������ֱ�ӷ���һƪ���µ�,���Ȱ�ԭ�ĵ�ַ�������
ԭ������Ϊ:Survey of Model-Based Reinforcement Learning: Applications on Robotics
����һ��2017�������
1. Introduction
ǿ��ѧϰ(Regulation Learning,RL)���˹����������һ����Ҫ����,���Ŵӽ��ڵ������˵��ڶ�Ӧ��,������˴����ķ����������˼�������RL��˵��һ���dz�������ս�Ե�Ӧ��,��Ϊ���漰��еϵͳ���价��֮��Ľ�������������û�Ի�еϵͳ����������˺�,�������ڷ����ҵ��������,��Щ������Ԥ�ƻ��ڽӽ�����ĵط���������һ����,RL�����������ϵͳ����Ӧ��,���Ǵ������Ӷ�̬������һ����Ҫ��������Ȼ��,�ڹ�ȥ������,RL�ڻ����˿��������Ӧ��Խ��Խ�㷺[1,2]�����ǵ�δ����������˽���ñȽ����ܹ��ظ�һ����ȷ�ļ���������,��һ��ʵ�Ͳ���Ϊ���ˡ����������Ķ����ǻ���һ��۲�,���Ѿ������˴������ڻ�����RL�ĵ�������[1-3],�����Ƕ���Ҫ��������ģ�ͷ����ϡ�Ȼ��,������,����ģ�͵�RL�ڻ����˼����е�Ӧ��Խ��Խ�ܵ���ע[4-11]������������һ���ƶ������ǹ۲쵽�����˱������ڷ����仯;�ͳɱ���Э���������Ѿ���Ϊ�������г���һ����Ҫ��ɲ���,��������δ�������ø�����ռ������ֻ����˵ijɱ��ϵ�,���ɱ���ػ�Ӱ����ȷ�ԺͿ��ظ���,�Լ����ڲ������豸�����������,������Ҫ���¿���Ӧ�����������ͻ����˵�ѧϰ�������ص㡣
�������Ŀ��������:
- �ṩ������ѧRL�����¸���,�ص���ܻ���ģ�͵ķ���,��չʾ���������;
- ����RL������Ӧ�Եͳɱ���е����ս�����������,���ڵ�7�����ܽ��һ���Ƚ��ɿ��Ļ���ģ�͵�RL����,����ʹ�õͳɱ���е��ִ������
Ϊ��ʵ�ֵ�һ��Ŀ��,�����о��˻���ģ�͵�RL��ģ�����ʵ������ϵͳ�ϵ�Ӧ�����ס����ǽ����˼�ֵ�����Ͳ�����������,�Լ����÷��غ���(returns function)��ѧϰ����ģ��(transition model)�IJ���,��Щ�����ѳɹ�Ӧ���ڻ�����ϵͳ������ֻ���ڷ��������¼���֮��,����ϵ�һ��Ŀ������Ľ��,����ʵ�ֵڶ���Ŀ�ꡣ
����������֯���¡�����һ�������½�֮��,���ǽ��ڵ�2�ڽ������ڻ���ģ�͵�RL��ֵ������������3�������˷��غ���,��4�������˲�����������������,�ڵ�5����,���ǽ����˽�ģ���ɶ���ѧ�ķ�������6�ڻع��˻���ģ�͵�RL�����ڻ�����ƽ̨������ѧϰ��������İ��������,�����ڵ�7���ܽ����������Ľ��,�������˻���ģ�͵�RL���������Ѿ�������Ӧ��֮���Ӧ���е������ԡ�
1.1 ����ģ�͵�ǿ��ѧϰ����
RL���������͵Ļ���ѧϰ֮�����Ҫ��������,ѧϰ�����漰agent���价��֮��Ľ���,���agentͨ��ֱ�Ӵ��价�����ռ�������ѧϰ���������,������Ҫ�ⲿ��ʦ��Ȼ��,���������(agent�ͻ���)֮�����������ֱ�ӵ�,����ȡ����Ӧ�ó�������,��˫�㲽�к����˻����Ƶ�Ӧ����,���軷�����������˵ĵ����
�����˵�״̬��������������ɢ�ķ�ʽ��������ÿ��״̬��,�����˿���������Ӧ��һ������
a
a
a(���ָ��),�Ӷ��ı���״̬����Щ����Դ��һ�����Ժ���
��
(
?
)
��(��)
��(?),��ȷ���Ե������,�ú�����״̬ӳ��Ϊһ������
��
(
s
)
��
a
��(s)��a
��(s)��a������������,���Ժ���������һ�����������,ӳ�䱻д������
��
(
a
�O
s
,
��
)
��(a | s,��)
��(a�Os,��)�ϵĸ��ʷֲ���
ǿ��ѧϰ�㷨��Ŀ�����ҵ����Ԥ������IJ���,�ò����ɽ�������r���塣ָʾagent�ر�����Ҫ�������Ϳ������ۿۺ�����ƽ������,�����������ķ�Χ�ڼ��㡣��ѧϰ����������һ����֪�Ľ���״̬ʱ,ʹ�������ӽ�,������ʺ�ʹ����������
�������뻷��֮��Ľ�������ģΪ�����ɷ���߹���(MDP)��Ԫ��
[
S
,
a
,
��
,
P
(
s
��
�O
s
,
a
)
,
R
(
s
,
s
��
,
a
)
,
��
]
[S,a,��,P(s'|s,a),R(s,s',a),��]
[S,a,��,P(s���Os,a),R(s,s��,a),��]������,S�ǿ��ܵĻ�����״̬��,A�Ƕ�����,
P
(
s
��
�O
s
,
a
)
P(s' | s,a)
P(s���Os,a)�ǻ����˴���״̬S��Ӧ�ö���Aʱ��δ��״̬
s
��
s'
s����ת�Ƹ��ʡ�
R
(
s
,
s
��
,
a
)
R(s,s',a)
