文章目录
摘要
本周一是简单实现了在stata上的空间杜宾模型的具体实现步骤,首先是获取shp 文件,再利用Arcgis或者Geoda生产空间权重矩阵,或者直接创建经济权重矩阵;下一步就是进行被解释变量的空间自相关分析,即莫兰指数的具体实操;以及对空间杜宾模型的在stata实现命令操作,最后便是对模型的解读。
二是对DVI这篇论文的阅读,关于深度分类训练时空因果关系的时间旅行可视化(DVI),在训练深度学习图像分类器的同时体现时空因果关系。时空因果关系展示了梯度下降算法和各种训练数据采样技术如何影响和重塑学习输入表示的布局和连续时期的分类边界。也就是将各图像分类器的预测过程进行全景分类景观可视化了。
一. Stata 实现空间杜宾模型过程
1.空间权重矩阵的生成
1.1 获取地图json数据文件
首先是获取地区的shap文件,通过阿里云API去获取json数据:如下图所示
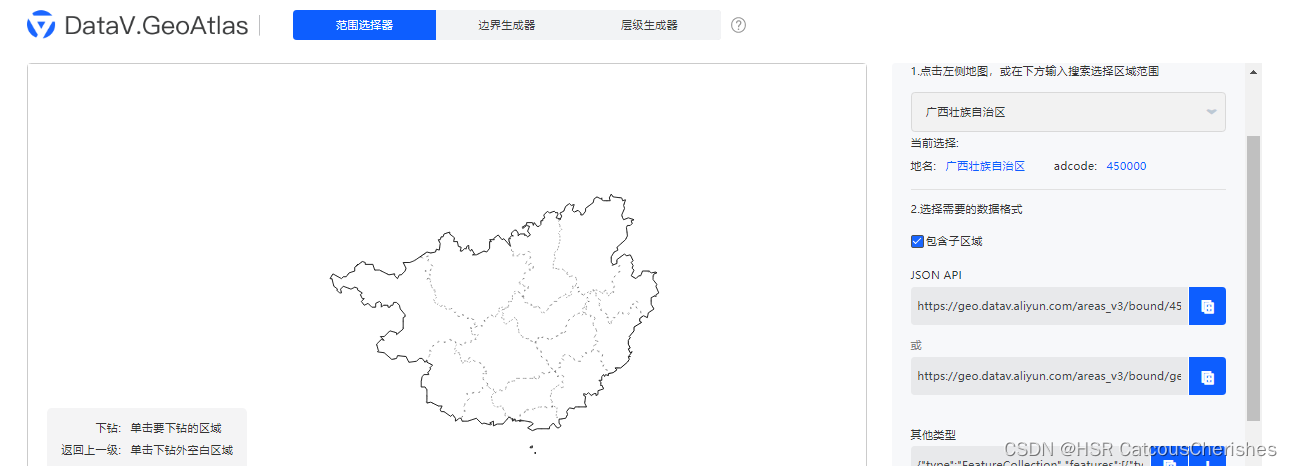
以下载广西数据为例
-
复制红框中第一条或第二条网址,用浏览器打开
-
复制网址中全部内容,放入自行创建的json文件中。(可以先自行创建txt文件,复制完内容后,直接更改后缀名即可变为json文件)
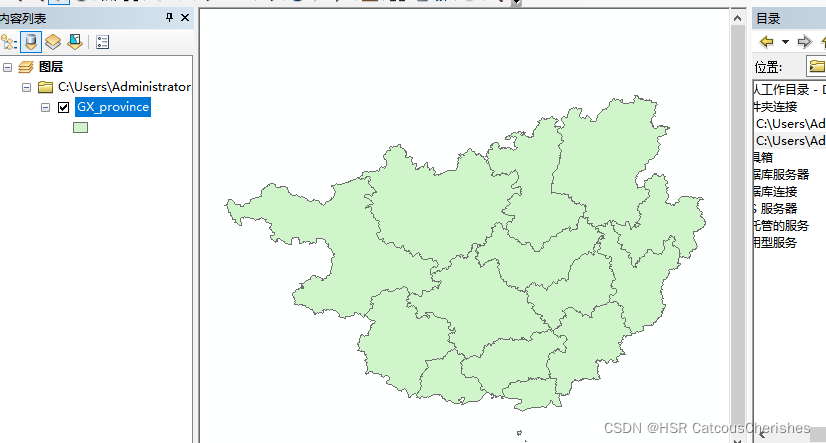
1.2 获取市级行政单元Shapefile
借助python中强大的空间分析库geopandas即可将geojson文件转为shapefile文件。(直接pip会报错,它依赖于这四个库gdal、Shapely、Fiona、pyproj) python一键获取区域shp 文件。
将获取得到的json 文件在安装好geopandas中执行以下代码即可:
import geopandas
import os
os.chdir('C:/Users/Administrator/Desktop/') #工作路径转为桌面
def saveShapefile(file_name,output_shapefile_name):
try:
data = geopandas.read_file(file_name)
localPath = str(output_shapefile_name)
data.to_file(localPath, driver='ESRI Shapefile', encoding='gbk')
print("转化成功,文件存放位置:"+localPath)
except:
print("转化失败")
saveShapefile('广西壮族自治区.json','GX_province')
最终生成文件如下图所示,dbf文件内容(可正常显示)如右图所示:
1.3 Arcgis创建空间权重矩阵
参考博客:空间权重矩阵的创建
ArcToolBox―空间统计工具―空间关系建模―生成空间权重矩阵
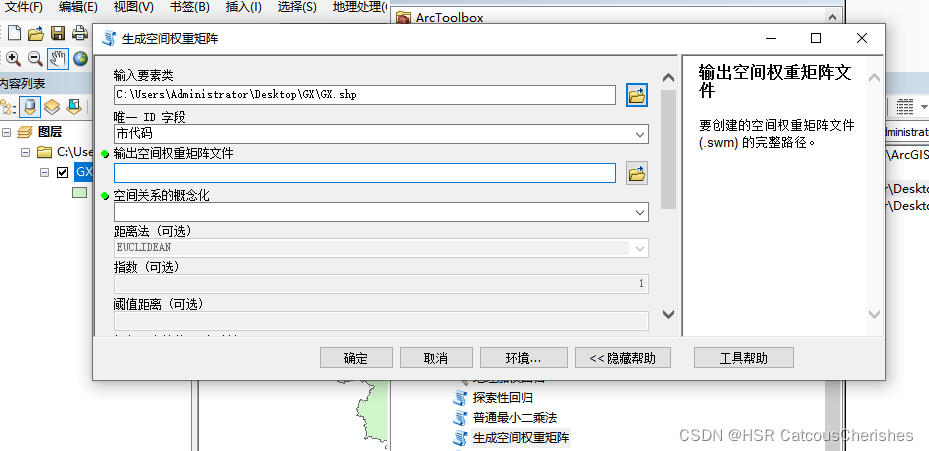
最终生成的是swm文件,还需要将其转化为表。
空间统计工具――工具――将空间权重矩阵转化为表(为dbf 文件)
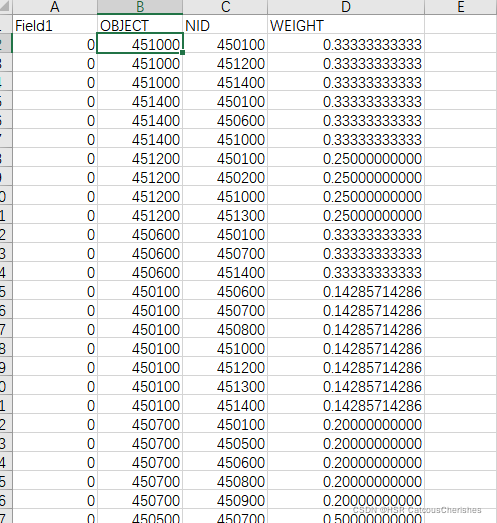
在参考文章是通过R语言将上面得到的dbf转换成n*n的矩阵(01模式:相邻为1,不相邻为0,并且一定是一个对称矩阵,否则后续会报错的!)。
