����Ŀ¼
1. ��������
(1)����
һ���,һ�þ���������һ�����ڵ㡢�����ڲ��ڵ��Ҷ�ڵ㡣
- Ҷ�ڵ�:��Ӧ���߽����
- ���ڵ���м�ڵ�:�������Բ��ԵĽ���������������ֵ����ӽڵ��С�
(2)�����������㷨
��������������һ���ݹ���̡�
- ��ÿ�εݹ���,�����ж��Ƿ�ﵽ�ݹ鷵������,���Ҷ�ڵ㡣
- ѡ�����Ż��ֽڵ㡣
- ���ݽڵ�����Բ��Խ�����������������ֵ��ӽڵ㡣
- ���ӽڵ�Ϊ�������ڵ�,����ǰ���Ż�������,���þ��������ɺ�����

(3)���ֵݹ鷵�����
- ��ǰD����������������ͬһ���Cʱ:
��Node���Ϊ����ΪC��Ҷ�ڵ㡣 - ��ǰ���Լ�AΪ��:
����ͶƱ,��Node���Ϊ��ǰ��������D�������������Ҷ�ڵ㡣 - ��ǰ������DΪ��
��Node���Ϊ�丸�ڵ������������������Ҷ�ڵ㡣
2. ����ѡ��
����ϣ�����Ż��ֵIJ��Ͻ���,�������ķ�֧�ڵ�Ĵ���Խ��Խ��,��֧�ڵ�����������������������ͬһ���
| ���� | ȱ�� | ���� | ���� |
|---|---|---|---|
| ��Ϣ���� | �Կ�ȡֵ��Ŀ�϶����������ƫ�� | ID3 | ѡ����Ϣ������������ |
| ��Ϣ������ | �Կ�ȡֵ��Ŀ�϶����������ƫ�� | C4.5 | �Ӻ�ѡ���������ҳ���Ϣ�������ƽ��ˮƽ������,�ٴ���ѡȡ��������� |
| ����ָ�� | CART | ѡ�ֺ����ָ����С������ |
2.1 ��Ϣ����(information gain)
(1)��Ϣ��
��Ϣ��(information entropy)�Ƕ�������������õ�һ��ָ�ꡣ
E
n
t
(
D
)
=
?
��
k
=
1
�O
��
�O
p
k
log
?
2
p
k
Ent(D)=-\sum_{k=1}^{|\gamma|} p_k \log_2 p_k
Ent(D)=?k=1���O���O?pk?log2?pk?
����: E n t ( D ) Ent(D) Ent(D)ֵԽС,����ֵԽС,����Խ�ߡ�
- ���赱 p k = 0 p_k=0 pk?=0ʱ, p k log ? 2 p k = 0 p_k \log_2 p_k =0 pk?log2?pk?=0��
- �� p k = 1 p_k=1 pk?=1ʱ, E n t ( D ) Ent(D) Ent(D)ֵ��СΪ0���� p k = 1 �O �� �O p_k=\frac{1}{|\gamma|} pk?=�O���O1?ʱ,�����������1:1�ֲ�ʱ, E n t ( D ) Ent(D) Ent(D)ֵ���Ϊ1.
����: ��Ϣ�����ڶ���ijһ������D�Ĵ��ȡ�ֻҪ�����������Ϳ��Լ������Ӧ����Ϣ�ء�
(2)��Ϣ����(information entropy)
������ɢ����
��
\alpha
����
V
V
V�����ܵ�ȡֵΪ
{
a
1
,
a
2
,
?
?
,
a
V
}
\{a_1,a_2,\cdots,a_V\}
{a1?,a2?,?,aV?},��
��
\alpha
���������,�����
V
V
V����֧�ڵ㡣���е�v����֧�ڵ������D������������
��
\alpha
����ȡֵΪ
a
v
a_v
av?������,��Ϊ
D
v
D^v
Dv��
���Լ����������
��
\alpha
��������D���л������õ�����Ϣ����:
G
a
i
n
(
D
,
��
)
=
E
n
t
(
D
)
?