R(s,s��,a)�ǻ�������ת�Ƶ�״̬
s
��
s'
s��ʱԤ�ڵĽ���,ȡ����Ӧ�õĶ���
a
a
a,״̬
s
s
s,��ͨ�������������㡣���,
��
��
���ǽ����������ۿ����ӡ�
RL������Ϊ������,��ģ��(Ҳ��Ϊֱ��)�ͻ���ģ��(Ҳ��Ϊ���)�ķ���������ģ�ͺ���ģ�͵�RL֮�����Ҫ���������Ƿ�����˻������뻷��֮�佻����ģ��������ģ�ͷ�����,û��ģ��,��˽���������ж���ͨ������ϵͳ���Դ������ó��ġ��ڻ���ģ�͵ķ�����,����һ�����ɶ���ѧ(transition dynamics)ģ��,�����Ƶ�����������ж������,��ģ���жԲ��Խ����Ż�,��������ϵͳ��Ӧ�����Ų��ԡ�ͼ1չʾ��һ������ģ�͵�RL�ܵ���

��ģ�ͷ��������˸���Ŀ�ѧ��Ȥ,�������Ƶ����Ų��ԵIJ����켣��Ӧ����ʵ�ʻ�����ʱ������һ��ȱ�㡣��һ�ַ�����ʹ�û���ģ�͵ķ����������������,���Ų����ǻ���������˶���ѧ��ʾ���Ӧ��ѧϰ����ģ�͵��ڲ�ģ���Ƶ������ġ����������������˻��������价��֮�����������,�Ӷ����������˻�еĥ����һ����,������Ҫȱ���ǻ���ģ�͵�RL�㷨����������ģ��ȷ��ʾ���ɶ���ѧ(transition dynamics)����������1�ܽ�������RL�㷨����ȱ�㡣

RL����Ľ���Դ�������ѡ�������е�������㷺ʹ�õķ����Ǽ�ֵ��������,�����ƴ��ڸ���״̬�����ݲ���ִ�в�����agent��δ��Ԥ�ڻر�����״ֵ̬����
V
��
(
s
)
=
E
��
R
t
�O
s
t
=
s
V^{��}(s)=E_{��}{R_{t} | s_{t}=s}
V��(s)=E��?Rt?�Ost?=s��������ֵ����,��������ѭ���Ԧе�״̬�µ�Ԥ������,�Լ�����ֵ����
Q
��
(
s
,
a
)
=
E
��
R
t
�O
s
t
=
s
,
a
t
=
a
Q^{��}(s,a)=E_{��}{Rt | s_{t}=s,a_{t}=a}
Q��(s,a)=E��?Rt�Ost?=s,at?=a,���൱����״̬s��Ӧ�ö���a������ʱ����ѭ���Ԧе�δ��Ԥ�����档������ѧϰ��ΧH�������,���غ����ǽ���
R
t
=
��
t
=
0
T
r
(
s
t
,
a
t
)
R_{t} = {\textstyle \sum_{t=0}^{T}} r(s_{t},a_{t})
Rt?=��t=0T?r(st?,at?)���ܺ͡��������ڵ������,���溯���������ۿ���ʽ(12)��ƽ����ʽ(13)��
Value function��ֵ������������һ�����ż�ֵ��������״ֵ̬����ֵ,�Եó�ÿ��״̬�µ������ж������,ʹ���ڻر���IJ����Ǵ�ÿ��״̬����Ѷ��������������ġ���ֵ����������Ϊ����:i)��Ҫtransition dynamicsѧģ�͵Ķ�̬�滮(DP)����,ii)���ڳ��������ؿ���(MC)����,iii)��������״̬transitions֮���ֵ���������ʱ����ѧϰ(TDL)����,�Լ�iv)��ֶ�̬�滮����(DDP)��
ֵ������������������Dz��������������ڲ�������������,���Ǵ�����ֵ�����ع�����,����ֱ��ѧϰ���Ų��ԡ����ֵ�����������,��һ��ʵʹ�����Ƚ��IJ������������ڸ����ɶȻ�����ϵͳ��������ܹ����������[2,��2.3��]�������ɶ��ַ�����ʾ,�Ӽ����Ժ��������ӵĶ�̬�˶���Ԫ[1]�����ǵĹ�ͬ�ص���,���Ƕ���һ��������в�����,�������Щ���������Ż�,��ʹ�ۻ��������
���������漰�ķ�������:i)�����ݶȵķ���,�ڽ����������ݶ���ʹ����ɽ�������²�������,ii)�������(EM)����,ͨ��������Ķ�����Ȼ�����ƶϲ���,iii)�����صȸ����Ƶ��Ż����Ե���Ϣ�۷���,iv)��Ҷ˹�Ż�����,v)�������㡣
ͼ2�ܽ��˽��RL�������Ҫ���������ε����ʣ�ಿ�ֽ���ѭ���ַ��෨,��̽������������¼�����

2. ֵ��������
RL�����״ֵ̬���������õݹ���ʽд��,���ʽ(1)��ʾ,���,״̬��ֵ����ȡ���ڿ��ܵ�δ��״̬�ļ�ʱ�ر�������ת�Ƹ��ʼ�Ȩ���ۿ�ֵ������
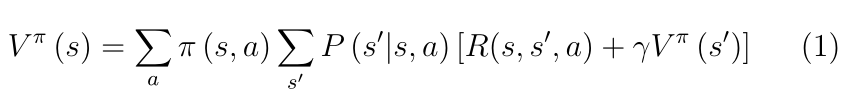
��Ч��,����ֵ���������Եݹ���ʽ��д,������ʾ:
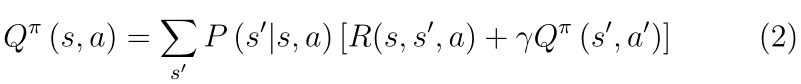
����(1)��(2)�ֱ���״ֵ̬�Ͷ���ֵ�ı���������(
B
e
l
l
m
a
n
?
e
q
u
a
t
i
o
n
s
Bellman -equations
Bellman?equations )����ֵ����������Ŀ���Ǽ����ֵ����,��ͨ�����ÿ��״̬�µļ�ֵ�������ó���Ѳ��ԡ�����֤������һ�����Ų���
��
?
��^{*}
��?,��ֵ����Ϊ���ֵ,����״ֵ̬����
V
?
