目录
1、认识决策树
原理:最早结构类似于if-else判断结构,利用该种结构分割数据的一种分类学习方法
为了高效的进行决策,所以需要将权值更高的语句最先判断,决定特征的先后顺序
使用哈夫曼树的方法构建?
1.1 信息论基础
1.1.1 信息:
消除随机不定性的东西――香农
1.1.2 信息熵:
衡量消除信息中不确定性程度的指标
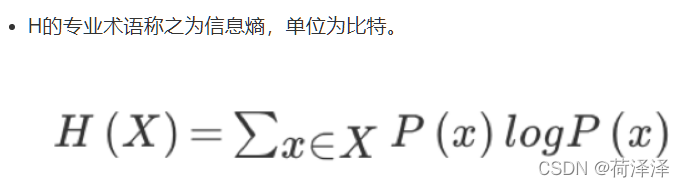
1.1.3 信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差。表示的是当得到某特征时,总的不确定性减少程度
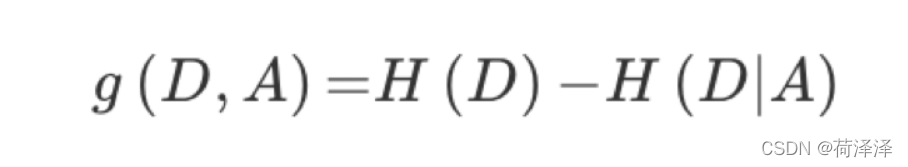
 ?
?
?2,决策树划分依据
- ID3
- 信息增益 最大的准则
- C4.5
- 信息增益比 最大的准则
- CART
- 分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的默认原则
- 优势:划分更加细致(从后面例子的树显示来理解
3,决策树API
- class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- 决策树分类器
- criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
- max_depth:树的深度大小? ? 超参数通过设置树的深度,使模型不要过分延展,提高泛化能力
- random_state:随机数种子
4,预测鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def iris_demo():
"""
利用决策树对鸢尾花数据集预测
:return:
"""
#1.读入数据
iris=load_iris()
#2.划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=22)
#3.建立决策树
estimator=DecisionTreeClassifier(criterion='entropy',max_depth=10,random_state=12)
estimator.fit(x_train,y_train) #将训练集放入模型
#4.模型评估
score=estimator.score(x_test,y_test)
print("预测准确率为:\n",score)
return None
iris_demo()
与KNN算法相比,准确率降低。这是由于,决策树会耗费“代价”进行决策,在进行大型数据集预测时更有利
5,决策树可视化
导入文件?
from sklearn.tree import export_graphviz?运行代码
export_graphviz(estimator,out_file="iristree.dot",feature_names=iris.feature_names)获得.dot文件,再通过其他方式转换成图片
6,总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可能会创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 改进:
- 减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
- 随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
?