表示对R语言真的看不懂。。。。。
swm2mat <- function(dbf) {
library(foreign)
swm <- read.dbf(dbf)
units <- as.character(unique(swm[,2]))
n <- length(units)
mat <- matrix(0, nr=n, nc=n)
dimnames(mat) <- list(units, units)
i <- as.character(swm[,2])
j <- as.character(swm[,3])
w <- swm[,4]
Map(function(i,j,w) mat[i,j] <<- w, i, j, w)
return(mat)
}
spmat <- swm2mat("aaa_swm.dbf")
获取到广西市级地区的空间权重矩阵(01邻接),其表示如下图:
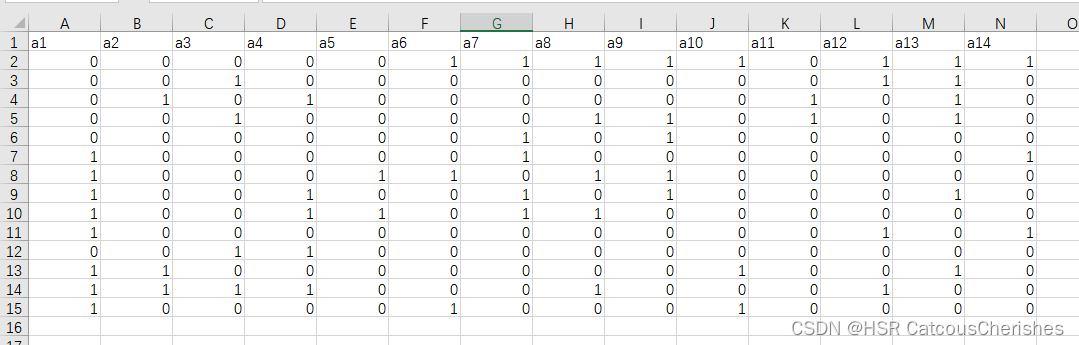
得到了空间权重矩阵,下一步将其复制导入到stata中,并创建保存为dta的格式文件。
1.4 创建经济距离权重矩阵
参考博文:经济距离矩阵的创建
1.准备数据:第一列为市级地区名,第二列为计算指标,这里为某段期间内人均GDP的平均值(本例子只是利用2020年的数据)
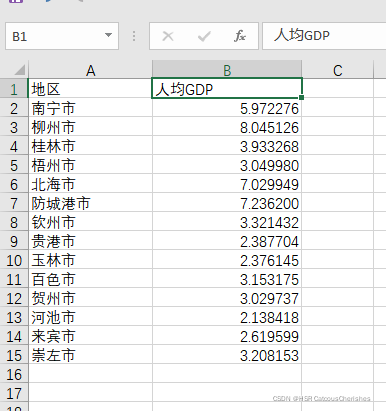
- 通过python 代码实现经济矩阵的创建
import pandas as pd
import math
#经济距离矩阵构建
data = pd.read_excel(r'C:\Users\Administrator\Desktop\ecnomic_data.xlsx',sheet_name= 0)
loc_a = list(data.loc[:,"地区"])
loc_data = []
for loc_1 in loc_a:
weight_list = []
for loc_2 in loc_a:
value_1 = data[data['地区']==loc_1]['人均GDP'].values[0]
value_2 = data[data['地区']==loc_2]['人均GDP'].values[0]
weight = 1/abs(value_1-value_2)
if math.isinf(weight):
weight = 0
else:
pass
weight_list.append(weight)
print(loc_1+'-'+loc_2+'计算完成')
loc_data.append(weight_list)
eco_weight = pd.DataFrame(loc_data,index=loc_a,columns=loc_a)
eco_weight.to_csv('eco_weight.csv',encoding='gbk')
如上就得到了经济距离矩阵:
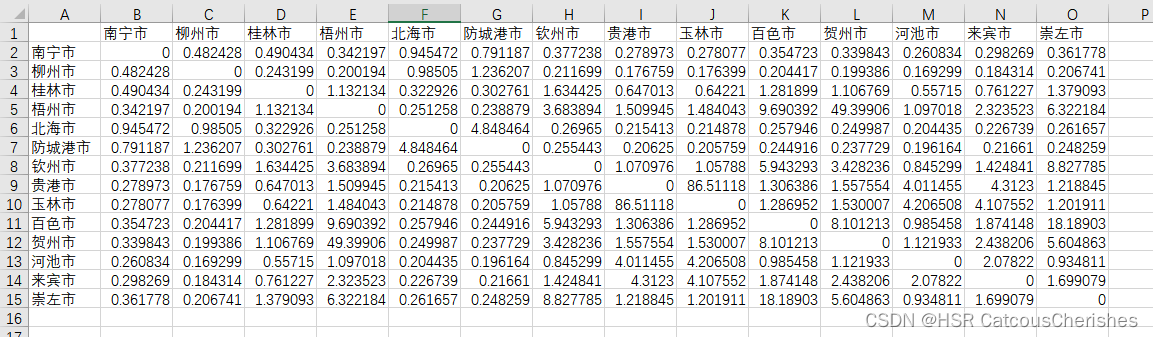
2.莫兰指数分析
2.1 收集整理需要被解释分析的变量
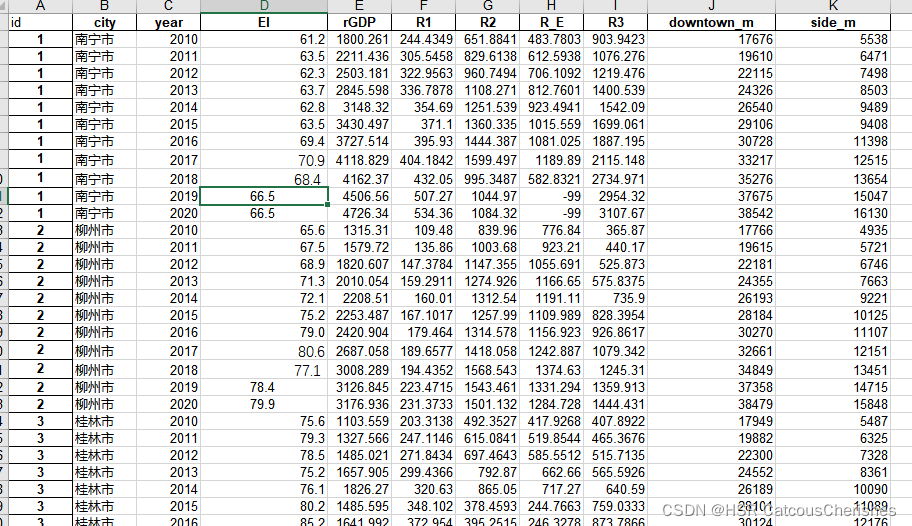
