����Ŀ¼
���������������
����������
���ع�Ķ��α�ʾ
���ع�
���������֮���ӳ���ϵ����
P
(
y
=
1
�O
x
;
w
,
b
)
=
1
1
+
e
?
(
w
T
x
+
b
)
P(y=1|x;w,b)=\frac{1}{1+e^{-(w^Tx+b)}}
P(y=1�Ox;w,b)=1+e?(wTx+b)1?
����,𝑥Ϊ��������,𝑦Ϊ������
y
=
{
0
,
1
}
y=\{0,1\}
y={0,1}(������������),𝒘,𝑏Ϊѧϰ������
𝒘��Ȩ��,b��ƫֵbias
���ع�Ķ��α�ʾ
1?? ���summing function
R
P
��
R
R^P\rightarrow R
RP��R
z = w T x + b = w 1 x 1 + . . . + w p x p + b z=w^Tx+b=w_1x_1+...+w_px_p+b z=wTx+b=w1?x1?+...+wp?xp?+b
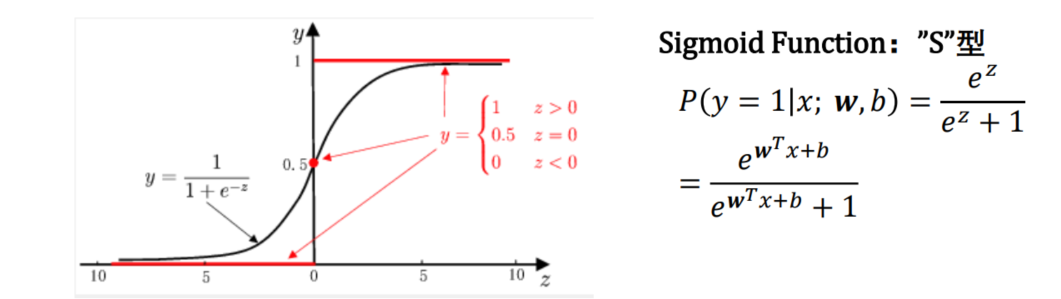
2?? ��ѹsigmoid function
R
��
{
0
,
1
}
R\rightarrow \{0,1\}
R��{0,1}
