原始代码位置:?
数据准备的方式和下面这个复现一模一样我就不废话了
?注意里面有东西要装,贴一下我的环境(有删减,仅仅是参考)
Package Version Location
---------------------------------- --------------------- ---------------------
cupy 6.5.0+cuda101
cupy-cuda110 9.6.0
cycler 0.10.0
cymem 2.0.6
Cython 0.29.21
cytoolz 0.9.0.1
easycython 1.0.7
easydict 1.9
efficientnet-pytorch 0.6.3
h5py 2.10.0
ImageHash 4.2.1
imageio 2.5.0
imagesize 1.1.0
json5 0.9.6
keras 2.8.0
Keras-Applications 1.0.8
keras-bert 0.86.0
keras-contrib 2.0.8
keras-embed-sim 0.8.0
keras-layer-normalization 0.14.0
keras-multi-head 0.27.0
keras-nightly 2.9.0.dev2022031807
keras-pos-embd 0.11.0
keras-position-wise-feed-forward 0.6.0
Keras-Preprocessing 1.1.2
keras-self-attention 0.46.0
keras-transformer 0.38.0
labelme 3.16.5
labelme2coco 0.1.2
langdetect 1.0.9
lazy-object-proxy 1.3.1
libarchive-c 2.8
Markdown 3.3.3
MarkupSafe 2.0.1
matplotlib 3.2.2
matplotlib-inline 0.1.3
mayavi 4.7.3
mccabe 0.6.1
MedPy 0.4.0
menuinst 1.4.16
metview 1.8.1
mistune 0.8.4
mkl-fft 1.0.10
mkl-random 1.0.2
ml-collections 0.1.0
mlbox 0.8.5
mmcv 1.3.12
mmdet 2.16.0
mock 2.0.0
more-itertools 6.0.0
mpmath 1.1.0
msgpack 0.6.1
mtcnn 0.1.0
multidict 5.2.0
multipledispatch 0.6.0
munch 2.5.0
munkres 1.1.4
murmurhash 1.0.6
navigator-updater 0.2.1
nbclassic 0.3.1
nbconvert 5.4.1
nbformat 4.4.0
nest-asyncio 1.5.1
networkx 2.2
nibabel 3.2.1
nltk 3.4
nnunet 1.6.6 d:\csdn\nnunet-master
nose 1.3.7
notebook 5.7.8
numba 0.55.1
numexpr 2.6.9
numpy 1.19.5
oauthlib 3.1.0
odo 0.5.1
olefile 0.46
omegaconf 2.0.0
open3d 0.13.0
opencv-contrib-python 3.4.2.17
opencv-python 4.5.2.52
opencv-python-headless 4.5.2.52
openpyxl 2.6.1
opt-einsum 3.3.0
ospybook 1.0
packaging 21.3
pandas 0.25.3
pandocfilters 1.4.2
parso 0.3.4
partd 0.3.10
path.py 11.5.0
pathlib2 2.3.3
patsy 0.5.2
pbr 5.5.1
PCV 1.0
pep8 1.7.1
pickleshare 0.7.5
Pillow 8.2.0
pinyin 0.4.0
pip 19.0.3
pixellib 0.6.6
pkginfo 1.5.0.1
plac 1.1.3
pluggy 0.9.0
ply 3.11
pooch 1.6.0
prefetch-generator 1.0.1
preshed 3.0.6
pretrainedmodels 0.7.4
progressbar 2.5
prometheus-client 0.6.0
prompt-toolkit 2.0.9
protobuf 3.19.4
protobuf-py3 2.5.1
psutil 5.8.0
py 1.8.0
py3nvml 0.2.6
pyaml 21.10.1
pyarrow 5.0.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools 2.0.2
pycocotools-windows 2.0.0.2
pycodestyle 2.5.0
pycosat 0.6.3
pycparser 2.19
pycrypto 2.6.1
pycurl 7.43.0.2
pydeck 0.7.0
pydensecrf 1.0rc2
pyDeprecate 0.3.1
pydicom 2.1.2
pyface 7.3.0
pyflakes 2.1.1
pygeos 0.10
Pygments 2.9.0
PyHamcrest 2.0.2
pykdtree 1.3.4
pylint 2.3.1
pyodbc 4.0.26
pyOpenSSL 19.0.0
pyparsing 2.3.1
pyproj 3.0.0.post1
pyreadline 2.1
pyresample 1.21.1
pyrser 0.2.0