��
i
=
1
V
�O
D
i
�O
�O
D
�O
E
n
t
(
D
i
)
Gain(D,\alpha)=Ent(D)-\sum_{i=1}^V \frac{|D^i|}{|D|}Ent(D^i)
Gain(D,��)=Ent(D)?i=1��V?�OD�O�ODi�O?Ent(Di)
����, �O D i �O �O D �O \frac{|D^i|}{|D|} �OD�O�ODi�O?Ϊ�÷�֧�ڵ� a i a_i ai?��Ȩ��,������Խ���֧�ڵ��Ӱ��Խ��
- ��Ϣ���� = ����ǰ����Ϣ�� - ���ֺ����֧�ڵ���Ϣ�صļ�Ȩ�͡�
- һ�����,��Ϣ����Խ��,����ζ��ʹ�� �� \alpha �������л�������õĴ�������Խ��
(3)ʵ������
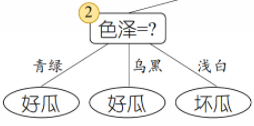
��ɫ������Ϊ��,���㰴ɫ�ֺ����Ϣ����:
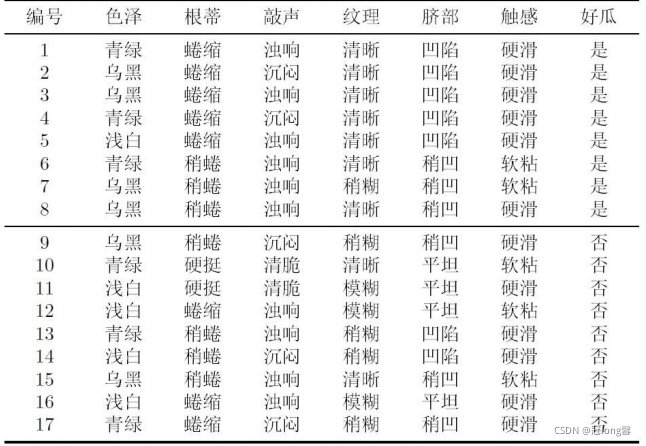
- ���㻮��ǰ������D����Ϣ��
E n t ( D ) = 8 17 l o g 2 8 17 + 9 17 l o g 2 9 17 = 0.998 Ent(D)=\frac{8}{17}log_2\frac{8}{17}+\frac{9}{17}log_2\frac{9}{17}=0.998 Ent(D)=178?log2?178?+179?log2?179?=0.998 - ������ɫ��Ϊ����,������Ϣ���档
�ٶ�Ӧ�������Ӽ��ֱ�Ϊ D 1 �� �� = { 1 , 4 , 6 , 10 , 13 , 17 } , D 2 �� �� = { 2 , 3 , 7 , 8 , 9 , 15 } , D 3 dz �� = { 5 , 11 , 12 , 14 , 16 } D^{1����}=\{1,4,6,10,13,17\},D^{2�ں�}=\{2,3,7,8,9,15\},D^{3dz��}=\{5,11,12,14,16\} D1����={1,4,6,10,13,17},D2����={2,3,7,8,9,15},D3dz��={5,11,12,14,16}
�ڼ�����ӽڵ����Ϣ��:
E n t ( D 1 ) = 1 E n t ( D 2 ) = ? ( 2 3 l o g 2 2 3 + 1 3 l o g 2 1 3 ) = 0.918 E n t ( D 3 ) = ? ( 1 5 l o g 2 1 5 + 4 5 l o g 2 4 5 ) = 0.722 Ent(D^1)=1 \\ Ent(D^2)=-(\frac{2}{3}log_2\frac{2}{3}+\frac{1}{3}log_2\frac{1}{3})=0.918 \\ Ent(D^3)=-(\frac{1}{5}log_2\frac{1}{5}+\frac{4}{5}log_2\frac{4}{5})=0.722 Ent(D1)=1Ent(D2)=?(32?log2?32?+31?log2?31?)=0.918Ent(D3)=?(51?log2?51?+54?log2?54?)=0.722
�ۼ�����Ϣ����:
G a i n ( D , �� ) = 0.998 ? ( 6 17 �� 1 + 6 17 �� 0.918 + 5 17 �� 0.722 ) = 0.109 Gain(D,\alpha)=0.998-(\frac{6}{17}\times 1+\frac{6}{17} \times 0.918+\frac{5}{17} \times 0.722)=0.109 Gain(D,��)=0.998?(176?��1+176?��0.918+175?��0.722)=0.109
(4)ȱ��
��Ϣ����Կ�ȡֵ��Ŀ�϶����������ƫ�á�
2.2 ��Ϣ������
(1)����
G
a
i
n
_
r
a
t
i
o
n
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
I
V
(
a
)
=
?