1.是通过整理历年(2010-2020)的广西市级区域的EI(生态环境综合指数),如图:
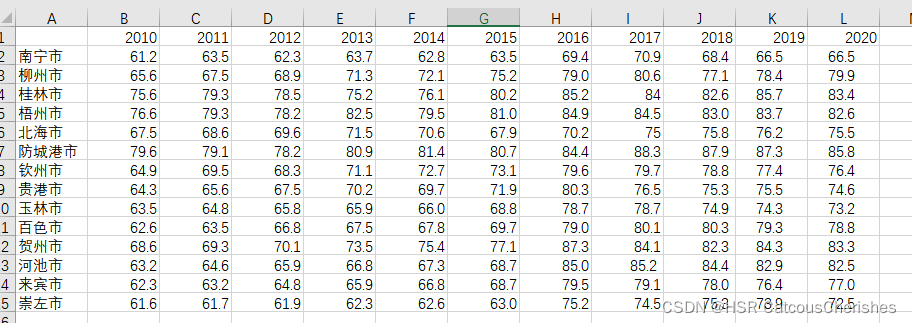
2. 上述的EI是被解释的变量,继续收集整理其各解释变量形成的面板数据。
格式如下图所示:
2.2 莫兰指数的计算
在stata的中创建do-file执行:
全局莫兰指数的计算
// 1. 调整执行路径
cd "E:\Users\stata01
=================================计算莫兰值============================
import excel "C:\Users\haisea\Desktop\韧性.xlsx", sheet("Sheet1") firstrow
// 2. 导入EI(execl)数据
import excel "E:\Users\stata01\EI_data.xlsx", sheet("Sheet1") firstrow
spatwmat using F:\stata操作data\ecoweights.dta,name(w1) standardize
//3 .定义空间权重矩阵:01矩阵权重
spatwmat using E:\Users\stata01\Queen-weight.dta,name(w2) standardize
ssc install asdoc
// 执行全局莫兰指数的计算
spatgsa B C D E F G H I K K L ,weights(w2) moran
spatwmat using F:\stata操作data\weights.dta,name(w) standardize //01矩阵
其结果显示如下:
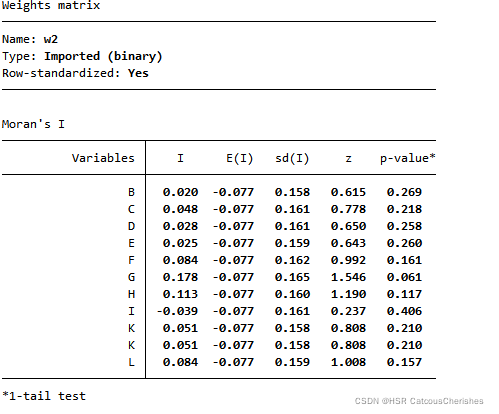
由此可见莫兰指数分析:其P值都>1%,其I值大部分是空间正相关。
局部莫兰指数的计算
在stata 中继续执行:
matrix list w //查看所建矩阵
spatlsa B,weights(w) moran //计算局部莫兰
spatlsa B,weight(w) moran graph(moran) symbol(n) //以ID数字表示
//计算局部莫兰分析,并画出图如下
spatlsa L,weight(w2) moran graph(moran) symbol(n)
spatlsa B,weights(w2) moran
spatlsa L,weights(w2) moran
spatlsa L,weight(w2) moran graph(moran) symbol(id) id(A)
莫兰指数图:
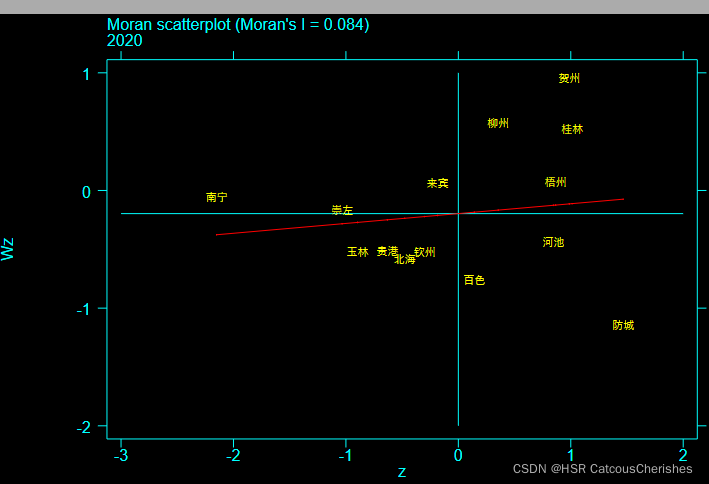
局部莫兰指数分析:
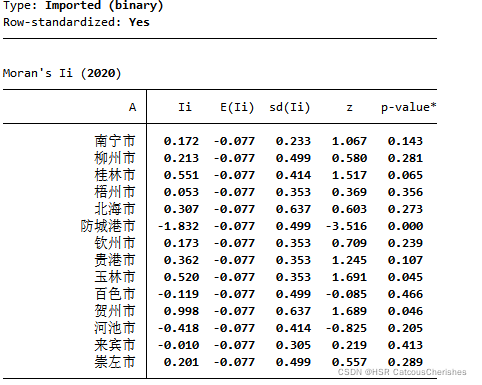
通过全局莫兰与局部莫兰指数分析,发现其大部分是具有空间效应的,可继续对其进行下一步分析。下面是三个检验(LM检验,LR检验,Hausman检验):

3. 空间杜宾模型简单实现
可以参考概念:之前自己做的总结:空间自相关分析概念与大致思路
1.导入面板数据
首先是做LM检验,用来检验用不用空间计量模型,或者需要用哪个。
空间计量模型:
第一步:先执行LM检验,检测空间自回归效应
//将01矩阵设置为空间格式
clear
use Quenn1
spcs2xt a1-a14,matrix(aaa)time(11)
spatwmat using aaaxt,name(Qmatrix)
gen(ntrade=log(trade)
summarize oh lntrade lnzhuanli thir lnlvdi lnpergov rRMBcd //描述性统计分析
reg y x1 x2 x3
//spatwmat用于定义空间矩阵;spatlsa用于进行局部自相关检验;spatgsa用于进行全局自相关检验;spatcorr用于考察空间自相关对距离临界值d的依赖性
//spatdiag针对ols回归结果,诊断是否存在空间效应;spatreg用于估计空间滞后与空间误差模型。
//pwd显示当前目录
============[1]LM检验,检验是否有空间效应=============================
reg oh lntrade lnzhuanli thir lnlvdi lnpergov rRMBcd
import excel "E:\Users\stata01\data.xls", sheet("Sheet1") firstrow
reg EI rGDP R1 R2 R_E
spatdiag,weights(Qmatrix)
注:这是行标准化过的空间权重矩阵,Qmatrix为标准化的空间矩阵。
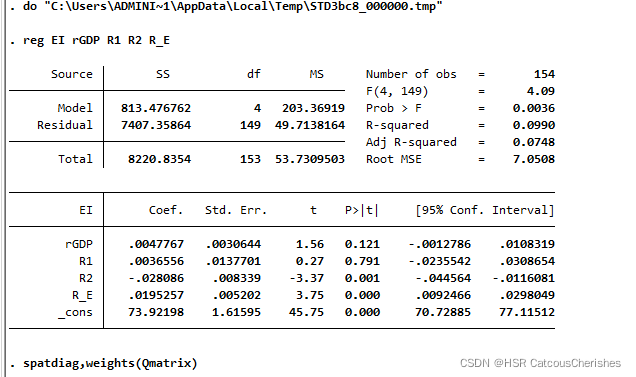
根据结果发现P值是小于0.05的,其模型拟合度也是可以的。
spatdiag针对ols回归结果,诊断是否存在空间效应
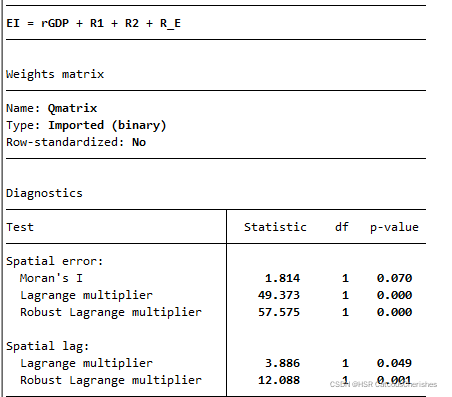
结果发现空间误差模型的LM和Robust LM检验结果都是显著的(P值均小于0.05);空间滞后模型的检验P值也是均小于0.05,但是可以看出其空间误差模型要由于滞后模型。所以综上,第一步LM检验通过,模型应该选用带空间效应的面板模型。
第二步:对模型的效应类型进行检验,即检验是否是固定效应,还是随机效应。
===========霍斯曼检验,检验是固定效应还是随机效应=============================
第一种方法
xtset id year
spatwmat using E:\Users\stata01\Queen1.dta, name(w) standardize
xsmle EI rGDP R1 R2 R_E,model(sdm) wmat(w) fe nolog
est store sdm_fe
xsmle EI rGDP R1 R2 R_E,model(sdm) wmat(w) re nolog
est store sdm_re
hausman sdm_fe sdm_re
第二种方法【爱丁堡大学】
xsmle oh lntrade lnzhuanli lnlvdi lnpergdp lnmidu lnpergov rGDP rpeople,model(sdm) wmat(w2) hausman nolog

这里面的w可以是一般的01空间矩阵,图中霍斯曼检验结果的P值大于10%,所以应该选择随机效应。