pyrsistent 0.14.11
PySocks 1.6.8
pytest 4.3.1
pytest-arraydiff 0.3
pytest-astropy 0.5.0
pytest-doctestplus 0.3.0
pytest-openfiles 0.3.2
pytest-remotedata 0.3.1
python-dateutil 2.8.0
python-editor 1.0.4
pytorch-lightning 1.0.8
pytorch-toolbelt 0.3.0
pytz 2020.1
PyWavelets 1.1.1
pywin32 225
pywinpty 1.1.3
PyYAML 5.3.1
pyzmq 18.0.0
QtAwesome 0.5.7
qtconsole 4.4.3
QtPy 1.7.0
rasterio 1.2.0
rasterstats 0.15.0
realesrgan 0.2.4.0
regex 2021.4.4
requests 2.21.0
requests-oauthlib 1.3.0
requests-unixsocket 0.2.0
resampy 0.2.2
retry 0.9.2
rope 0.12.0
rsa 4.6
Rtree 0.9.7
ruamel-yaml 0.15.46
sacremoses 0.0.45
scikit-image 0.18.1
scikit-learn 0.22.1
scipy 1.7.3
seaborn 0.11.0
segmentation-models-pytorch 0.1.3
Send2Trash 1.5.0
sentencepiece 0.1.95
sentinelsat 0.14
seqeval 0.0.19
service-identity 18.1.0
setuptools 50.3.2
Shapely 1.7.1
simplegeneric 0.8.1
SimpleITK 2.0.2
simplejson 3.17.2
singledispatch 3.4.0.3
six 1.15.0
sklearn 0.0
slidingwindow 0.0.14
smart-open 5.1.0
smmap 4.0.0
sniffio 1.2.0
snowballstemmer 1.2.1
snuggs 1.4.7
sortedcollections 1.1.2
sortedcontainers 2.1.0
SoundFile 0.10.3.post1
soupsieve 1.8
spacy 2.3.7
Sphinx 1.8.5
sphinxcontrib-websupport 1.1.0
spyder 3.3.3
spyder-kernels 0.4.2
SQLAlchemy 1.4.13
srsly 1.0.5
statsmodels 0.13.1
streamlit 0.89.0
sympy 1.3
syntok 1.3.1
tables 3.5.2
tensorboard 2.4.0
tensorboard-data-server 0.6.0
tensorboard-plugin-wit 1.8.1
tensorboardX 2.5
test-tube 0.7.5
testpath 0.4.2
thinc 7.4.5
thop 0.0.31.post2005241907
threadpoolctl 2.1.0
tifffile 2021.4.8
tiffile 2018.10.18
timm 0.4.12
tokenizers 0.10.3
toml 0.10.2
tomlkit 0.7.2
toolz 0.9.0
torch 1.7.0+cu110
torch2trt 0.3.0
torchaudio 0.7.0
torchfile 0.1.0
torchgeometry 0.1.2
torchmetrics 0.5.1
torchnet 0.0.4
torchsummary 1.5.1
torchvision 0.8.1+cu110
tornado 6.1
tqdm 4.48.2
traceback2 1.4.0
traitlets 4.3.2
traits 6.2.0
traitsui 7.2.1
transformers 4.3.3
ttach 0.0.3
Twisted 19.2.0开始
接下来我把我改的地方详细点放出来,有的地方还有些中文注释,大家仔细对比着源码看看改了哪里吧,我测试了训练建筑的情况,个人感觉效果不太理想,下面是预测结果,放大了细节感觉不大行,不知道是不是因为这个网络不太适应这种遥感数据。(更新:初步排查了下,问题出在loss函数,建议使用下面这个dice函数,再搭配nn.BCELoss应该就更好了segmentation_models.pytorch/dice.py at master ・ qubvel/segmentation_models.pytorch ・ GitHubSegmentation models with pretrained backbones. PyTorch. - segmentation_models.pytorch/dice.py at master ・ qubvel/segmentation_models.pytorch https://github.com/qubvel/segmentation_models.pytorch/blob/master/segmentation_models_pytorch/losses/dice.py)
https://github.com/qubvel/segmentation_models.pytorch/blob/master/segmentation_models_pytorch/losses/dice.py)


?注意原始代码是多分类,我这里是改成二分类,下面是发生改动的所有代码(源码里的内容我这里其实没有删除,都是注释了以后加自己的)
1.改动部分