��
v
=
1
V
�O
D
v
�O
�O
D
�O
l
o
g
2
�O
D
v
�O
�O
D
�O
Gain\_ration(D,a) = \frac{Gain(D,a)}{IV(a)} \\ IV(a)=-\sum_{v=1}^{V}\frac{|D^v|}{|D|} log_2 \frac{|D^v|}{|D|}
Gain_ration(D,a)=IV(a)Gain(D,a)?IV(a)=?v=1��V?�OD�O�ODv�O?log2?�OD�O�ODv�O?
����, I V ( a ) IV(a) IV(a)Ϊ����a�Ĺ̶�ֵ������a�Ŀ���ȡֵ��ĿԽ��(VԽ��),��IV(a)��ֵͨ��Խ��
(2)ȱ��
��Ϣ�����ʶԿ�ȡֵ��Ŀ���ٵ���������ƫ�á�
(3)C4.5����ʽ�㷨
�ȴӺ�ѡ���������ҳ���Ϣ�������ƽ��ˮƽ������,�ٴ���ѡȡ����������ġ�
����: ��Ϣ����������Ϣ����Ļ����ϳ��������ԵĹ̶�ֵ,���������Կ�ȡֵ��Ŀ�϶����Ե�ƫ�á����ǹ̶�ֵ�ij���,Ҳ������Ϣ�����ʶԿ�ȡֵ��Ŀ���ٵ���������ƫ�á�
2.3 ����ָ��
(1)����ֵ
���ݼ�D�Ĵ��ȿ��á�����ֵ��������������ֵ��Ӧ�˴�D�������ȡ��������,������Dz�һ�µĸ�����
G
i
n
i
(
D
)
=
1
?
��
k
=
1
�O
y
�O
p
k
2
Gini(D)=1-\sum_{k=1}^{|y|}p_k^2
Gini(D)=1?k=1���Oy�O?pk2?
- Gini(D)ԽС,���ݼ�D�Ĵ���Խ��
(2)����ָ��
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
=
��
v
=
1
�O
V
�O
�O
D
v
�O
�O
D
�O
G
i
n
i
(
D
v
)
a
?
=
arg
?
min
?