第三步:检验SDM模型是否会退化为SARI模型或者SEM模型
[3]LR检验====检验模型是否退化为SAR(空间自回归)或SEM(空间滞后)
spatwmat using E:\Users\stata01\Queen1.dta, name(w) standardize
xsmle EI rGDP R1 R2 R_E ,model(sdm) wmat(w) fe nolog noeffects
est store sdm_a
xsmle EI rGDP R1 R2 R_E ,model(sar) wmat(w) fe nolog noeffects
est store sar_a
xsmle EI rGDP R1 R2 R_E ,model(sem) emat(w) fe nolog noeffects
est store sem_a
lrtest sdm_a sar_a
lrtest sdm_a sem_a
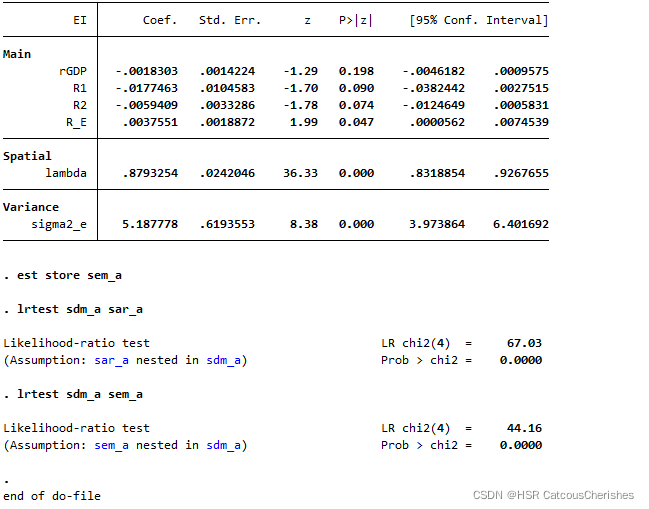
由上图结果可见,不管是SDM与SAR比较还是与SEM比较,都发现其有非常强的显著性。说明我们的SDM模型是不能退化为SAR或者SEM模型的。
最终结果:我们可以发现应当选择带随机效应的空间杜宾模型去进行空间的相关性分析。
==========最终结果===========
//这一步是显示不带空间效应的模型结果会是如何的
spatwmat using E:\Users\stata01\Queen1.dta, name(w) standardize
xsmle EI rGDP R1 R2 R_E ,model(sdm) wmat(w) nolog noeffects
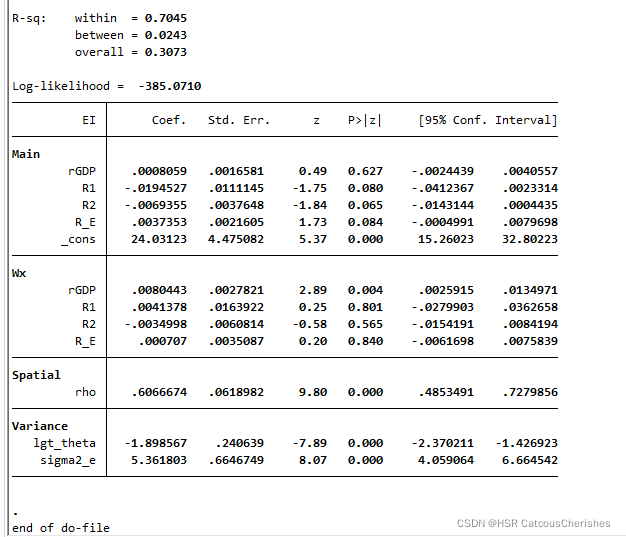
我们发现其空间模型拟合程度只有30%左右,却在结果分析中只有rGDP 的P值小于10%,但是其空间效应是显著的。
最后我们执行一个带有随机效应的空间杜宾模型的操作命令:
//执行空间杜宾模型
xsmle EI rGDP R1 R2 R_E ,model(sdm) durbin(rGDP) re wmat(w) nolog effects
结果显示如下图:
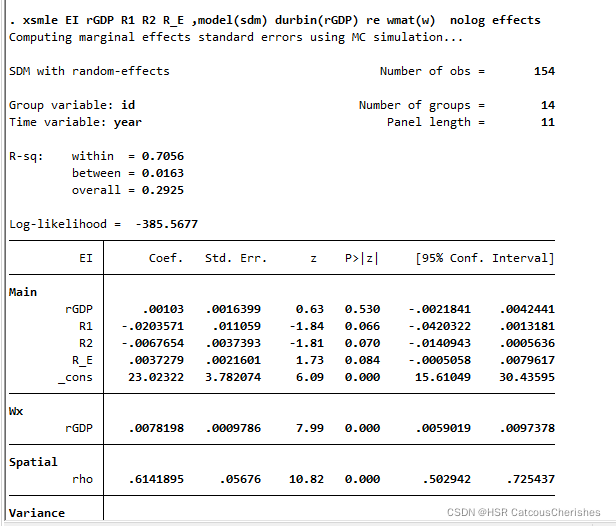
4. 关于空间杜宾模型的具体解读
结果解读不是特别准确,后面需要更具解释变量去再次改进该模型的最终效果分析。
模型结果分析:
X为解释变量(rGDP,R1,R2),Y 为被解释变量(即EI生态综合指数)。
Main
显著则说明x对y的影响显著
W
显著则说明x对y有空间溢出效应。
Spatial
显著则说明y有对自身的空间溢出效应。
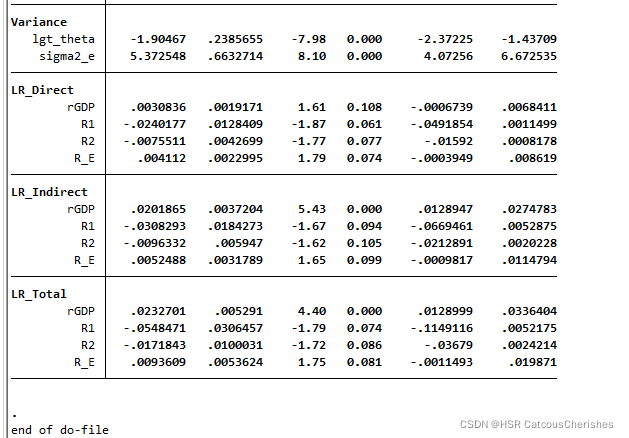
9.溢出效应分解
简单来说:
直接效应:本地区X――>本地区Y的影响
间接效应:邻近地区X――>本地区的Y ,邻近区域的X――>邻近区域的Y――>本地区的Y的影响
LR_Direct
直接效应:同区域x对y的影响程度
LR_Indirect
间接效应:其他区域x对y的影响程度
LR_Total
总效应:所有区域x对y的影响程度
总结
目前面板数据的解释变量只有rGDP有较好的解释性,下一步需要从这里改进,加入人口总数,生态数据,这样也许会更好的结果分析。