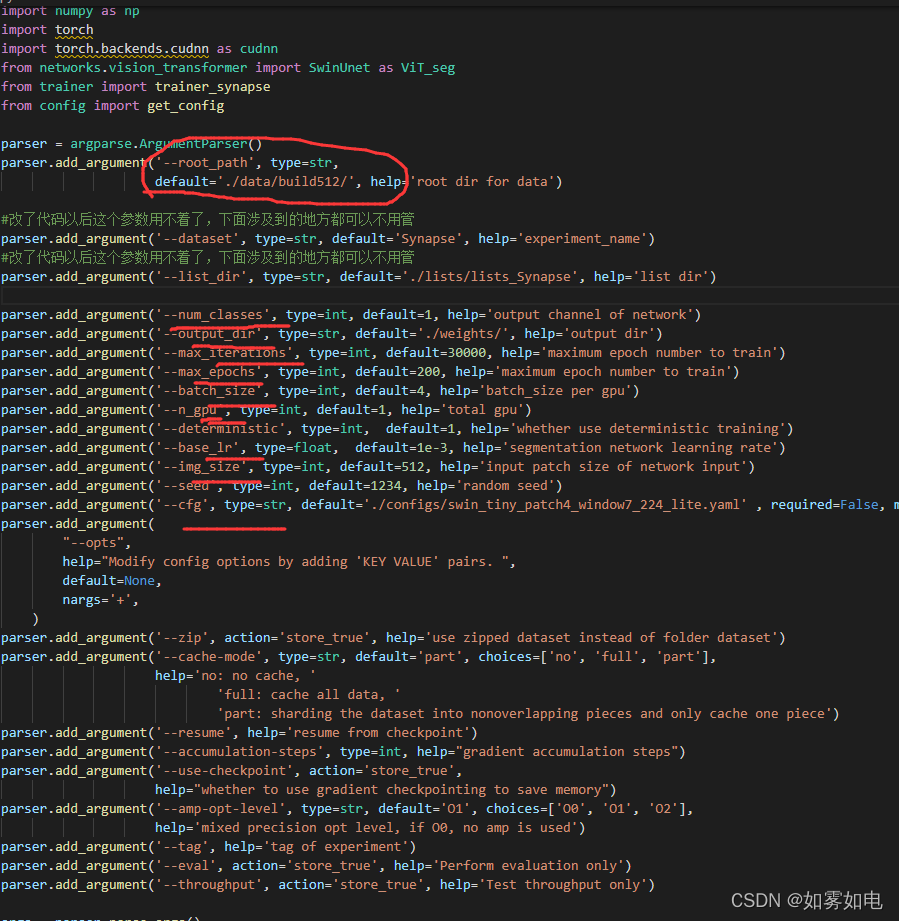
train.py,小改动,主要是参数部分,有的去掉了,需要注意的是图像的大小,最好是2的倍数,并且要能整除swin_tiny_patch4_window7_224_lite.yaml文件中的WINDOW_SIZE
# -*- coding: utf-8 -*-
import argparse
import logging
import os
import random
import numpy as np
import torch
import torch.backends.cudnn as cudnn
from networks.vision_transformer import SwinUnet as ViT_seg
from trainer import trainer_synapse
from config import get_config
parser = argparse.ArgumentParser()
parser.add_argument('--root_path', type=str,
default='./data/build512/', help='root dir for data')
#改了代码以后这个参数用不着了,下面涉及到的地方都可以不用管
parser.add_argument('--dataset', type=str, default='Synapse', help='experiment_name')
#改了代码以后这个参数用不着了,下面涉及到的地方都可以不用管
parser.add_argument('--list_dir', type=str, default='./lists/lists_Synapse', help='list dir')
parser.add_argument('--num_classes', type=int, default=1, help='output channel of network')
parser.add_argument('--output_dir', type=str, default='./weights/', help='output dir')
parser.add_argument('--max_iterations', type=int, default=30000, help='maximum epoch number to train')
parser.add_argument('--max_epochs', type=int, default=200, help='maximum epoch number to train')
parser.add_argument('--batch_size', type=int, default=4, help='batch_size per gpu')
parser.add_argument('--n_gpu', type=int, default=1, help='total gpu')
parser.add_argument('--deterministic', type=int, default=1, help='whether use deterministic training')
parser.add_argument('--base_lr', type=float, default=1e-3, help='segmentation network learning rate')
parser.add_argument('--img_size', type=int, default=512, help='input patch size of network input')
parser.add_argument('--seed', type=int, default=1234, help='random seed')
parser.add_argument('--cfg', type=str, default='./configs/swin_tiny_patch4_window7_224_lite.yaml' , required=False, metavar="FILE", help='path to config file', )
parser.add_argument(
"--opts",
help="Modify config options by adding 'KEY VALUE' pairs. ",
default=None,
nargs='+',
)
parser.add_argument('--zip', action='store_true', help='use zipped dataset instead of folder dataset')
parser.add_argument('--cache-mode', type=str, default='part', choices=['no', 'full', 'part'],
help='no: no cache, '
'full: cache all data, '
'part: sharding the dataset into nonoverlapping pieces and only cache one piece')
parser.add_argument('--resume', help='resume from checkpoint')
parser.add_argument('--accumulation-steps', type=int, help="gradient accumulation steps")
parser.add_argument('--use-checkpoint', action='store_true',
help="whether to use gradient checkpointing to save memory")