y ^ = P ( y = 1 �O x ; w , b ) = 1 1 + e ? z = e z e z + 1 \hat y=P(y=1|x;w,b)=\frac{1}{1+e^{-z}}=\frac{e^{z}}{e^z+1} y^?=P(y=1�Ox;w,b)=1+e?z1?=ez+1ez?
��ѹ��������֮ǰ���ع�ѧ����sigmoid function:

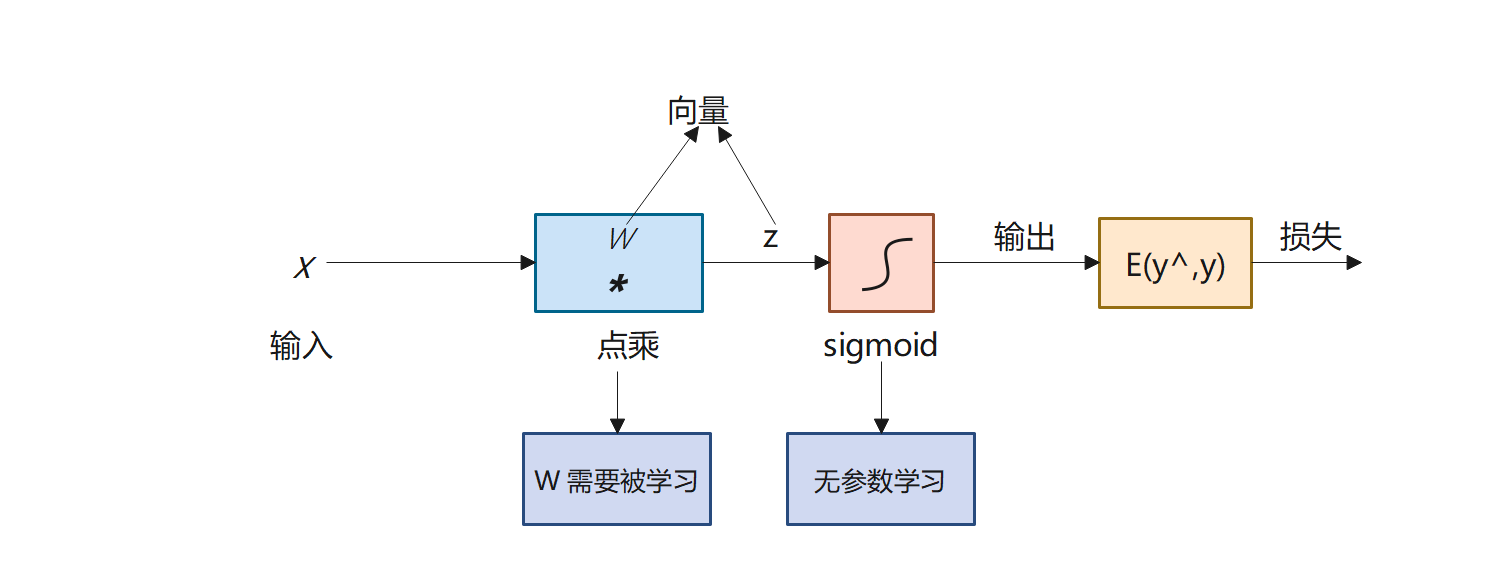
��Ԫ
��������������,ÿ����Ԫ��������Ԫ����,�������˷ܡ�ʱ,��������Ԫ���ͻ�ѧ���ʡ�
�ڻ���ѧϰ��,������ģ�ͳ���Ϊ��ͼ��ʾ�ļ�������ģ�͡���Ԫ��������������Ԫ���ݹ����������ź�,�����ź�ͨ����Ȩ�ص����ӽ��д���,Ȼ��ͨ�����������������Ԫ���

��Ԫ:һ����Ԫ�������Ա任�ͷ����Ա任��ͬ���ɵ�
���,���ع��ǰ���һ����Ԫ��������
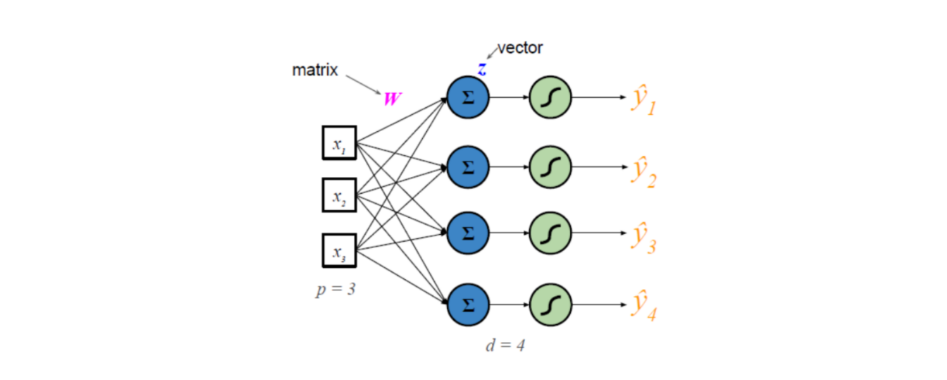
������
��������������Ԫ,����𝒙������Ԫ������W��Ҫ��������չΪ����
𝑊𝑖𝑗��ʾ������x�ĵ�𝑗��Ԫ��������𝑍�ĵ�𝑖��Ԫ��֮�������Ȩ��
������ͼ��������,W����:
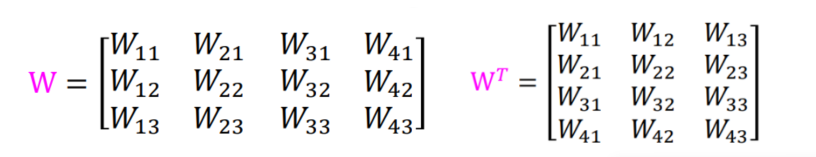
����һ�����ز��������
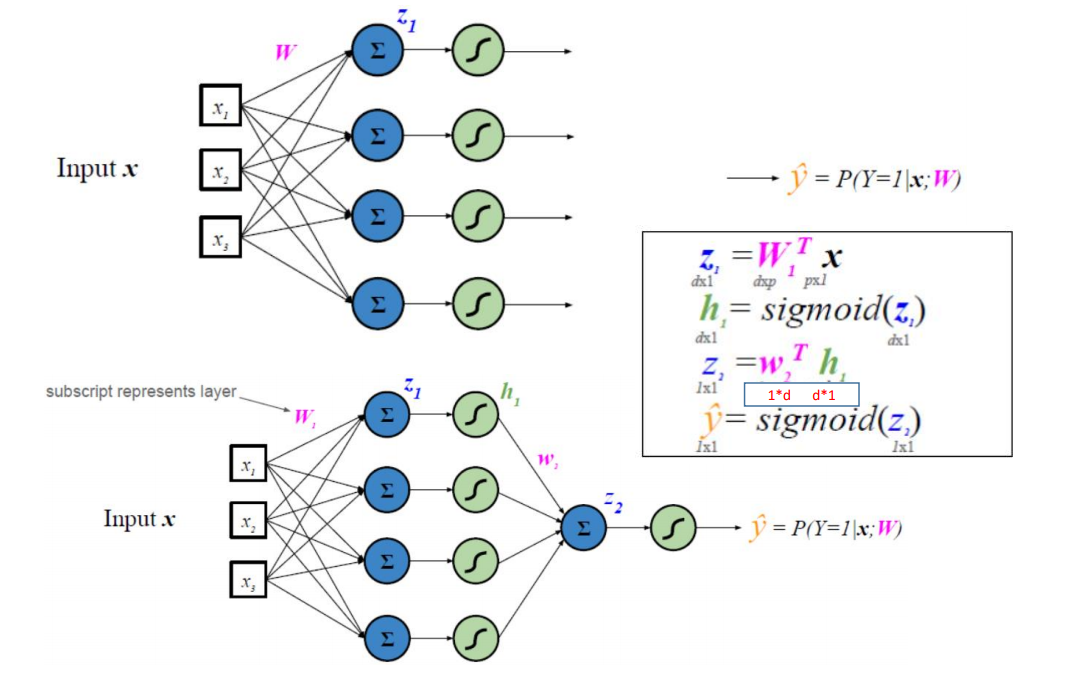
��������������

h1�����ز�����
�����������ز��������
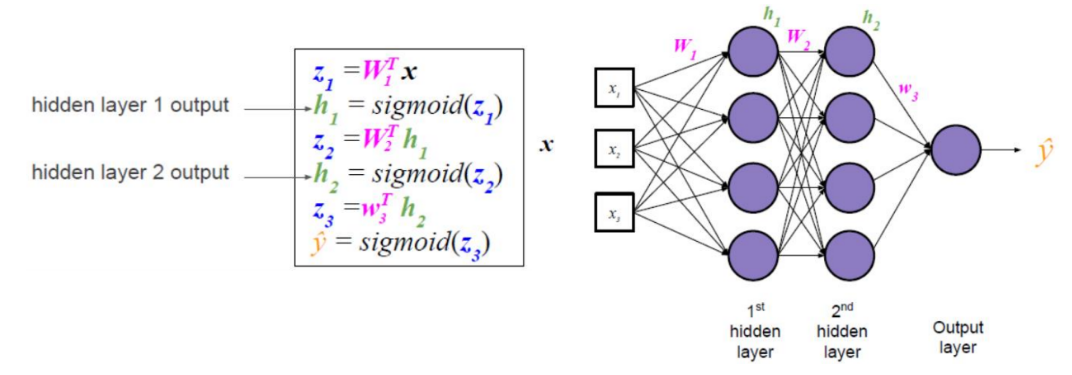
1?? ��Ԫ���Իع�ֱ�ӽ��������������Ĺ�ϵ
2?? ���ع�����һ��summing function��sigmoid function���������������Ĺ�ϵ
3?? �����������˶��summing function��sigmoid function���������������Ĺ�ϵ
�����籾���Ͼ���һ�����Ϻ���
���ﶼ��ȫ����
�����Լ����
��������Լ������Ŀ���ǵõ������Ծ�����
�����������,���Լ����ֻ��������Ծ�����(�������������Ժ���)��
�����Լ�������Աƽ����⸴�Ӻ�����


�� y ^ = 1 2 \hat y=\frac{1}{2} y^?=21?���������жϵ�,��ʱʹ֮�����ı߽��Ϊ������
���õķ����Լ����
| ���� | ͼ�� | ���� | ���� |
|---|---|---|---|
| Binary step | 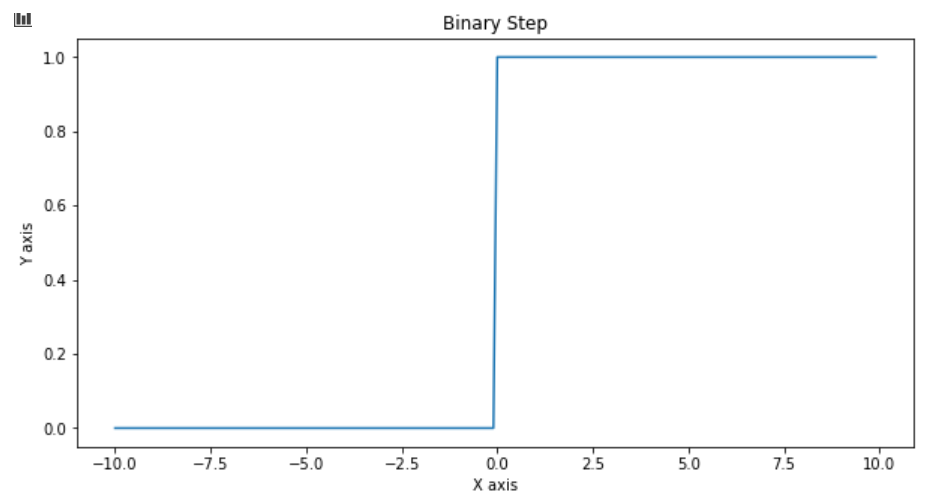 | 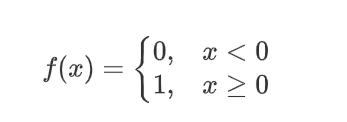 | 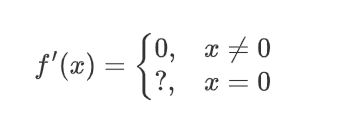 |
| Logistic(a.k.a Soft step) | 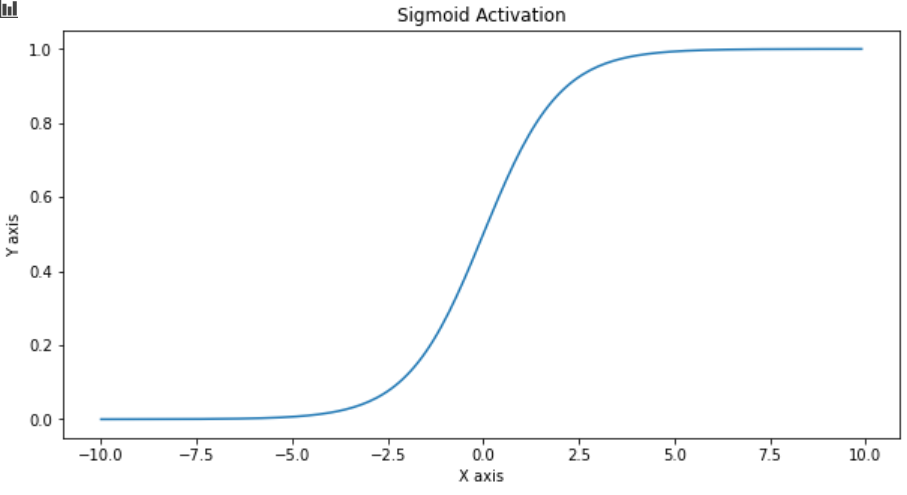 | 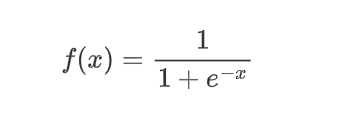 | 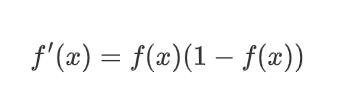 |
| TanH | 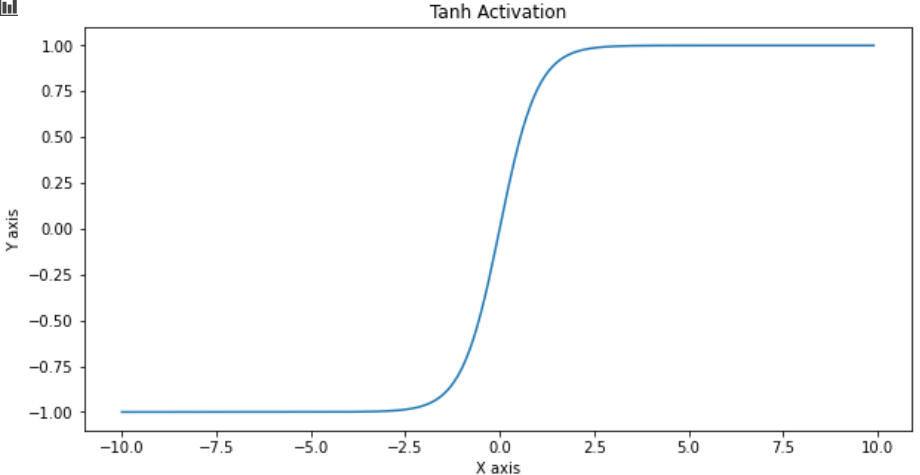 | 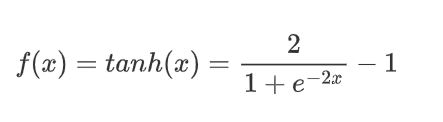 | 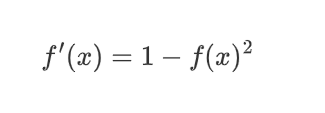 |
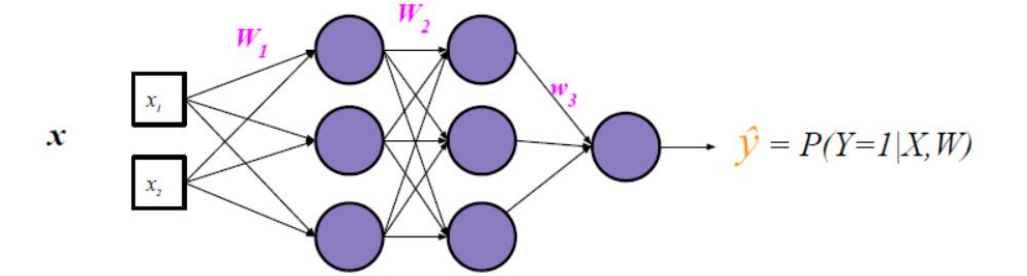