a
��
A
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
Gini\_index(D,a)=\sum_{v=1}^{|V|}\frac{|D^v|}{|D|}Gini(D^v) \\ a_* = \arg \min_{a \in A} Gini\_index(D,a)
Gini_index(D,a)=v=1���OV�O?�OD�O�ODv�O?Gini(Dv)a??=arga��Amin?Gini_index(D,a)
- ѡ�ֺ����ָ����С��������Ϊ���Ż������ԡ�
3. ��֦
������ѵ��������,Ϊ�˾�������ȷ����ѵ������,�ڵ㻮�ֹ��̲����ظ�,��ʱ����ɾ�������֧��������¹���ϡ���˿����ù�����ȥ��һЩ��֧��������ϵķ��ա�
��������֦�Ļ��������С�Ԥ��֦���͡����֦����
- Ԥ��֦:ÿ���ڵ��ڻ���ǰ�Ƚ��й��ơ�����ǰ�ڵ�Ļ��ֲ��ܴ����������ܵ�����,��ֹͣ���ֲ����ڵ㵱��Ҷ�ڵ㡣
- ���֦:�ȴ�ѵ��������һ�������ľ�����,Ȼ���Ե����ϵضԷ�Ҷ�ڵ���п��졣�����ڵ��Ӧ�������滻��Ҷ�ڵ��ܶԾ����������������ܵ�����,�������滻ΪҶ�ڵ㡣
| �ŵ� | ȱ�� | |
|---|---|---|
| Ԥ��֦ | 1.��������ѵ��ʱ��Ͳ���ʱ�俪����2. ������Ϸ��� | Ƿ��Ϸ��� |
| ���֦ | 1.Ƿ��Ϸ���С��2. ����������������Ԥ��֦ | ѵ��ʱ�俪���� |
3.1 ������֤��
���Բ���������,Ԥ��һ��������������֤��,�Խ�������������
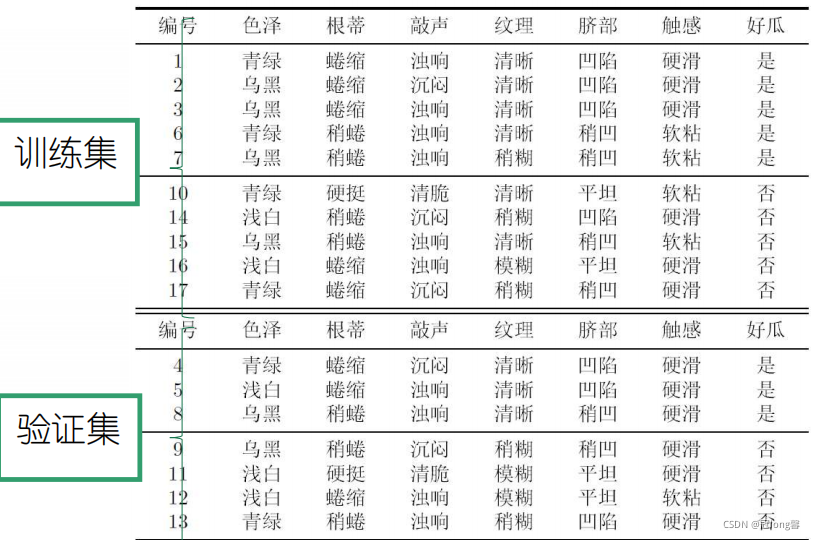
- ѵ����{1,2,3,6,7,10,14,15,16,17}
- ��֤��{4,5,8,9,11,12,13}
3.2 Ԥ��֦
(1)˼·
�����ֽڵ�ǰ�Ƚ�������������ǰ�ڵ㻮�ֲ��ܴ����������ܵ�����,��ֹͣ���ֲ�����ǰ�ڵ㵱��Ҷ�ڵ㡣
(2)����
- Step1: ���㽫�ڵ㵱��Ҷ�ڵ�ʱ����֤���ϵľ���pre1��
- Step2: ����ڵ㻮�ֺ�����֤���ϵľ���pre2��
- Step3: �� p r e 2 > p r e 1 pre2 > pre1 pre2>pre1,�������ܴ����������ܵ����,���յ�ǰ���Ի��֡�����,��ȡ����ͶƱ���ڵ㿴��Ҷ�ڵ㡣
(3)��������
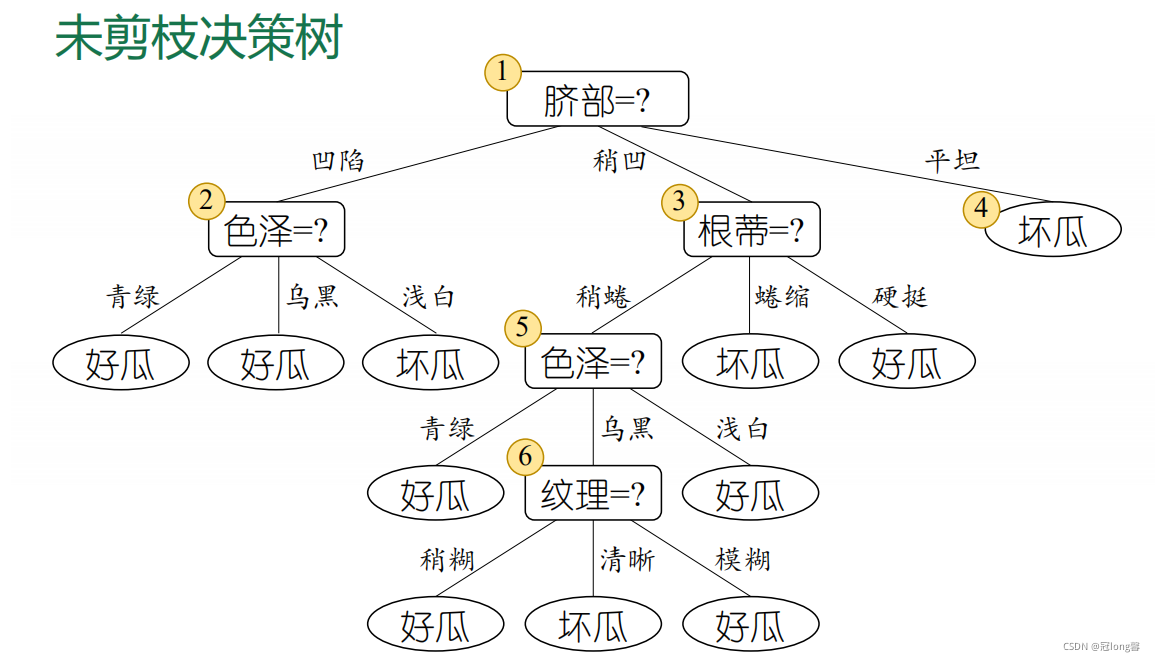
- �������겿����,��������ΪҶ�ڵ�:
�� ���ݵ�ǰ�ڵ��������,���б��Ϊ�ùϵĸ������ڻ��ϵ���Ŀ 5 > 4 5>4 5>4,��Ҷ�ڵ������Ϊ�ùϡ�
�� ��֤����{4,5,8}������ȷ,��֤������Ϊ 3 7 ? 100 = 42.9 % \frac{3}{7} *100 =42.9 \% 73??100=42.9% - �����겿���л���,���ֽ������:
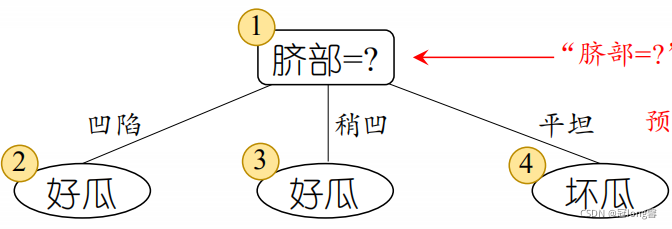
��ʱ,��֤����{4,5,8,11,12}������ȷ,��֤������Ϊ: 5 7 �� 100 = 71.4 % \frac{5}{7} \times 100 = 71.4 \% 75?��100=71.4% - ���ֺ���֤���ľ�������,�����겿���л��֡�
���겿Ϊ���ݵ���������Ԥ��֦�ж�:
����ѡ�����ɫ��Ϊ����ѻ������ԡ�
-
������ɫ��,��������ΪҶ�ڵ�:
�� ���ݵ�ǰ�ڵ��������,���б��Ϊ�ùϵĸ������ڻ��ϵ���Ŀ 3 > 1 3>1 3>1,��Ҷ�ڵ������Ϊ�ùϡ�
��ʱ,��֤����{4,5,8,11,12}������ȷ,��֤������Ϊ: 5 7 �� 100 = 71.4 % \frac{5}{7} \times 100 = 71.4 \% 75?��100=71.4% -
����ɫ����л���,���ֽ������:
��ʱ,��֤����{4,8,11,12}������ȷ,��֤������Ϊ: 4 7 �� 100 = 57.1 % \frac{4}{7} \times 100 =57.1 \% 74?��100=57.1% -
���ֺ���֤���ľ��Ƚ���,�ʽ����ݽڵ㵱����ǩΪ�ùϵ�Ҷ�ڵ㡣
(4)��ȱ��
�ŵ�
- ������Ϸ���
- ��������ѵ��ʱ��Ͳ���ʱ�俪��
ȱ��
- Ƿ��Ϸ���
��Щ��֧��ǰ������Ȼ����������������,����������Ͻ��еú�������ȴ�п��ܵ�������������ߡ�
3.3 ���֦
(1)˼��
�ȴ�ѵ��������һ�������ľ�����,Ȼ���Ե����ϵضԷ�Ҷ�ڵ���п��졣�����ڵ��Ӧ�������滻��Ҷ�ڵ��ܶԾ����������������ܵ�����,�������滻ΪҶ�ڵ㡣
(2)����
- Step1: ��ѵ��������һ�������ľ�������
- Step2: �Ե����϶Է�Ҷ�ڵ㿼��,���㽫�ڵ��Ӧ�����滻��Ҷ�ڵ������֤���ϵľ�ȷ�ȡ�
- Step3: ���滻������,�������滻ΪҶ�ڵ㡣
(3)��������
����������֤���ϵľ���Ϊ{4��11��12}:
3
/
7
=
42.9
%
3 / 7 = 42.9 \%
3/7=42.9%
- ���ǽڵ�ޡ��ڵ����������Ϊ�������顢�ںڡ�D={7��15}.�����滻ΪҶ�ڵ�,�ڵ��ǩΪ�ùϡ���ʱ,����������֤���ϵľ���Ϊ{4��8��11��12}:
4 7 = 57.1 % \frac{4}{7}=57.1\% 74?=57.1% - �滻ΪҶ�ڵ��,��֤���Ͼ������������Ǿ�����֦����֦��ľ�������ͼ:

(4)��ȱ��
�ŵ�
- Ƿ��Ϸ���С��
- ����������������Ԥ��֦��
ȱ��
- ѵ��ʱ�俪����
3.4 Ԥ��֦�ͺ��֦��ѡ��
Ԥ��֦����������ѵ��ʱ�䲢��������,������Ƿ��ϵķ��ա����֦ѵ��ʱ�俪���ϴ�,����������������ǿ����˵õ����½���:
- �� ��������Сʱ ==> ���֦
- �� �������ϴ�ʱ ==> Ԥ��֦
4. ������ȱʧֵ
4.1 ����ֵ����
��Ϊ�������ԵĿ���ȡֵ��������,��˲���ֱ�Ӹ����������ԵĿ���ȡֵ�Խڵ���л��֡���õIJ��������ַ����������Խ��д�����
(1)���ַ�
����������D����������a,�ٶ�a��D�ϳ�����n����ͬ��ȡֵ,����Щֵ��С�����������,��Ϊ
a
1
,
a
2
,
?
?
,
a
n
{a^1,a^2,\cdots,a^n}
a1,a2,?,an�����ڻ��ֵ�t�ɽ�D��Ϊ�Ӽ�
D
t
?