V^{*}
V?д����ʽ:
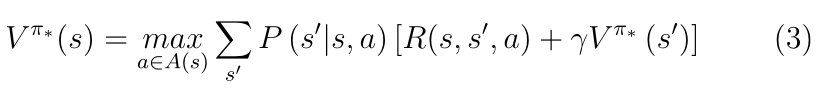
���Ӧ��״ֵ̬�����ı����������Է��̡����Ƶ�,���Ŷ�����ֵ������һ�����������ŷ���,дΪ:
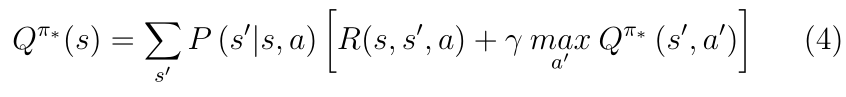
��ֵ���������ṩ���Ƶ����ż�ֵ�����ķ���,�����ع����Ų��ԡ�������ڻ���ģ�͵�RL[9,10,12-26],[27-30]�зdz�����,��������Ҫ��֪transition����ѧģ�͵Ķ�̬�滮��������������,�����ؿ�����ʱ���ַ�,��Ҫ������ģ��RL,��Ϊ���Dz���Ҫ��֪��ģ�͡�ͼ3�ܽᲢ��������������еĹ���,���м�ֵ����������Ӧ���ڻ���ģ�͵�RL������ϵͳ��

��̬�滮(DP)�����ǵ����㷨,���Է�Ϊ���Ե���[34]��ֵ����[35]��
���Ե���������������;��һ���Dz�������,Ϊ�������Լ���״̬
s
s
s����
a
a
aֵ���������Ǵ�һ�����������еó���,�ù��̼���ÿ��״̬��ֵ����,ֱ����������������������֮���Dz��ԸĽ�����,�ڸò�����,������ÿ��״̬����Ѳ�����
2.1 ���Ե�����
��[11,12]��,���߲�����һ�ֲ��Ե�������,ʹ����Ȼ������-�������㷨(Natural Actor-Critic algorithm)[36]����Critic ����,������������ʱ���ַ�,��LSTD-Q(��)[37],��Actor���ֲ�����Ȼ�ݶȷ����в��ԸĽ�[38]��[6]�л�ʹ����һ�ֲ�����-�������㷨(actor-critic),�������㷨��critic����ʹ��ֵ�������ݶ����Ľ������Ƶ�����[13]��,��LeastSquare���Ե����㷨[39,40]��������ִ�������Ľ����衣������������,ʹ�ö���ֵ�����IJ�������,�Լ���״̬�ռ䡣ͨ��������Է��������Ƶ�������������ֵ�����IJ���,�Ľ��˸ò��ԡ�ͨ������[41]�н��ܵ�����ɨ��(PS)����,���㷨��Ԥ���ʱ��Ч�ʵõ������,�ü�����״ֵ̬�ĸ��¼����ڡ�����Ȥ����״̬�ϡ���[9]��,����ʹ�ø�˹����[42]ģ�������ƶ���ֵ������
������������transitionģ�����ɵ�����,���ڽ��ƶ���ֵ�����ԵĸĽ�����ͨ��̰��������ִ��,�÷���ʹ��ÿ��״̬����Ѷ���ֵ,���߿���ÿ��״̬���������ܶ�����������
2.2 ��ֵ������
�ڲ��Ե���������,ֻ������������������Ÿ��²���,�������һ��ķ�ʱ�����Դ���������֮��,ֵ������������ȵ���������������Ÿ��²��ԡ���[20]��,ֵ��������PS���ʹ�á������䲢��ִ��,���㷨�������ѧϰ�������Ż���[21]������ʹ����[43]�н��ܵ�R-Max�㷨����ʹ�ü�ֵ�������滮�����¶�λ���ж�ģ��,����һ���ֽ��MDP[44]��RMAX��һ�ּ�����ǿ��Ļ���ģ�͵�RL�㷨,��Ϊ�������ڶ���ʽ���㸴�Ӷ���ʵ�ֽӽ����ŵ�����[43]�����㷨���á���ȷ�����µ��ֹ����塱����,��������δ֪״̬���������ܵĻر�,δ֪ת��������һ���鹹����״̬�����㷨�������ظ��IJ������:����Ͷ���(act)�Լ��۲���¡��ڵ�һ����,agent������֪ʶ���㲢Ӧ�����Ų���,�ò��Խ�һֱִ�е��¼�������ﵽ��״̬����һ��֮���ǹ۲���²���,�ڸò�����,����Ϊÿ����ȡ���ж�����ģ�͵Ľ�����ת�Ƹ���,�����¼������Ų��ԡ����,R-MAX��ʹ������̽��������,�Ӷ���þ�ȷ��ģ�ͺͽӽ����ŵIJ��ԡ�[45]�н�����R-MAX�㷨��һ����չ,����ϵ��Դ������(REX),�����Դ�����ϵ״̬�ռ�[46],������[46]�ж�REX��������չ,�Ա���Ҳ���Դ���ר�ҵ���ʾ,����Σ�յIJ���ִ��,����������ȫ��ģ��[47]��
��[22]��,���������һ�ּ�ֵ�����㷨RLDT,��ͨ��ִ��������Ե�̽���������뻷���Ľ��������,��[23]��,���������˼�ֵ���������Ƶ����Ų��ԡ�
2.3 ��ֶ�̬�滮��
��ֶ�̬�滮(DDP)�ǻ���ģ�͵�RL�й㷺ʹ�õ�һ���Ƶ����Ų��Եķ�����DDP�㷨��Դ�����ſ�����������ִ�оֲ��켣�Ż�,�����Ҫ��ʼ�켣,�Ա���������Ż�����ͨ��ָ��ֵ�����ľֲ�����ģ�ͺ����ʼ�켣���Ӧ�IJ��Ժ���������ģ������ʼ��DDP�㷨�����Ż����̵ĵ�һ��,����ǰ����Ӧ���ڶ���ѧģ��,����ģ��켣���ڵڶ�����,���ɵĹ켣���ڼ��㽨ģֵ������ÿ����ķ���;Ȼ����Ӧ�ظ��²��Ժ����IJ�����
[32]�в�����DDP,����״ֵ̬�����ľֲ�����ģ����ֵ������һ�Ͷ�����������,�ֲ����Ե�ģ��ȡ���ڲ��Ե��ݶȡ���[17]��,���߽�����Minimax DDP,����ʹ���˶���ֵ�����ľֲ�ģ�͡����˴�ͳ��DDP,��Minimax DDP��,�Ŷ��Ĵ�����״ֵ̬�ľֲ�ģ���е��Ŷ����ʾ���봫ͳ��DDP���,���ַ���ʹ�ø��㷨�ܹ���������ȷ�Ķ���ѧģ�͡�[33]�и�����DDP�������չ,����״̬�ɸ��ʷֲ��������봫ͳ��DDP�������,���Ľ�������,�Ż�����Դ��һ���ݶ��½��㷨,���������ٶȸ���[48]����[49]��,����ͨ��ʹ�����ж��ι滮�Ż�Լ��Ч�ú���,ʵʱִ�й켣�Ż������ǵķ�������ʵʱ�滮�켣,����Ҫ�����洢���ԡ�
���Զ��ε�����(LQR)��DDP��һ������,����transition dynamics�����Խ��ƽ�ģ,�緽��(5)��ʾ,��A��B������������A��m��m����,B��m��k����,m,k�ֱ���״̬
s
s
s�Ϳ���
a
a
a������ά������LQR��,���Ų�����״̬����(11)�����ľ���
P
i
P_{i}
Pi?(6)��������ϡ���LQR�������,����������ʾ����״̬
s
s
s����ʱ�䲽tӦ�ö���
a
a
a�ijɱ�,���Զ�����ʽ��ʾ,��(6)��ʾ,����Q��W�ֱ���ά��Ϊm��m��k��k�����Գƾ���
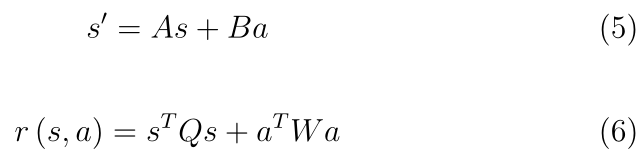
ͨ��Ӧ�õ�ʽ(5)��(6),�����Ż���ֵ��������д��:
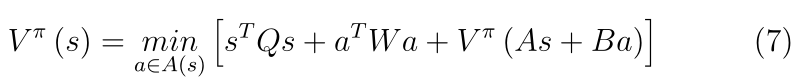
����ͨ������ֵ�������̽����Ż�����Ͳ�����ÿ��i�������Ų���(��ʽ(8))������״ֵ̬����(��ʽ(9))��

����,����K��P(10)��(11)ʹ��DDP�Ƶ�����:
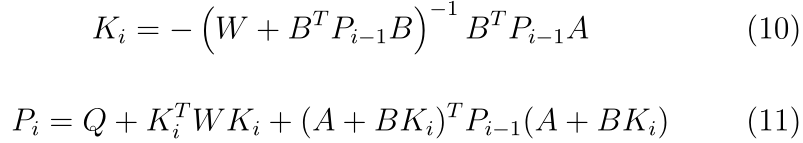
����DDP��LQR�ĸ���ϸ����,��μ�[50,51]��[52,��5��]��
��[28]��,����ʹ��LQR������,����������ѧϰ����Ĺ켣������,�������ѧϰ���Ʒ������ʹ��ʱ,LQR�������Լӿ�켣ִ��[10,24]��[27]������ʹ��ר����ʾ�Ĺ켣,�Խ�һ���Ľ���ѧ�����Ų��ԡ�[4]�е����߲�����LQR��һ�ֱ��塪������LQR,��Ŀ������С�����Ź켣�͵�ǰ���Բ����Ĺ켣֮���KL���졣��С���ܵ�Լ��,ȷ���㷨������ƥ����Ż��켣�Ͳ��ԡ�LQR��һ��ȱ���Ǽ�������ȷ����״̬ת��;�����ͨ����չ���˷�,�����˹-ţ��LQR,��Щ��չ�ѱ����ڴ����������[25]��
���������� DP���������������ʱ����(TD)�����ؿ���(MC)�㷨���������DZ���Ϊ����ģ�ͷ���,��Ϊ���Dz���Ҫtransition dynamics��ģ��,����transition dynamicsδ֪�������,���DZ����ڻ���ģ�͵�RL,����������ѧϰ��MC�㷨�ǻ���������,��ʹ�����ɵ���������Ԥ�ڻر���TDѧϰ�㷨��������������������ʽ(�Ծ�)����ֵ����,������Dz���Ҫ���RL����
��[30]��,����ʹ�����ؿ����������㷨�����ƶ��߳���ϵ�ṹ�еĶ���ֵ����,��ʵ��ʵʱѧϰ��[53]�н��ܵ�SARSA��TDѧϰ�㷨��[29]��ʹ�á�������,��״̬ת��������ѧϰģ��,Ȼ�����ڹ��ƶ���ֵ��������[14]��,����ʹ����Dyna-Q�㷨,���㷨��Qlearning[54]��Dyna���[55]����,��������ģ��ѧϰ����ֵ���ƺʹ����ķ�Ӧ��[18,19]�л�ʹ����Dyna-Q��������ģ����,��ʵ�ֶ����������ʱ���Чѧϰ��
3. Return functions
ѡ����ʵĻر�������Ի���ģ�͵�RL�㷨�����ܲ����ش�Ӱ�졣���غ���Ӱ��ѧϰ����������ԺͿ�����,��Ϊ���Ų��Ե��Ƶ�����������RL�㷨��Ŀ������ÿ��ʱ�䲽�ҵ�һ�����,�ӳ�Զ�����Ż����غ��������غ������������¼��еĽ�����ͷ�,���ӳ�ʼ״̬s0�����������
���غ�����������ij��Ƚ��з���,�������ۻ�Ϊ��������ˮƽ��������һ�ַ�����������Ŀ��״̬��֪��Ŀ�굼������;���,����ͨ�����ڻ�����Ӧ�á��ر�����R֮�����һ��������,ÿһ���Ľ���R�Ƿ�����ۻ����ۿۻر�����,���ʽ(12)��ʾ
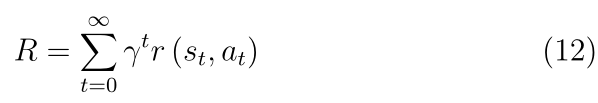
�����ڽ���ʩ�ӽϴ�Ӱ��,��Ӱ�������ʱ������Ƴ�ָ���ݼ�����һ����,��ƽ���ر�������,���ʽ(13)��ʾ
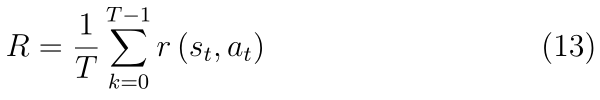
ѧϰ�����л�õ����н������ǵȼ��ۻ��ġ�ͼ4�����������֯�˹��ڷ��غ�����������ס�
�ۿ�ϵ����ʾͨ����ѭ���Ի�õ�δ������IJ�ȷ����,���ڲ�ȷ������ʱ������,δ�������Ӱ���С���ۿ�ϵ��
��
��
���������ѧϰ����ѡ��,����������ʱ���ѧϰ��������֮������ԡ����,��С���ۿ����ӻᵼ��RL�㷨�Ŀ���������Ȼ��,������������ʱ��õĽ����Իر�������Ӱ��dz�С,���ѧϰ���Ľ���������������ܲ��������⡣

�ۿۻر������ǻ���ģ�͵�RL�����˼���Ӧ���������еġ�����������ѡ���ںܴ�̶���ȡ����ѧϰ�����Ŀ�ꡢ�����˵�Լ���Լ������Ż����̵�ѡ������������ķ���[5,7,10�C12,20,58,59,67]��,������Ŀ��͵�ǰ״̬֮��ľ��������������һЩ�����,����һ���ɱ�����,���ڳͷ�ƫ����֤���켣�����[6,16,24,25,27,56]������,��Ӧ���ֶ�̬�滮���Ƶ����Ų���ʱ,reward�������Ϊ������[16,24]����״̬�ռ���ɢ����Ӧ����,��������ʽΪ��Ծ����[13,20,22]���������ڽ�����������������˺ͻ�����Լ��;������Ϊ�ͷ���ͻ��ӽ���ͻ״̬�ijɱ���ɲ���[62]�����,����һЩ����,���ԶԻ����˲�ȡ�����в���������Ŀ��״̬�Ķ�������һ��ͷ�[18,23]����ǡ��ʵ����ѧϰ�㷨�ĸ���������
4. ������������
�������������ǵ������Ų��Ե���һ�ַ�������ֵ��������ͨ��Ѱ����ÿ��״̬��ʹ��ֵ������Ķ���(actions)��ӹ������,��������������ͨ���������ֱ�Ӽ������Ų��ԡ��Ƶ����Ų������㷨�ɷ�Ϊ������ͼ�����̫���е��ࡣ�����ݶȵķ�����ͼͨ�������ݶ������������Ż����������Ժ��������ǵ���Ҫȱ������Ҫ�����ݶȲ�������,���Ӱ���㷨�������ԡ���һ����,sampling-based�ķ������ܴ������Ӱ�졣������ʹ�õ����㷨�ƶϵ�DZ�ڱ�����������Ȼ��,���ǵ�ȱ���Dz��ܱ�֤���������Ź켣,�������ǿ��Դ���Զ�����ù���ģ�͵�ѵ�����ݵĹ켣����һ����,��Ϣ�۷���ͨ�����ƹ켣̽���������Щ���⡣���,�������˻��ڱ�Ҷ˹�Ż��ͽ�������ķ������������������ķ�����ͼ5��ʾ��

4.1 Gradient-based��
��[57]��,ֱ���ݶ��㷨[74]���ڲ����Ż����ò��Ա�������Ϊһ���˹�������,��Ȩ���ڲ������������б��ġ�����ͨ��ѵ��һ��ģ�����Ų��Բ�����ת�Ƶ�ʵ��ϵͳ���н�һ����,�ӿ���ѧϰʱ�䡣��[59]��,����ʹ���ݶ���������ʵ��Ԥ�ڻر������[67]�н��ܲ���[5,62,63,68]��Ӧ�õ�ѧϰ���Ƹ�������(PILCO)����ǽ��RL��������Ƚ�����,��Ϊ����Ҫ����������ѧϰ����,���Ҿ���ʱ��Ч�ʡ����㷨�Ĺؼ�������transition dynamicsѧģ�ʹ��������벻ȷ���Ե�����[75]����һ����ʹ�öԳ��켣�ӽ��Ԥ�����ȷ,��˼����˽�ģ����Ӱ�졣
PILCO�����ݶȷ����в��ԸĽ������������Ż����dz���Ԥ���������С��,���Ӱ�쵽��Ŀ��ľ��롣�����ݶȵ��Ƶ�,��������ƫ����������
����ϸ��˵,PILCO ʹ�ø�˹������Ϊѧϰtransition dynamicsѧ�ķ���(��һ���μ��� 5 ��),��Ϊ�������ڵ�ƽ��(horizon)��ÿ��ʱ�䲽����״̬����һ��Ԥ��ֲ��� ���,���ڻ�����״̬��Ԥ���������,������̬�ֲ�
(
p
(
s
1
)
,
p
(
s
2
)
,
.