二. 论文-DeepVisualInsight: Time-Travelling Visualization for Spatio-Temporal Causalit of Deep Classification Training
深度视觉洞察――深度分类训练时空因果关系的时间旅行可视化
作者:杨向林、云林、刘若芳~等
单位:新加坡新加坡国立大学计算学院+北京大学教育部高置信度软件技术重点实验室
1. 论文摘要
了解深度学习模型的预测是如何在训练过程中形成的,对于提高模型性能和修复模型缺陷至关重要,尤其是当我们需要调查非平凡的训练策略(如主动学习)和跟踪意外训练结果(如性能退化)的根本原因时。在这项工作中,我们提出了一种时间旅行视觉解决方案 DeepVisualInsight (DVI),旨在在训练深度学习图像分类器的同时体现时空因果关系。时空因果关系展示了梯度下降算法和各种训练数据采样技术如何影响和重塑学习输入表示的布局和连续时期的分类边界。这种因果关系使我们能够在可见的低维空间中观察和分析整个学习过程。从技术上讲,我们提出了四个空间和时间属性,并设计了我们的可视化解决方案来满足它们。当在可见的低维和不可见的高维空间之间逆向投影输入样本时,这些属性保留了最重要的信息,以进行因果分析。我们广泛的实验表明,与基线方法相比,我们在空间/时间属性和可视化效率方面实现了最佳可视化性能。此外,我们的案例研究表明,我们的视觉解决方案可以很好地反映各种训练场景的特征,显示出 DVI 作为分析深度学习训练过程的调试工具的良好潜力。
文章idea
是在训练深度学习图像分类器的同时体现时空因果关系。时空因果关系展示了梯度下降算法和各种训练数据采样技术如何影响和重塑学习输入表示的布局和连续时期的分类边界。
2. Introduction
在训练和分析深度学习模型时,解释模型预测是一个重新设计好的挑战。已经提出了各种可解释的人工智能技术来理解模型预测,包括输入属性分析、训练数据分析、模型抽象等。通常,现有的解决方案侧重于:
- 个体预测分析:识别个体输入的最重要特征,以解释模型预测。
- 训练数据切片:确定影响模型的最有影响力的训练样本。
- 模型抽象:抽象一个简化模型(如支持向量机和决策树)来解释深度学习模型。
尽管这些技术有助于解释经过训练的模型,但很少有人提出要解释在训练过程中模型预测是如何形成的。虽然渐进式训练信息可能有用,但很难抽象出底层模型演化语义。语义问题可以(但不限于):(1)训练过程如何逐渐提高模型的稳健性,并重塑分类边界?(2) 模型如何在牺牲其他样本的同时,逐渐做出权衡,以适合某些样本?(3) 模型如何努力适应和学习硬样本?
在本论文任务中,我们设计了一个时间旅行可视化解决方案DeepVisualInsight(DVI),重点展示了深度学习分类器训练过程的时空因果关系。DVI将学习到的输入表示及其分类景观投射到一个可见的低维空间中,从空间和时间的角度展示了模型预测是如何在训练阶段形成的。
在空间上,DVI可视化了(1)学习输入表示的布局和(2)描述每个类的“区域”的分类景观。
在时间上,DVI可视化了(1)分类环境和训练输入表示如何在训练时期演变,(2)新的采样训练输入如何重塑分类边界。时空信息允许我们观察训练异常(例如噪声数据集)并验证一些特定的训练策略(例如主动学习采样策略的有效性)。