parser.add_argument('--amp-opt-level', type=str, default='O1', choices=['O0', 'O1', 'O2'],
help='mixed precision opt level, if O0, no amp is used')
parser.add_argument('--tag', help='tag of experiment')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--throughput', action='store_true', help='Test throughput only')
args = parser.parse_args()
if args.dataset == "Synapse":
# args.root_path = os.path.join(args.root_path, "train_npz")
pass
config = get_config(args)
if __name__ == "__main__":
if not args.deterministic:
cudnn.benchmark = True
cudnn.deterministic = False
else:
cudnn.benchmark = False
cudnn.deterministic = True
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
dataset_name = args.dataset
dataset_config = {
'Synapse': {
'root_path': args.root_path,
'list_dir': './lists/lists_Synapse',
'num_classes': args.num_classes,
},
}
if args.batch_size != 24 and args.batch_size % 6 == 0:
args.base_lr *= args.batch_size / 24
args.num_classes = dataset_config[dataset_name]['num_classes']
args.root_path = dataset_config[dataset_name]['root_path']
args.list_dir = dataset_config[dataset_name]['list_dir']
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
net = ViT_seg(config, img_size=args.img_size, num_classes=args.num_classes).cuda()
net.load_from(config)
trainer = {'Synapse': trainer_synapse,}
trainer[dataset_name](args, net, args.output_dir)dataset_synapse.py,大改动,主要是新增了加载自己数据的函数,里面有注释的
# -*- coding: utf-8 -*-
import os
import cv2
import random
import h5py
import numpy as np
import torch
from scipy import ndimage
from scipy.ndimage.interpolation import zoom
from torch.utils.data import Dataset
def random_rot_flip(image, label):
k = np.random.randint(0, 4)
image = np.rot90(image, k)
label = np.rot90(label, k)
axis = np.random.randint(0, 2)
image = np.flip(image, axis=axis).copy()
label = np.flip(label, axis=axis).copy()
return image, label
def random_rotate(image, label):
angle = np.random.randint(-20, 20)
image = ndimage.rotate(image, angle, order=0, reshape=False)
label = ndimage.rotate(label, angle, order=0, reshape=False)
return image, label
class RandomGenerator(object):
def __init__(self, output_size):
self.output_size = output_size
def __call__(self, sample):
image, label = sample['image'], sample['label']
if random.random() > 0.5:
image, label = random_rot_flip(image, label)
elif random.random() > 0.5:
image, label = random_rotate(image, label)
x, y = image.shape
if x != self.output_size[0] or y != self.output_size[1]:
image = zoom(image, (self.output_size[0] / x, self.output_size[1] / y), order=3) # why not 3?