| ReLU | 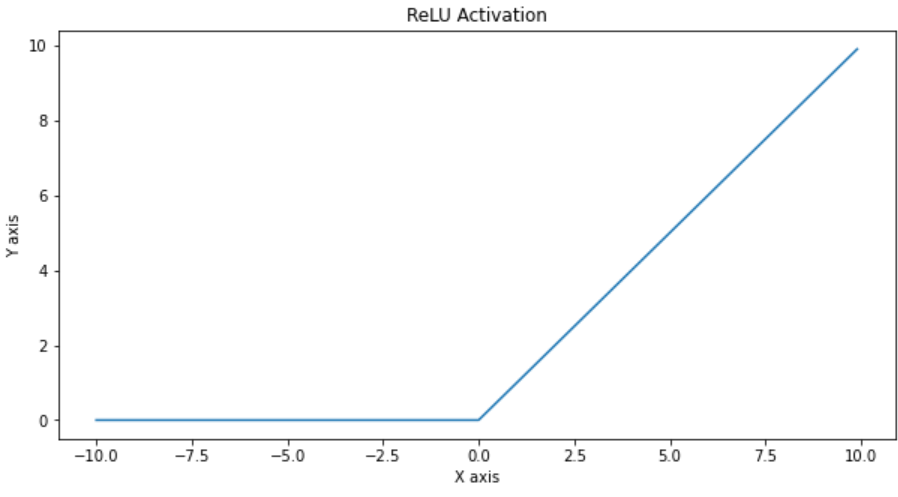 | 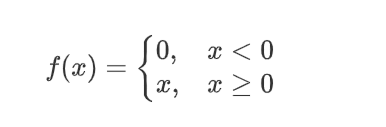 | 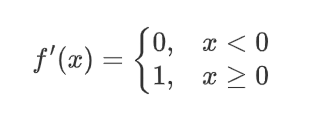 |
Hidden layer(����)�ĸ�������1��������,��Ϊ���������
ѵ��������
��ʧ����
��������ʧ
���ع���,ʹ�ö�����Ȼ������ʧ(ÿ��������������ʵ��ǵĸ���Խ��Խ��)
�����ش��ۺ���cross entropy loss
E
=
l
o
s
s
=
?
log
?
P
(
Y
=
y
^
�O
X
=
x
)
=
?
y
log
?
(
y
^
)
?
(
1
?
y
)
log
?
(
1
?
y
^
)
E=loss=-\log P(Y=\hat y|X=x)=-y\log(\hat y)-(1-y)\log(1-\hat y)
E=loss=?logP(Y=y^?�OX=x)=?ylog(y^?)?(1?y)log(1?y^?)
y y y����ʵ���, y ^ \hat y y^?��Ԥ�����
y ^ = f �� ( x ) = e w x + b e w x + b + 1 \hat y =f_\theta(x)=\frac{e^{wx+b}}{e^{wx+b}+1} y^?=f��?(x)=ewx+b+1ewx+b?