我们设计DVI以支持开放式开发。也就是说,DVI忠实地反映了通过训练过程学习模型的深度,这不仅确认了已知的模型属性,还支持发现未知现象和模型缺陷。
我们的方法将输入作为在不同训练阶段训练的分类器及其训练/测试数据集,然后学习可视化模型(即通过自动编码器),以(1)将高维样本投影到可见的低维空间,(2)将低维点反向投影回高维空间(用于可视化分类景观),(3)确保可视化模型能够满足一组空间和时间约束。我们为任何时间旅行可视化解决方案提出了四个可视化属性,以保持(1)高维和低维流形之间的拓扑结构,(2)训练样本表示和潜在决策边界之间的距离,(3)低维/高维空间投影和逆投影后样本的语义,(4)在经过训练的分类器中,可视化景观按时间顺序的连续性。总之,我们做出以下贡献:
- 提出了时间旅行可视化解决方案DeepVisualInsight(简称DVI),其目的是可视化具有时空因果关系的分类景观,以便于验证模型属性和发现新的模型行为。
- 我们为任何时间旅行可视化技术提出了四个时空属性,并设计了一个深度学习解决方案来满足它们,以反映分类景观。
- 构建了可视化框架DVI,以支持各种深度分类器的可视化。
- 进行了大量的实验和案例研究,展示了(1)DVI满足属性的有效性,以及(2)DVI如何帮助理解训练过程和诊断模型行为。
3. Motivating Example
下图显示了我们在 CIFAR-10 数据集上的对抗性训练过程的可视化。每个点代表一个样本,每种颜色代表一个类别。点的颜色代表样本的标签,区域的颜色代表预测的类别。例如,位于棕色(狗类)区域的红色(猫类)点表示它被标记为猫但被分类为狗。此外,颜色阴影表示预测的置信度,不自信的区域(即分类边界)被可视化为白色区域。总体而言,分类区域和边界形成分类景观。
在这里,模型拟合过程通过以下过程可视化:(1)重新塑造分类边界和(2)将那些数据点拉向相应颜色的区域。

上图显示,DVI体现了(1)当模型适应新的对抗性和训练样本时的边界重塑过程,以及(2)在对抗性稳健性和测试准确性之间进行权衡的过程。
为了清楚起见,我们在图1中显示了一个测试点(带黄色边缘的大红点)和它的十个最近邻对抗点(棕色)。在对抗性训练期间,(1)对抗点逐渐被拉到其颜色对齐的区域,而(2)测试点也逐渐从其颜色对齐的区域“拉”到其敌对邻居的区域。(测试点会随着迭代次数被拉进其敌对类中)这种权衡是逐渐形成的。
在(DVI 2021)中,我们可以通过可视化整体数据点的动态来进一步显示这种权衡的存在。DVI工具可以进一步将过程可视化为动画。此外,它还支持样本和迭代查询,以便用户观察感兴趣的样本和迭代的动态,深入了解模型训练过程。
为任何时间旅行可视化技术提出四个属性:
Notation Definition(符号定义)

我们使用表 1中的符号。我们有一个用于 C 类分类问题的主题模型 c(.)。 输入空间表示为 S,其中 S ? Rd。 S = [s1, s2, …sN ]T 是训练输入集。 f : Rd → Rh 是一个特征函数,使得 x = f(s) 是输入 s ∈ S 的具有 h 维的表示向量。我们将表示向量的流形空间表示为 X,其中 X ? Rh。 训练数据的学习表示表示为 X,其中 X =[x1, x2, …xN ]T。 令 g : Rh → RC 为预测函数,其中 g(x)i 表示第 i 个类的 logits。 分类器 c 由 f 和 g 组成,即 c = g ? f : Rd → RC。
