Abstract & Introduction & Related Work
- �����
- ʵ���ϵ��ȡ
- ���з�������ع���
- �ṹ��Ԥ��,��������ʹ��ͬһ���
- ������ѧϰ,
- ������ս
- ��������,����һֱ��Ϊ����ģ�Ϳ��Ը��õز�ʵ���ϵ֮��������,�������ڻ����������
- ����˼·
- ���ǵķ����������ǽ��������������ı�������,ֻ��ʹ��ʵ��ģ����������ϵģ�͵�����
- ͨ��һϵ����ϸ�ļ��,������֤��Ϊʵ���ϵѧϰ��ͬ�������ı�������Ҫ��,�ڹ�ϵģ�͵������ں�ʵ����Ϣ,������ȫ��������
- ʵ�����
- ��ACE04��ACE05�ϴﵽsota
Method
Our Approach
��ͼ1��ʾ,���ǵķ�����һ��ʵ��ģ�ͺ�һ����ϵģ����ɡ�ʵ��ģ�����Ƚ�������ľ���,��Ԥ��ÿ������span��ʵ������(��)��Ȼ��,�����ڹ�ϵģ���ж�������ÿһ�Ժ�ѡʵ��,�������ı�DZ��,��ͻ������ͱ��P�����͡����ǽ���������ϸ����ÿ�����,����ܽ����ǵķ�����DYGIE++֮��IJ���

Entity model
���Ļ���span��ģ��

Relation model
��ϵģ��ּ�ڽ�һ��span
s
i
,
s
j
s_i , s_j
si?,sj?(һ�������һ������)��Ϊ����,��Ԥ���ϵ���ͻ� ��ǰ�ķ�������ʹ�ÿ�ȱ�ʾ
h
e
(
s
i
)
\mathbf{h_e(s_i)}
he?(si?),
h
e
(
s
j
)
\mathbf{h_e(s_j)}
he?(sj?)��Ԥ��
s
i
s_i
si? ��
s
j
s_j
sj? ֮��Ĺ�ϵ�����Ǽ�����Щ����ֻ������ÿ������ʵ����Χ����������Ϣ,�������������span֮���������ϵ�����ǻ���Ϊ,�ڲ�ͬ��span��֮�乲�������ı�ʾ�����Ǵ��ŵġ�����,ͼ1�еĵ���is a��������MORPA��PARSER֮��Ĺ�ϵ������Ҫ,������MORPA��TEXT-TO-SPEECH��Ȼ

���ǵĹ�ϵģ�ͷ��������ش���ÿһ�Կ��,���������������ͱ��,��ͻ������Ϳ��弰������

��ʶ���span��

concat����,Ȼ������һ��ȫ���Ӳ���Ԥ����ֹ�ϵ�ĸ���

���Ƿ���,�������ע��������Ϣ��������ʵ�����ͷdz��а����C����,����ͼ�����ϵ֮ǰ,"��ʿ�� "��ָһ���˻���һ����֯
Cross-sentence context
�������Ϣ�����ڰ���Ԥ��ʵ�����ͺ�ϵ,�ر��ǶԴ��ʵ��ἰ�����ô������������������ᄈ��Wadden����(2019)��������һ��3�仰���ᄈ����,�ⱻ֤������������ܡ����ǻ������������ǵķ��������ÿ�����ᄈ����Ҫ�ԡ�������������Ԥѵ��������ģ���ܹ��������������ϵ,����ֻ��ͨ����������չ��ʵ���ϵģ�͵Ĺ̶����ڴ�СW�����������ᄈ��������˵,����һ����n���ʵ��������,���Ƿֱ������ᄈ���ұ��ᄈ������ ( W ? n ) / 2 (W-n)/2 (W?n)/2 ���ʵ�����
Training & inference
ʹ��������������ʧ����
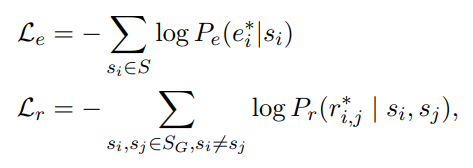
ö�����е�span������relationģ�͵���ʧ

Differences from DYGIE++
���ǵķ�����DYGIE++(Luan����,2019;Wadden����,2019)�����²�֮ͬ����
(1) ���Ƕ�ʵ���ϵģ��ʹ�õ����ı�����,û���κζ�����ѧϰ��Ԥ���ʵ�����ͱ�ֱ�����ڹ�����ϵģ�͵����롣
(2) ͨ��ʹ���ı����,��ϵģ���е������ı�ʾ�����ÿһ�Կ�ȵġ�
(3) ����ֻͨ���ö������������չ����������������Ϣ(������������),���Dz������κ�ͼ�������beam search������������ʵ��������ʾ��(��4��),�������еĻ���Ҳȡ���˺ܴ�Ľ���,ʹ�õ�����ͬ��Ԥѵ��������
Efficient Batch Computations
���ǵķ�����һ�����ܵ�ȱ����,������ҪΪÿһ��ʵ������һ�����ǵĹ�ϵģ�͡�Ϊ�˻����������,���������һ����ӱ����Ч��������ǵĹ�ϵģ�͵ķ������ؼ�������,����ϣ����ͬһ�����еIJ�ͬ��ȶԽ����ظ�ʹ�ü��㡣��������ԭ����ģ�����Dz����ܵ�,��Ϊ���DZ���Ϊÿ�Կ�ȶ�������ʵ���ǡ�Ϊ��,���������һ������ģ��,��ԭ���Ĺ�ϵģ������������Ҫ�ĸı䡣����,���Dz�ֱ����ԭ���в���ʵ����,���ǽ���ǵ�λ��Ƕ������Ӧ��ȵĿ�ʼ�ͽ��������ϵ����

�ڶ�,���Ǹ�ע������������һ��Լ������������ǿ���ı����ֻ��ע�ı����,����ע��DZ��,��ʵ���DZ�ǿ��Թ�ע���е��ı���Ǻ���ͬһ��ȶ���ص�����4����DZ�ǡ���������ʹ�����ܹ�����ʹ�������ı���ǵļ���,��Ϊ�ı���ǵı�ʾ�Ƕ�����ʵ���DZ�ǵġ����,���ǿ����ڹ�ϵģ�͵�һ�������ж�ͬһ�����еĶ�Կ�Ƚ������С���ʵ����,���ǽ����еı�DZ�����ӵ����ӵ�ĩβ,�γ�һ����������ȶԵ�����(ͼ1(c))�����������ʱ��Ĵ������,�����ܽ���С���½�(��4.3��)
Experiments






Conclusion
�ڱ�����,���������һ�ּ���Ч�Ķ˵��˹�ϵ��ȡ���������ǵ�ģ�Ͷ�����ѧϰ������ʵ��ʶ���ϵ��ȡ������������,���ǵ�ʵ�����,�����������Ļ��ϴ��س�������ǰ�ļ���ˮƽ�����ǽ����˹㷺�ķ���,���˽����Ƿ�������Խ����,����֤��Ϊʵ���ϵѧϰ��ͬ�������ı�ʾ����Ҫ��,�Լ���ʵ����Ϣ��Ϊ��ϵģ�͵��������������ǻ������һ����Ч�Ľ��Ʒ���,������ʱ����˺ܴ���ٶ�,��ȷ��ȴ��С���½�������ϣ�������ģ���ܹ���Ϊһ���dz�ǿ��Ļ���,��ʹ��������˼���˵��˹�ϵ��ȡ������ѵ���ļ�ֵ
Remark
����Ч,�Ǿ��Ǻ�����!