,
D
t
+
D_t^-,D_t^+
Dt??,Dt+?��
- ������������,���ǿ��ǰ��� n ? 1 n-1 n?1��Ԫ�صĺ�ѡ���ֵ㼯��:
T a = { a i + a i + 1 2 �O 1 �� i �� n ? 1 } T_a=\{\frac{a_i+a_{i+1}}{2}|1 \leq i \leq n-1 \} Ta?={2ai?+ai+1??�O1��i��n?1}
- Ȼ��ѡȡ���ŵĻ��ֵ�����������ϻ���:
G a i n ( D , a ) = max ? t �� T a G a i n ( D , a , t ) G a i n _ i n d e x ( D , a ) = max ? t �� T a G a i n _ i n d e x ( D , a , t ) G i n i _ i n d e x ( D , a ) = min ? t �� T a �� v = 1 �O V �O �O D v �O �O D �O G i n i ( D v , t ) Gain(D,a) = \max_{t \in T_a}Gain(D,a,t) \\ Gain\_index(D,a) = \max_{t \in T_a} Gain\_index(D,a,t) \\ Gini\_index(D,a)=\min_{t \in T_a} \sum_{v=1}^{|V|}\frac{|D^v|}{|D|}Gini(D^v,t) Gain(D,a)=t��Ta?max?Gain(D,a,t)Gain_index(D,a)=t��Ta?max?Gain_index(D,a,t)Gini_index(D,a)=t��Ta?min?v=1���OV�O?�OD�O�ODv�O?Gini(Dv,t)
ע��
- ����ǰ�ڵ㻮������Ϊ��������,�����Ի�����Ϊ����ڵ�Ļ������ԡ�
4.2 ȱʧֵ����
���ط�������������,��ʹ����ȱʧֵ����������ѧϰ,�Ƕ�������Ϣ������˷ѡ�����ȱʧֵ,������Ҫ�����������:
- ���������ȱʧ������½�����������ѡ����
- ������������,�������������ϵ�ֵȱʧ,������������л�����
����:��ν����������ѡ������������������⡣
(1)����
����ѵ����
D
D
D������a��
- �� D ^ \hat{D} D^��ʾD��������a��û��ȱʧֵ�������Ӽ���
- �� D ^ v \hat{D}^v D^v��ʾ D ^ \hat{D} D^������a��ȡֵΪ a v a^v av�������Ӽ���
- �� D ^ k \hat{D}_k D^k?��ʾ D ^ \hat{D} D^�����ڵ�k��( k = 1 , 2 , ? ? , �O �� �O k=1,2,\cdots,|\gamma| k=1,2,?,�O���O)�������Ӽ���
- �ٶ�Ϊÿ������x����һ��Ȩ�� w x w_x wx?,��ʼ��Ϊ1.
- ��ȱʧֵ������ռ����
��
\rho
��:
�� = �� x �� D ^ w x �� x �� D w x \rho = \frac{\sum_{x \in \hat{D}}w_x}{\sum_{x \in D}w_x} ��=��x��D?wx?��x��D^?wx?? - ��ȱʧ�����е�k����ռ�ı���
p
k
^
\hat{p_k}
pk?^?:
p k ^ = �� x �� D ^ k w x �� x �� D ^ w x \hat{p_k} = \frac{\sum_{x \in \hat{D}_k}w_x}{\sum_{x \in \hat{D}}w_x} pk?^?=��x��D^?wx?��x��D^k??wx?? - ��ȱʧ������������a��ȡֵΪ
a
v
a^v
av��������ռ����
r
v
^
\hat{r_v}
rv?^?:
r v ^ = �� x �� D ^ v w x �� x �� D ^ w x \hat{r_v} = \frac{\sum_{x \in \hat{D}^v}w_x}{\sum_{x \in \hat{D}}w_x} rv?^?=��x��D^?wx?��x��D^v?wx??
(2)���Ż�������
������������,���Խ���Ϣ����ļ���ʽ�ƹ�Ϊ:
G
a
i
n
(
D
,
a
)
=
��
��
G
a
i
n
(
D
^
,
a
)
=
��
��
(
E
n
t
(
D
^
)
?
��
v
=
1
V
r
^
v
E
n
t
(
D
v
^
)
)
Gain(D,a) = \rho \times Gain(\hat{D},a) \\ =\rho \times (Ent(\hat{D})-\sum_{v=1}^V \hat{r}^vEnt(\hat{D^v}))
Gain(D,a)=����Gain(D^,a)=����(Ent(D^)?v=1��V?r^vEnt(Dv^))
E n t ( D ^ ) = ? �� k = 1 �O �� �O p k ^ log ? p k ^ Ent(\hat{D})=-\sum_{k=1}^{|\gamma|}\hat{p_k} \log \hat{p_k} Ent(D^)=?k=1���O���O?pk?^?logpk?^?
(3)��������
- ��������������a�ϵ�ȡֵ��֪,��x������ȡֵ��Ӧ���ӽڵ㡣
- ��ȡֵδ֪,��xͬʱ���������ӽڵ�,���Խڵ���������Ȩֵ����Ϊ r v ^ \hat{r^v} rv^