投影函数 φ:Rh→Rl,将流形空间X投影到可见的低维空间Y,其中Y=Rl(l is 2 or 3)。 将 X 投影到 Y(即 Y=φ(X))会产生对应的 Y= [y1,y2, …yN]T。
逆投影函数 ψ:Rl→Rh,其中将可见的低维空间 Y 反向投影回
表示空间 X.
这下面四个属性需要重新细读理解:
1. 邻域保持性
2. 边界距离保持性
3.逆投影保持性
4.时间保持性
4. 文章研究方法
概述:

如图所示,DVI将一个按时间顺序训练的分类器序列C = {c1, c2, …, cT }作为主题模型,并生成相应的可视化模型序列(即自动编码器)V = {V 1, V 2, …, VT } 导出可视化分类景观。 我们使用上标来表示所有符号的时间顺序。 对于每个可视化模型V t = (hφt, ψt)i,编码器作为投影函数φt,解码器作为反投影函数ψt。
针对 ct 的每个可视化模型 V t 都针对四个空间和时间属性进行了训练。 我们
(1) 估计 ct 的代表性 δ 边界点;
(2) 为边界/训练表示向量构建一个拓扑复合体,并在投影后保留其结构以满足(边界)邻域保留特性;
(3) 最小化 x 和重建的 ψt(φt(x)) 之间的距离以满足逆投影保持特性;
(4) 建立 (1) φt 和 φt-1 和 (2) ψt 和 ψt-1(t ≥ 2) 之间的连续性以满足时间保持性。
这里对DVI的 具体的研究方法 没有读懂!
评估
数据集和主题模型:我们选择三个数据集,即,MNIST(60K/10K 训练/测试集),Fashion-MNIST(60K/10K 训练/测试集)和 CIFAR-10(50K/10K 训练/测试集)。 我们使用 ResNet18 作为主题分类器,全局平均池化层作为特征向量(即 512 维)。
基准线: 我们选择 PCA、t-SNE、UMAP 和 DeepView 作为
基线。 我们在整个数据集上将 DVI 与 PCA、t-SNE、UMAP 进行比较。 DeepView 的实现对其可扩展性超过 1000 个样本有限制,我们通过对 1000 个样本(适合 DeepView 的经验大小)进行训练来比较 DVI 和 DeepView。 与 PCA、t-SNE 和 UMAP 不同,我们使用 DeepView 重复实验 10 次以减轻偏差。 此外,我们随机选择 200 个样本作为多个试验共享的测试集。
文章核心结论
该论文主要是在论述DVI在理解深度学习模型中的预测是如何形成的,可以发挥重要的作用,其旨在训练深度学习图像分类器的同时,去体现时空因果关系――展示了梯度下降算法和各种训练数据采样技术如何影响和重塑学习输入表示的布局和连续时期的分类边界。以及多个案列展现DeepVisualInsight (DVI) 工具,了解如何使用它以及它如何有助于调试深度神经网络。
小结
上面这篇DVI论文的研究方法部分没有完全理解,对其原有的那些可解释性方法,可视化的过程需要了解一些,再对该篇论文与原有的可解释性有什么不同的地方。下一步论文方面,多阅读关于时间序列预测模型,达到SOTA预测效果的较新的文献。