��ʧ����һ����һ������
�������ʧ
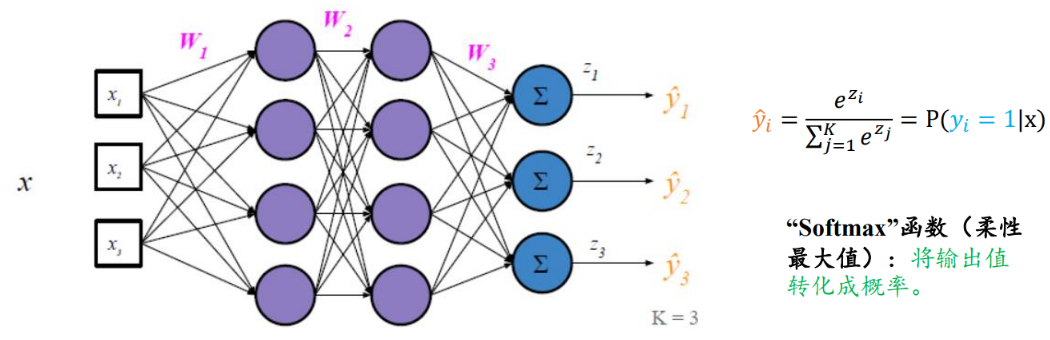
Softmax����:����������ڵ�����ֵ��Χӳ�䵽[0,1],����Լ����������ڵ�����ֵ�ĺ�Ϊ1�ĺ���
�����ش��ۺ���cross entropy loss
E
=
l
o
s
s
=
?
��
j
=
1
,
.
.
.
,
K
y
j
log
?
y
^
j
E=loss=-\sum_{j=1,...,K}y_j\log\hat y_j
E=loss=?j=1,...,K��?yj?logy^?j?
���� y j y_j yj?��One-Hot����:��ʵ��ǩ��λ��Ϊ1,����λ��Ϊ0
One-Hot����,�ֳ�Ϊһλ��Ч����,��Ҫ�Dz���Nλ״̬�Ĵ�������N��״̬���б���,ÿ��״̬�����������ļĴ���λ,����������ʱ��ֻ��һλ��Ч��
����,����
y
T
=
(
0
?
1
?
0
)
,
y
^
T
=
(
?
0.1
?
0.7
?
0.2
)
y^T=(0 \ 1\ 0),\hat y^T=(\ 0.1\ 0.7\ 0.2)
yT=(0?1?0),y^?T=(?0.1?0.7?0.2),����ʧ����Ϊ
E
=
?
(
0
��
log
?
0.1
+
1
��
log
?
0.7
+
0
��
log
?
0.2
)
=
?
log
?
0.7
E=-(0\times \log0.1+1\times\log0.7+0\times\log0.2)=-\log 0.7
E=?(0��log0.1+1��log0.7+0��log0.2)=?log0.7
E
=
l
o
s
s
=
1
2
�O
�O
y
?
y
^
2
�O
�O
=
1
2
��
j
=
1
K
(
y
j
?
y
^
j
)
2
E=loss=\frac{1}{2}||y-\hat y^2||=\frac{1}{2}\sum^K_{j=1}(y_j-\hat y_j)^2
E=loss=21?�O�Oy?y^?2�O�O=21?j=1��K?(yj??y^?j?)2
�ع���ʧ
���������IJ�֮ͬ��:����㲻�ٰ�����Sigmoid������
ʹ�ö��δ��ۺ���
E
=
l
o
s
s
=
1
2
�O
�O
y
?
y
^
2
�O
�O
=
1
2
��
j
=
1
K
(
y
j
?
y
^
j
)
2
E=loss=\frac{1}{2}||y-\hat y^2||=\frac{1}{2}\sum^K_{j=1}(y_j-\hat y_j)^2
E=loss=21?�O�Oy?y^?2�O�O=21?j=1��K?(yj??y^?j?)2
����
Ŀ��:Ѱ��ʹ��ʧ�ﵽ��С��������Ȩ��
���ѧϰ������Ȩ��𝑊𝐿?ʹ���ݶ��½� W L ( t + 1 ) = W L ( t ) ? �� ? E ? W L ( t ) W_L(t+1)=W_L(t)-\eta \frac{\partial E}{\partial W_L(t)} WL?(t+1)=WL?(t)?��?WL?(t)?E?