.
.
,
p
(
s
k
)
��
N
(
s
k
�O
u
k
,
��
k
)
(p(s_{1}),p(s_{2}),...,p(s_{k})\sim N(s_{k}|u_{k}, {\textstyle \sum_{k}^{}} )
(p(s1?),p(s2?),...,p(sk?)��N(sk?�Ouk?,��k?)��������һ���Ǽ���ÿ���ε�Ԥ�ڻر�,���ʽ(14)��ʾ�� ���,�켣��Ԥ�ڻر�Դ�Թ켣��ÿ��״̬
s
k
s_{k}
sk? �Ļر����� r (��)�� �����ɴ��ڸ�״̬
N
(
s
k
�O
u
k
,
��
k
)
N(s_{k}|u_{k}, {\textstyle \sum_{k}^{}})
N(sk?�Ouk?,��k?)�ĸ��ʼ�Ȩ,��Ϊ��Դ���㷨��ת��ģ�͡�
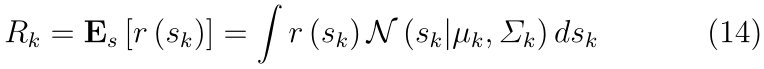
�����������,������������Ӧ�ò��Ե�һ���ɱ�,����ѡ����������ʹ��ʽ (14) �еĻ����ڷ��������ڴ�����
����ò�����һ������ӳ��,����һ�����
��
=
[
A
,
b
]
,
��
(
s
k
,
��
)
\theta =[A,b],\pi (s_{k},\theta )
��=[A,b],��(sk?,��)������,���ʽ(15)��ʾ,Ŀ���Dz����ݶ��½����Ƶ�������,ʹԤ�ڻر�Rk��С����

���,ͨ��Ӧ����ʽ����,����ʽ(16)�еĵ������д�����
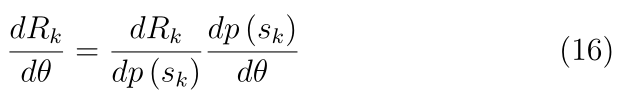
����
p
(
s
k
)
p(s_{k})
p(sk?)����̬�ֲ�,��ȡ������������,����̬�ֲ���ƽ��ֵ
��
?
k
��-k
��?k���������
��
k
��_k
��k?��
���,��ʽ(16)����д��:
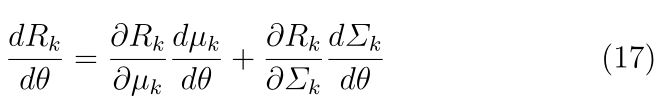
����(17)�еĵ�������ͨ������Ӧ����ʽ������н�������,��ʹ�û����ݶȵķ���������Ч���á��й����Ƶ��ĸ�����ϸ��Ϣ,��μ�[76]��
�� [63] ��,PILCO ���ɹ�Ӧ���ڽ�Ͻ�άѧϰ��άϵͳ�IJ��ԡ� [68] �е�����ʹ�� PILCO ���Ƶ�ģ��ѧϰ�����еIJ��ԡ� �����������,Ŀ�꺯������ Kullback-Leibler (KL) ɢ��,���Ƕ�ר����ʾ�Ĺ켣������������Ĺ켣֮�������ԵĶ����� PILCO �� [5] ��Ҳ������ѧϰ�ܹ�������δ֪����IJ��ԡ�����,[69] �е����߲�������������Ʋ���,���������Ȩ�ض�Ӧ��ѧϰ�IJ��Բ����� ��������Ż���Ŀ�����Ƶ���������Ź켣�IJ����� ��ѹ켣��ʹ��ţ�ٷ���С������ijɱ������Ĺ켣��
[70] ���������һ�ֻ����ݶȵIJ����Ż�����,���߽����ڲ�����̽�� (PGPE) ��������ģ�Ͳ����ݶ���չ������ģ�͵ij��� (M-PGPE)�� �����������,������ȷ���Ե�,����ʾΪ���Ժ��������,Ϊ�˴���agent��̽��,���ԵIJ����Ǵ�������һ�鳬�����ĸ��ʷֲ��в����ġ� ���㷨��Ŀ����ͨ�������ݶ��������������Ԥ������ij�������
4.2 Sampling-based
��Ӧ���ڻ���ģ�͵� RL �ϵIJ��������Ļ��ڲ����ķ������� [77] �н��ܵ� PEGASUS(ʹ�ó����IJ�������������)�㷨�� PEGASUS ͨ������� MDP �� POMDP ת��Ϊ����ȷ���������������������⡣ �����ģ������ת����̬ʱ,ģ�͵�Ԥ������һ��״̬
p
(
s
t
+
1
)
p(s_{t+1})
p(st+1?) �ĸ��ʷֲ������,��ʹ�����ģ�������̶�����ʱ,��һ��״̬��Ԥ���������ͬ,��Ϊ�����ǴӸ��ʷֲ��еó��ġ� ���,Ԥ�������ܵ�Ӱ���� ���ȱ���� PEGASUS ��ͨ��ʹ��һ��̶���Ԥ���������(�ȶ�����)����(PO)MDP �����,��Щ����������ת��Ϊȷ����ת��ģ�͡����㷨ͨ������ȷ����ת��ģ�͡������������������������ʼ״̬������ķֲ��Ͳ��Բ������е����ͳ�ʼ���� Ŀ����ȷ������������IJ��Բ�����
PEGASUS ���� [60] ������ѧϰ���ĸ��ɵ�������ɵ��������������������IJ��Բ���������ɽ�㷨,���㷨�������ݶ�������������ߡ��������ר�ҵ���ʾ�еó��IJ������,ʹ�����ַ�����ѧϰ���Ե����ܱ����ָ��á�����,[71] �л������һ�������������������Ȩ���Ǹ��� PEGASUS �㷨�����IJ��Բ������� [72] ��,����Ӧ�� PEGASUS ��ѧϰ�����Ӿ�ϵͳ��������������Ŀ�����,���Ӿ�ϵͳ�ܹ�ʶ�����Ե�Ŀ�������ײΣ�ա��� [56] ��,PEGASUS Ҳ����ѧϰ���� 10 �����ɲ����IJ���,��������ڸ��²����� Nelder-Mead ������
4.3 Information Theory
