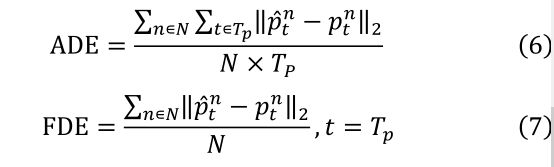
B. Implementation Details
Ϊ��ʵ�������������,ʹ���� PyTorch �����ѧϰ��ܡ� Social-STGCNN ���� ST-GCNN �� TXP-CNN �ֲ㹹���ġ� PRELU [27] �����ǵ�ģ������������������ǵ������о�����,ʹ�õ����ģ����һ�������������� TXP-CNN ����ɡ�Ϊ���Ż�ģ��,����ʹ���� 128 �� epoch ��ѵ��������С,��ʹ������ݶ��½����� 0.001 �ij�ʼѧϰ�ʶ�������� 250 �� epoch ��ѵ����
C. Ablation study
�����ڱ�����Ϊһ�㡢���������ʱ������ADE/FDE�� 'Table 2����ʾSTGCN��G3D����1��ʱЧ����á��������ͼ���������в�������ʱ���ֵĹ���ƽ�������йء�

. STUGCN �����ڷ�������һ�б�ʾ������������������������Ϊ ST-GCNN �� G3D ʹ�õ���
D. Comparison with the State-of-the-art Methods
a) �����ٶȺ�ģ�ʹ�С:Socail-STGCNN �IJ�����Ϊ 7.6K�������ǵİ�����,ģ�Ͳ����������Ըߡ�������Ϊ���������˿�ʱ�����ӡ����� stgcnn ֮��,��С�IJ������� s-gan�����IJ�����Ϊ 46.3k,�����ǵIJ�����,�硰�� 3����ʾ,�������ķ�֮һ��
�������ٶȷ���,���ǵ�ģ���� Social-STGCNN �൱,�ﵽ���Ƚ�ˮƽ��

b) STUGCN �� ADE/FDE:�硰�� 1����ʾ,����ķ����� ETH �� UCY ���ݼ��ϵ� ADE/FDE ָ����������Ƚ����������˱Ƚϡ�������� STUGCN �����п��Կ���,��������µ�Ч��,���� FDE �����������е�ǰ���Ƚ��ķ�����������ڰ�����ʱ���������ӡ��� FDE ָ�귽��,������ķ���ʵ���� 0.72 �����,�������ģ�ͼ����� 23%���� ADE ָ�귽��,�÷��������� SR-LSTM-2 �Դ� 4%������Ҳ�Ǹ��õı���֮һ����ֵ��ע�����,�������ʹ��ͼ����Ϣ�Ĺ���,���粻ʹ�ó���ͼ����Ϣ�� PIF��SR-LSTM �� Sophie��

V. CONCLUSION
�ڱ�����,�����һ���µ� STUGCN ���˹켣Ԥ�ⷽ������ѧϰ���д����ԡ�³���Ժ��б��Ե�ͼǶ�롣��������ķ�����,��ʱ����Ծ��������ͬʱֱ�Ӳ���ֲ�ʱ������ԡ��� ETH �� UCY ���ݼ��ϵ�ʵ��������,������ķ�����Ԥ�����˹켣������������������δ���Ĺ����������ڽ� STUGCN ��չ��������ͨ����,���������������г����ˡ������ȡ�����,������Ŭ����������ֹ���ģʽ�Ľ��������