���� �� \eta ��Ϊѧϰ��
��εõ�𝑊1,��,𝑊𝐿?1���Ȩ��?ʹ�÷���Backpropagation
�ظ�Ӧ�����ֵ���ʽ����
�ֲ���С��Ŀ�꺯��
Ҫ���������еġ��顱(blocks)���ǿ���
��ѧ����˵��
Hadamard (������)�˻�/schur �˻�:
����𝑠��𝑡������ͬ��ά�ȵ�����,ʹ��𝑠��𝑡(��𝑠��𝑡)����ʾ��Ԫ�صij˻�: (𝑠��𝑡)𝑗= 𝑠𝑗𝑡𝑗
[
1
2
]
��
[
3
4
]
=
[
1
?
3
2
?
4
]
=
[
3
8
]
\begin{bmatrix} 1\\2 \end{bmatrix} \odot \begin{bmatrix} 3\\4 \end{bmatrix} =\begin{bmatrix} 1*3\\2*4 \end{bmatrix}= \begin{bmatrix} 3\\8 \end{bmatrix}
[12?]��[34?]=[1?32?4?]=[38?]
�ع�ʾ��
���Ǹ��Ϻ�����ƫ��
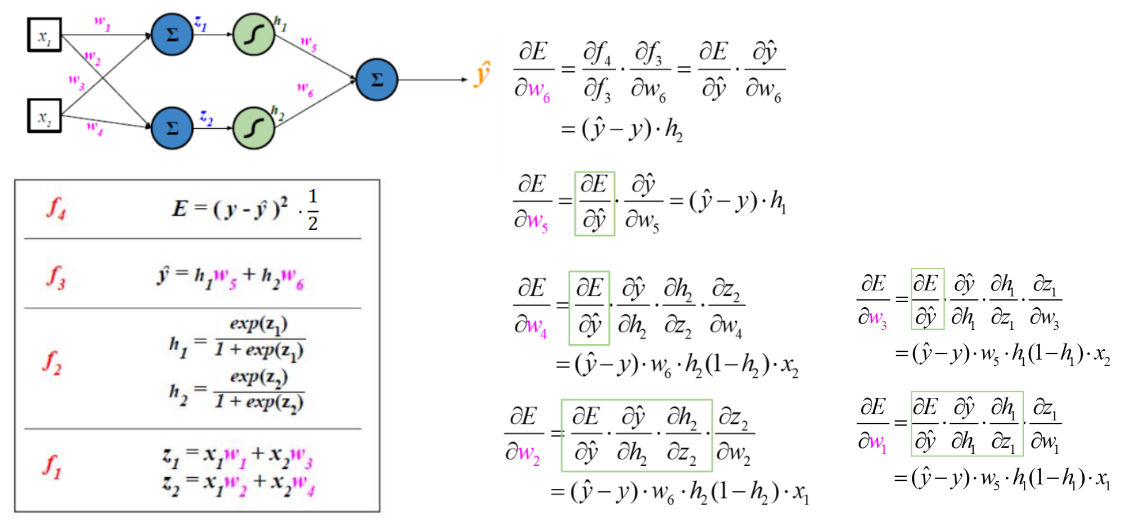
�ɼ��Ѿ��Ƚϸ�����
������ʾ��
����һ������Ķ�����������:
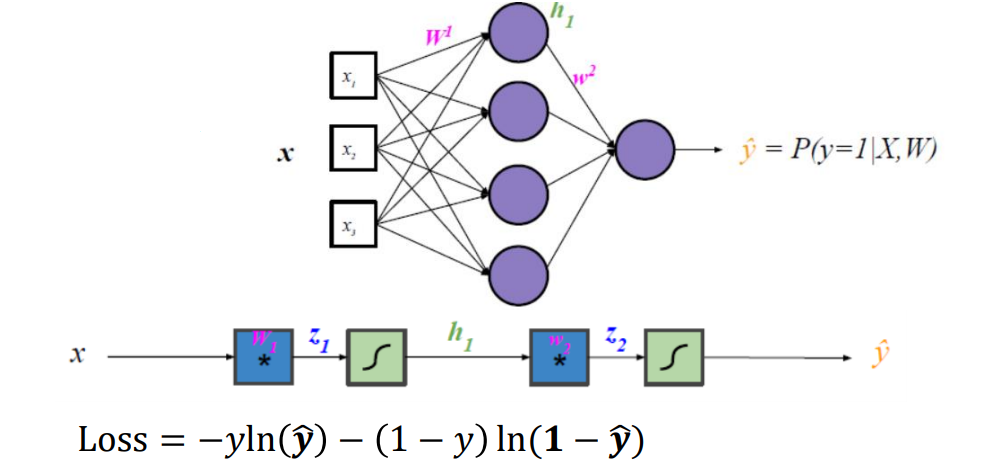
��w2��ƫ�����Ƚϼ�

��W1��ƫ�����Ӻܶ�


w i j 1 w_{ij}^1 wij1?��ʾ����𝒙 �ĵ�𝑗��Ԫ�ص���1������� �� 𝑖����Ԫ��Ȩ��
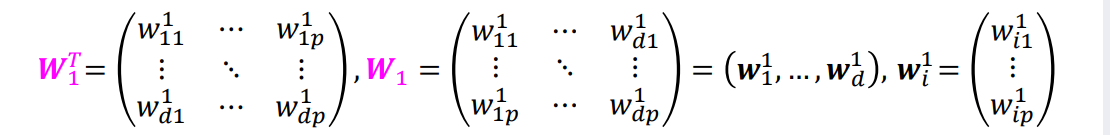
�����Ƶ�����𝑾𝟏�ĵ�һ�� w 1 1 w_1^1 w11?���,Ȼ���Ƶ�����j��,���õ�������������ƫ��
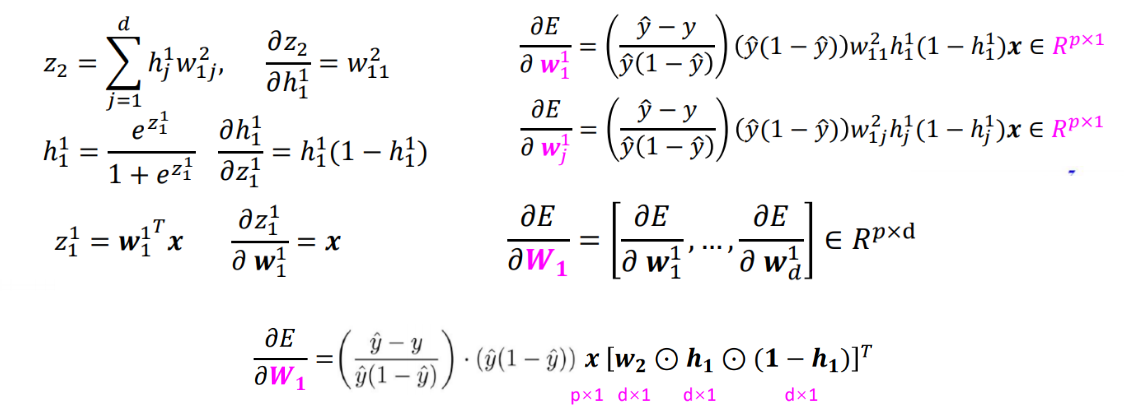
���������ѧϰ
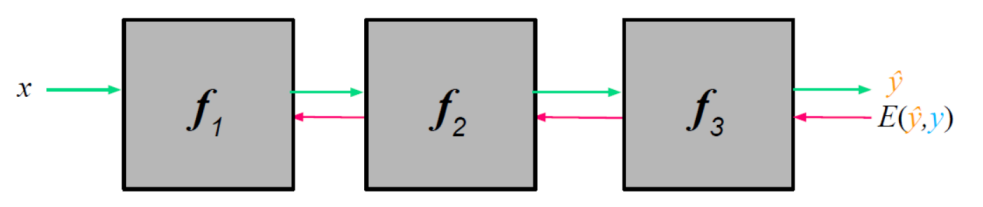
ǰ���ӷ���
| �������� | ǰ�� | ���� |
|---|---|---|
| ���� | 1������һ����ʼ��Ȩ��W | 1�����������ʧ E ( y , y ^ ) E(y,\hat y) E(y,y^?) |
| 2������x | 2��ͨ����ʽ����(���Ϻ�����)�����ݶ� | |
| 3��ͨ�����Ϻ��� y ^ = f 3 ( f 2 ( f 1 ( x ) ) ) \hat y=f_3(f_2(f_1(x))) y^?=f3?(f2?(f1?(x)))����Ԥ��ֵ | ||
| �������� | ��֪��,����ԲȦ���� | ��֪ԲȦ����,���±�(Ȩ��) |
�ظ�����ǰ��ͷ�����,ֱ���㷨������
�����
[1]������.������ͨ��ѧ����ѧϰ����2022��PPT
[2]��־��.����ѧϰ.����:�廪��ѧ������,2016