��Ϣ�۷��������صĸ�����Ϊ�Ż����Բ����Ļ���������Ϣ������,���Ƕ����¼���صIJ�ȷ���ԵĶ������ڻ���ģ�͵� RL ����������,�����������Ӳ������ɵĹ켣��ο��켣��ȡ���ͨ�����ⲿ��ʾ��á�[66] �е����߽����˱���������������㷨,����Ϊ��ά���������Ƶ����ʵIJ��ԡ����㷨������������,����̽���Ͳ����Ż����衣��һ��,��ֶ�̬�滮���ڹ켣̽��,�ͷ��뵱ǰ���ԵĴ�ƫ�����һ����,���ԵIJ������ڴ�̽������ó��Ĺ켣�����Ż����Ż����� KL ɢ�ȵ���С��,����һ���ض���,ʹ������ݶ��½�ִ�С��� [65] �� [8] ��,[78] �н��ܵ���ģ������ز�������(REPS)�㷨����չ������ģ�͵�ǿ��ѧϰ,����ѧϰ������ѧϰ����Ĺ����ϲ���� ���ǵ����������в�ͬ���ϲ���Ժ͵Ͳ����һ������ѧϰ����ķ��������,�ͼ����Ը����ض���������,������ָ��λ�õ��˶�,���ϼ����Ը����˵ͼ����Ե�����ض������ġ���˹����ת��ģ�͵�ʹ��ͨ���������ڸ��²��Ե��˹�����������ѵ������������������õ���,���������˻������뻷��֮�������á�REPS �㷨��Ŀ�����ڲ�����ƫ��۲����ݵ�������Ż�������ԡ�
����,[61] �������������������Ż� (TRPO) �㷨,����Ŀ�꺯������ KL ɢ��Լ�������Ż���Ŀ�꺯����ʾ������Ե�Ԥ�ڻر�,�� KL ɢ�ȶԲ��Բ���ʩ������Լ���� Ŀ�꺯����ɢ��Լ����ͨ�����ؿ���ģ��ƽ�,�Ż�����ͨ�������ݶȷ���⡣
[79] ��������ʹ��·������ (PI2) �㷨�IJ��ԸĽ��㷨,���㷨Դ��������ſ��ƿ��,������������ѧ��·�����ָ�����ִ�в��ԸĽ��� PI2 �㷨ֻ��һ���ɵ�����,��̽������,���ҿ��Ժܺõ���չ��ά������ѧϰ����,�������λ����˵�ѧϰ������Ϣ�۷����ıȽϱ���,���߿�����Ϊ������ſ��ƵĽ��Ʒ���������,PI2�����ڻ���ģ�͵�[80,81]����ģ�͵�RL����[82],�����˶�ԭ��ĸ���[83]�������߲���������Deisenroth����[1]�ĵ�����,�����ҵ�PI2�㷨����չ���ܡ�
[73]���������һ�ֻ���·�����ֵķ���,������ʵ�ֹ켣����Ż���ģ��Ԥ��·�����ֿ���(MPPI)�������·�����ַ����෴,MPPI������ֻ�л�����ͨ���䶯�����Ƶ�״̬��������,�������������ļ�ӿ���״̬������,���㷨Ϊ����ѧϰ��Χ�ڵ����ſ����ṩ��һ�������ı���ʽ����Щ������ͨ����������ص���Ϣ�۸���ʵ�ֵġ����,MPPI����Radon-Nikodym������Girsanov�����ĸ���,ʹ�����˵����Ź켣����켣֮�������С����
4.4 Other approaches
����������������������Ҷ˹�Ż�[7]�ͽ�������[64]����[7]��,��Ҷ˹�Ż����ڼ��ٶ�Ŀ�꺯�����������Ĵ���,�Ի����Ѳ����������ͨ��ʹ�ø�˹����ģ�Ͷ�Ŀ�꺯����ģ,��ʹ�ø�ģ������Ŀ�꺯����ʵ�֡���һ����,[64]�е����߲��ý������㷽��,ͨ���Ż��˹��������Ȩ�����Ƶ��Ż����ԡ�
5. Transition Models
Transition Model T ( S , a , S �� ) ? ? P r ( s �� �O s , a ) T(S,a,S')--P_{r}(s'|s,a) T(S,a,S��)??Pr?(s���Os,a): Transition Model, ���ݵ�ǰ״̬ s s s �Ͷ��� a a a Ԥ����һ��״̬ s �� s�� s��,����� P r P_{r} Pr? ��ʾ�� s s s ��ȡ�ж� a a a ת�Ƶ� s �� s�� s�� �ĸ���
Transition model�Ǵӻ�������horizon����ʱ�䲽��״̬
s
s
s��ӳ��
f
(
s
,
a
)
��
s
��
f(s,a)��s'
f(s,a)��s��,�Լ�����һ��ʱ�䲽Ӧ�õ�����
a
a
a ��״̬
s
��
s'
s���� ���ڲ���ѧϰ������������Ԥ���ȷ��,���Transition model�Ի���ģ�͵� RL �㷨�������кܴ�Ӱ�졣���ǽ����ڻ���ģ�͵�ǿ��ѧϰ��Transition model��Ϊ�����ࡪ��ȷ����ģ�ͺ����ģ����ȷ����ģ��(Deterministic models)�����������������Ԥ����һ��״̬,���ģ�͵�Ԥ����ڸ�����״̬�Ͷ�����ʼ����ͬ����һ����,���ģ�ͻ������δ��״̬�ĸ��ʷֲ������Ԥ�⡣ ͼ 6 ˵�������������������ڻ���ģ�͵� RL ��ģ�͡�

5.1 Deterministic Modelsȷ����ģ��
����transition dynamics�Ļ���������ģ�ͱ��㷺����ȷ����ģ�� [4, 12, 16, 26, 57, 81]������ģ�͵���Ҫȱ�������ǰ����������Է������������,���絯�Խ�ͷ��Ħ�����Ͷ���ѧ����һ��ȱ������Щģ��û�п��ǻ����˻�����DZ�ڱ仯��Ϊ�˽����Щ����,[15, 64] �е�����ʹ�����Իع���ǿ�˹��ɵ�����ģ��,���ƶ����Լ����ģ�Ͳ�����[17] �л������˻���������ѧϰģ�͵����,����ʹ�ø���Ұ��Ȩ�ع� (RFWR) ������ģ�ͺ���ʵ������֮��������н�ģ�� RFWR������ [85] �н��ܡ�����һ���ֲ��Dz���ģ��,�����������µġ�����Ԥ����ڴ������������ѧϰ����֮�������Եĸ���Ұ��
��һ�ַ���,�ֲ���Ȩ���Իع� (LWLR),�ѱ�Ӧ����ֱ�ӴӸй�������ѧϰtransition model,�������˽�����˵�ģ�� [6,32,60]��LWLR ���� [86] �������,��һ�ַDz���ģ��,������ѵ�������ϱ���������Իع�ģ�͡�ģ�ͻع�ϵ����Ԥ����ʹ����ͨ��С���˹��������е�,��һ���ں˼�Ȩ,���ں��ṩ�������ѧϰ����֮�������ԵĶ��������,���ӽ���������ݵ��Ԥ���Ӱ����� ��[69]�л�����˾ֲ����Իع�ģ�͵����߸���,����ѧϰ˫������˵�contact dynamics��
������Ҳ��ʹ��,��Ϊ�����ܹ��ܺõظ���ѧϰģ�� [22, 30]�����ǹ�����һ�ֶַ���֮�ķ���,��Ϊ���ǻ�����ѧϰ�����ݿռ��Ա���������Ԥ�⡣�����Ǹ��� C4.5 �㷨 [87] ���е�,���㷨ʹ����Ϣ����ĸ���(��Ϣ�۸���)����ѵ������,�����ݲ�ֵ���ͬ�Ľڵ�,ֱ��ÿ���ڵ㾡���ܡ�������
5.2 Stochastic Models(���ģ��)
ѧϰtransition models(���������ģ��)�����Ƚ������Ǹ�˹���� (GP),Ӧ���� [5, 8-10, 49, 59, 63, 65, 68, 71] . ͨ��,����ģ������������Ϲ����ֲ�,�� GP �ں����Ϲ����ֲ������,û�й��ڽ���ǰ״̬�Ͷ���ӳ�䵽δ��״̬�ĺ��� f ���κμ��衣��һ��ʵʹ GP ��Ϊһ��ǿ���ѧϰ������GP �����ֵ���ں�(Э�����)���塣�ڴ���������,���� GP ��ƽ��ֵΪ��,�����ں˵�һ���dz�������ѡ������Щ����ָ������ںˡ����ڶ��������ں˲���(������)�ķ���,�����Գ������ռ��̰�������ͻ��ڱ�Ե��Ȼ�ķ���,��Щ����ʹ�ø��㷺��
����ϸ��˵,��transition models����������,GP ��Ŀ�����ƶ����������۲�ֵ s�� �ĺ��� f�� �����˹����:
s
��
=
f
(
s
,
a
)
+
N
(
0
,
��
0
2
I
)
s'=f(s,a)+N(0,\delta_{0}^{2}I)
s��=f(s,a)+N(0,��02?I) ����Ϊ��ʾ x
=
(
s
,
a
= (s, a
=(s,a)������Rasmussen��[88]�еĻ�,��˹���̿��Զ���Ϊ����������ļ���,�������������������(һ�µ�)���ϸ�˹�ֲ�����������D������������N��ѵ��������һ��
N
?
N^{*}
N?����������ɵ����ݼ�,GP f��ƽ��ֵ
��
(
x
)
��(x)
��(x)������
��
(
x
,
x
?
)
��(x,x^{*})
��(x,x?)�ֱ��ڷ���(18)��(19)�и�����
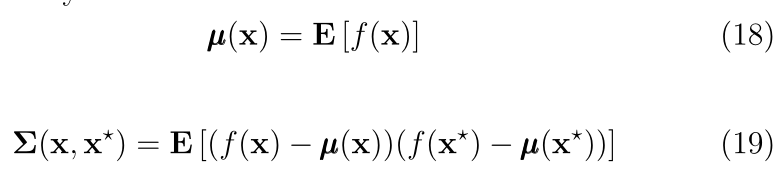
�ڴ����Ӧ����,GP��ƽ������Ϊ��,�ص���ѡ���ʵ���Э�����(Ҳ��Ϊ�˺���)����������˺���������Ҫ����,��ΪGP������ǿ�����������ǡ���������������ռ��ж�translations�IJ�����,���DZ�����Ϊstationery or not stationery����õĺ���ƽ��ָ��,���ʽ(20)��ʾ,��ȡ������������;����
��
2
��^2
��2�ͳ��ȱ��
��
��
�������߿����㷨��ѵ�������ƶϳ��ľ��롣
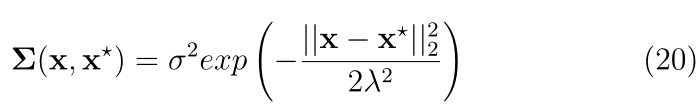
�˲�����ѡ��ͨ����ͨ���Ż�����ѵ�����ݵ�GP�Ķ�����Ȼ��ִ�е�,�緽��(21)�еij���
��
=
?
1
2
l
o
g
2
��
\beta =-\frac{1}{2} log2\pi
��=?21?log2�� ��������̶�Ӧ�ڸ�������Ȼ�Ĺ���Э�������
��
��
����ƫ��������С�������,��ʽ(22)����С��,����
a
=
(
��
(
x
,
x
)
+
��
n
2
)
s
��
a=(\sum (x,x)+\sigma _{n}^{2})s'
a=(��(x,x)+��n2?)s�������˵���Ѳ���,���ҿ���ͨ�����ֺ����Ż�����ʵ�֡�
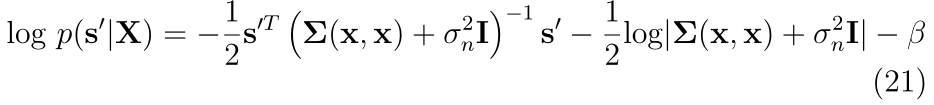
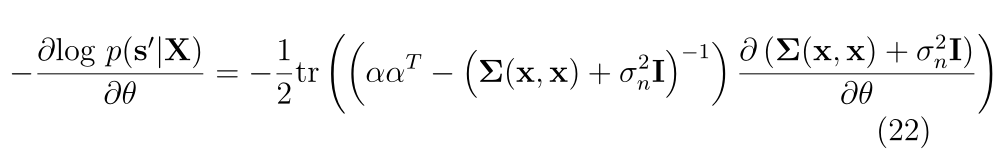
����һ���µIJ�������
x
?
x^*
x?��Ԥ��Ŀ��ֵ
s
?
��
s_{*}^{'}
s?��?��Ӧ�ڵ�ʽ(23)�и����ĺ���Ԥ��ֲ���ƽ��ֵ����һ����,��ʽ(24)�и�����Э�����ʾ��Ԥ��IJ�ȷ���ԡ�
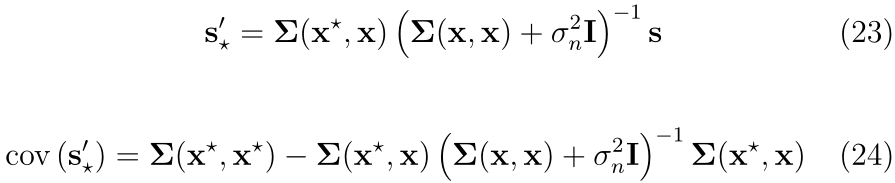
�����ģ��һ�ֳ�������,�������ڻ���ģ�͵�RL������,�ǽ������˵�״̬�ռ仮��Ϊ����,���ж�������ݸ��ʷֲ������������Ͻ���ת������[13]��,transition models�ǻ��ڴӻ������뻷��֮���������еó��ľ������ֵ���߽����ġ���ģ�ͻ��ڶ�ÿ��״̬�ķ���Ƶ�ʡ�ת���ͼ�ʱ������ͳ�ơ���һ��״̬��Ԥ����ͨ��������Է�����ó��ġ�С��ģ�ؽڿ�����(CMAC)��һ�ֻ�������ķ���,��[15]������ѧϰ����ģ�͡�CMAC��[89]������,��һ�ֻ����ص������ֵ���Ƽ������������Ԥ�����ÿ�������������ݡ���[29]��,״̬�ۺϷ������ڻ���״̬�ռ䡣����Կռ���л���,����ѵ�����ݵij���Ƶ��,ÿ���������������ɼ������ڵ�����[18,19]�е�����ʹ��CACM�㷨[90]��״̬�ռ���ɢ��Ϊ��Ԫ��CACM������������,ȷ����������С��֮�����ת��������,��[14,20]��ʹ���˲��������
[91]�н��ܵ��ֲ���Ȩ��Ҷ˹�ع�(LWBR)��[28,56]������ģ��ѧϰ�㷨,������Ҷ˹������L WLR����������ع�ϵ��������˹����,��������Ϊ٤���ֲ���ÿ�������Ԥ���������ѵ�����ݵ�������(��Ȩ�غ�������),����t�ֲ�������
��[24]��,������transition models�ɵ�ǰ״̬��Ӧ����������Ը�˹������������������������Է��̵�δ֪����ͨ������ר�Ҵ����IJο��켣���������(EM)�㷨�����Ż���[27]�л�ʹ���˻���EM�ķ���,����ѧϰ�㷨��������Ԥ��δ����״̬,������Ԥ����ѭ��ר�ҽ��ܵ���ѹ켣������ж���EM�㷨��Ŀ�����ƶϳ�����ÿ��ʱ�䲽�����״̬����Ϊ��DZ�ڱ�������һ��������ɢ״̬�ж��ռ�ķ�����ʹ�ö�̬��Ҷ˹����(DBN)[23]�������ַ�����,MDPת�Ƹ��ʵ�ѧϰ��Ӧ��DBN�ľֲ��ṹ��ѧϰ���������ع��һ�ֱ�������DBN������ѵ����
����ѧϰdynamics models,Ҳ��������ѧϰ����[33,84]����[33]��,���߽���ʹ���������ǰ������ܹ�,����һ�ָ���ģ����ѧ,��һ�ָ���ģ����������������ļ������ѡ��ΪУ�����Ե�Ԫ(ReLU),��Ϊ�볣�õ�ѡ��(��˫������)���,�������ȶ��ԡ����ַ�������һ���ŵ���,������Դ���������IJ�ȷ����,����ѧϰ������Խ����ص�����[84]�н�������һ��ѧϰ��ҵ��е��������ѧ�ķ���,��PC-ESN++,�������߲��ù̶�Ȩ�صĵݹ���������Ϊ���ز㡣�������ලѧϰ������,Ԥ��ͨ��ִ�б�Ҷ˹�ع�ó�,����ֱ�Ӵ��������ƶϡ����㷨���ŵ����ڴ���,���������������ȼ���Ч�ʸ��ߡ�
[92]�������һ��ѧϰtransition dynamics���ܶȹ��Ʒ���,������Ӧ���ڻ���ģ�͵�RL[92,93]����С���������ܶȹ���(LSCD)��ת�Ƹ��ʽ�ģΪ��������ģ�Ͳ�����������ϡ����,���㷨ͨ����С��ƽ������ѧϰ��Щ������LSCD���ŵ���,��GP���,��������ת�Ƹ��ʽ��и�һ��ļ��衣��һ����,�����߱�����Ч��,��Ϊ����Ҫ�����������˽�ת������[93]��,����ͨ��ִ�мල��ά����������������⡣
6. Applications on Robotics

����ģ�͵�ǿ��ѧϰ��Ӧ���ڴ����������ˮ�»���������ĸ��ֻ�����Ӧ�á�ͼ7��֯�˸������ͻ�����ϵͳ��������ס�
6.1 �Զ���ʻ����
6.2 ˫�������
6.3 Robotic Manipulators��
��һ�����ŵ�Ӧ�������ǻ����˵Ŀ��ơ�������������������˵�Ƿ������е�ֵ��˶�����[5-12,15,24,28,32,62,65,67,68]��������[24]��ѵ������������������������,�Ը�����ɴ��������,��һЩӦ����,����ѵ��������ִ�л�������[5,8,11,68]����[5,8]��,ʹ�õ�ƽ̨��һ�����е��ɹؽڵļ��ݷ�����е�֡�״̬�ռ���������,����ÿ���ؽڵ�λ�ú��ٶ�,�������ռ�����ά��,����ʩ�ӵ�Ť�ء��������������,�����˶����ܹ�ƹ������������ѵ��������,��[11]��,һ��3���ɶȵĻ����˱�ѵ����ִ����ë��ڶ���ѧϰִ�л�е�ֵ��˶������Ѿ�Ӧ���ڶ������͵�ƽ̨,����Ƿ������е��[7,15,28],�����ɶȻ�е��(2��3���ɶ�)[6,7,9,10],�Լ������ӵĸ����ɶ�ϵͳ[12,32,67]��
ѧϰ���������λ�ÿ���[6,7,10,15]��PR-2�����˽�ע[33]���ڴ��ڶ�[28,32]�����ӵı��ϲ�������[12,62]���ڴ����Ӧ����,��е�ֵ�״̬�ռ���������,��ÿ���ؽڵ�λ�úͼ��ٶ������������ÿռ�Ҳ��������,��Ӧ�������������ؽ��ϵ�Ť�ء�ͼ(10)�����˻���ģ�͵�RL�ڻ�е���ϵ�Ӧ�÷��ࡣ

ͼ 10:����ģ�͵� RL Ӧ���ڻ����˻�е���ϵķ��ࡣÿ������ķ���������������ģ������ͽ��з��ࡣ