label = zoom(label, (self.output_size[0] / x, self.output_size[1] / y), order=0)
image = torch.from_numpy(image.astype(np.float32)).unsqueeze(0)
label = torch.from_numpy(label.astype(np.float32))
sample = {'image': image, 'label': label.long()}
return sample
class Synapse_dataset(Dataset):
def __init__(self, base_dir, list_dir, split, transform=None):
self.transform = transform # using transform in torch!
self.split = split
self.sample_list = open(os.path.join(list_dir, self.split+'.txt')).readlines()
self.data_dir = base_dir
def __len__(self):
return len(self.sample_list)
def __getitem__(self, idx):
if self.split == "train":
slice_name = self.sample_list[idx].strip('\n')
data_path = os.path.join(self.data_dir, slice_name+'.npz')
data = np.load(data_path)
image, label = data['image'], data['label']
else:
vol_name = self.sample_list[idx].strip('\n')
filepath = self.data_dir + "/{}.npy.h5".format(vol_name)
data = h5py.File(filepath)
image, label = data['image'][:], data['label'][:]
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
sample['case_name'] = self.sample_list[idx].strip('\n')
return sample
# 这里开始是自己添加的用于加载自己数据的标准数据加载函数,可以参考用于别的复现!
#***********************数据增强部分************************************
def randomHueSaturationValue(image, hue_shift_limit=(-180, 180),
sat_shift_limit=(-255, 255),
val_shift_limit=(-255, 255), u=0.5):
if np.random.random() < u:
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(image)
hue_shift = np.random.randint(hue_shift_limit[0], hue_shift_limit[1]+1)
hue_shift = np.uint8(hue_shift)
h += hue_shift
sat_shift = np.random.uniform(sat_shift_limit[0], sat_shift_limit[1])
s = cv2.add(s, sat_shift)
val_shift = np.random.uniform(val_shift_limit[0], val_shift_limit[1])
v = cv2.add(v, val_shift)
image = cv2.merge((h, s, v))
#image = cv2.merge((s, v))
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
return image
def randomShiftScaleRotate(image, mask,
shift_limit=(-0.0, 0.0),
scale_limit=(-0.0, 0.0),
rotate_limit=(-0.0, 0.0),
aspect_limit=(-0.0, 0.0),
borderMode=cv2.BORDER_CONSTANT, u=0.5):
if np.random.random() < u:
height, width, channel = image.shape
angle = np.random.uniform(rotate_limit[0], rotate_limit[1])
scale = np.random.uniform(1 + scale_limit[0], 1 + scale_limit[1])
aspect = np.random.uniform(1 + aspect_limit[0], 1 + aspect_limit[1])
sx = scale * aspect / (aspect ** 0.5)
sy = scale / (aspect ** 0.5)
dx = round(np.random.uniform(shift_limit[0], shift_limit[1]) * width)
dy = round(np.random.uniform(shift_limit[0], shift_limit[1]) * height)
cc = np.math.cos(angle / 180 * np.math.pi) * sx
ss = np.math.sin(angle / 180 * np.math.pi) * sy
rotate_matrix = np.array([[cc, -ss], [ss, cc]])
box0 = np.array([[0, 0], [width, 0], [width, height], [0, height], ])
box1 = box0 - np.array([width / 2, height / 2])
box1 = np.dot(box1, rotate_matrix.T) + np.array([width / 2 + dx, height / 2 + dy])
box0 = box0.astype(np.float32)
box1 = box1.astype(np.float32)
mat = cv2.getPerspectiveTransform(box0, box1)
image = cv2.warpPerspective(image, mat, (width, height), flags=cv2.INTER_LINEAR, borderMode=borderMode,
borderValue=(
0, 0,
0,))
mask = cv2.warpPerspective(mask, mat, (width, height), flags=cv2.INTER_LINEAR, borderMode=borderMode,
borderValue=(
0, 0,
0,))
return image, mask
def randomHorizontalFlip(image, mask, u=0.5):
if np.random.random() < u:
image = cv2.flip(image, 1)
mask = cv2.flip(mask, 1)
return image, mask
def randomVerticleFlip(image, mask, u=0.5):
if np.random.random() < u:
image = cv2.flip(image, 0)
mask = cv2.flip(mask, 0)
return image, mask
def randomRotate90(image, mask, u=0.5):
if np.random.random() < u:
image=np.rot90(image)
mask=np.rot90(mask)
return image, mask
#**********************加载自己数据相关的函数****************************
#遍历数据文件夹,这里注意路径是拼接的
def read_own_data(root_path, mode = 'train'):
images = []
masks = []
image_root = os.path.join(root_path, mode + '/images')
gt_root = os.path.join(root_path, mode + '/labels')
for image_name in os.listdir(gt_root):
image_path = os.path.join(image_root, image_name)
label_path = os.path.join(gt_root, image_name)
images.append(image_path)
masks.append(label_path)
return images, masks
#训练数据读取
def own_data_loader(img_path, mask_path):
img = cv2.imread(img_path)
# img = cv2.resize(img, (512,512), interpolation = cv2.INTER_NEAREST)
mask = cv2.imread(mask_path, 0)
# mask = cv2.resize(mask, (512,512), interpolation = cv2.INTER_NEAREST)
img = randomHueSaturationValue(img,
hue_shift_limit=(-30, 30),
sat_shift_limit=(-5, 5),
val_shift_limit=(-15, 15))
img, mask = randomShiftScaleRotate(img, mask,
shift_limit=(-0.1, 0.1),
scale_limit=(-0.1, 0.1),
aspect_limit=(-0.1, 0.1),
rotate_limit=(-0, 0))
img, mask = randomHorizontalFlip(img, mask)
img, mask = randomVerticleFlip(img, mask)
img, mask = randomRotate90(img, mask)
mask = np.expand_dims(mask, axis=2)
img = np.array(img, np.float32) / 255.0 * 3.2 - 1.6
# img = np.array(img, np.float32) / 255.0
# mask = np.array(mask, np.float32)
mask = np.array(mask, np.float32) / 255.0
mask[mask >= 0.5] = 1
mask[mask < 0.5] = 0
img = np.array(img, np.float32).transpose(2, 0, 1)
mask = np.array(mask, np.float32).transpose(2, 0, 1)
return img, mask
#验证数据读取
def own_data_test_loader(img_path, mask_path):
img = cv2.imread(img_path)
# img = cv2.resize(img, (512,512), interpolation = cv2.INTER_NEAREST)
mask = cv2.imread(mask_path, 0)
# mask = cv2.resize(mask, (512,512), interpolation = cv2.INTER_NEAREST)
mask = np.expand_dims(mask, axis=2)
img = np.array(img, np.float32) / 255.0 * 3.2 - 1.6
# img = np.array(img, np.float32) / 255.0
# mask = np.array(mask, np.float32)
mask = np.array(mask, np.float32) / 255.0
mask[mask >= 0.5] = 1
mask[mask < 0.5] = 0
# mask[mask > 0] = 1
img = np.array(img, np.float32).transpose(2, 0, 1)
mask = np.array(mask, np.float32).transpose(2, 0, 1)
return img, mask
class ImageFolder(Dataset):
def __init__(self, root_path, mode='train'):
self.root = root_path
self.mode = mode
self.images, self.labels = read_own_data(self.root, self.mode)
def __getitem__(self, index):
if self.mode == 'test':
img, mask = own_data_test_loader(self.images[index], self.labels[index])
else:
img, mask = own_data_loader(self.images[index], self.labels[index])
img = torch.Tensor(img)
mask = torch.Tensor(mask)
return img, mask
def __len__(self):
# assert len(self.images) == len(self.labels), 'The number of images must be equal to labels'
return len(self.images)trainer.py,大改动,主要是调用自己的数据加载函数,以及损失函数,还加了些学习率下降策略
import argparse
import logging
import os
import random
import sys
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from tensorboardX import SummaryWriter
from torch.nn.modules.loss import CrossEntropyLoss
from torch.utils.data import DataLoader
from tqdm import tqdm
from utils import DiceLoss, BinaryDiceLoss
from torchvision import transforms
from utils import test_single_volume
from pytorch_toolbelt import losses as L
from datasets.dataset_synapse import ImageFolder
def trainer_synapse(args, model, snapshot_path):
# from datasets.dataset_synapse import Synapse_dataset, RandomGenerator
logging.basicConfig(filename=snapshot_path + "/log.txt", level=logging.INFO,
format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
logging.info(str(args))
base_lr = args.base_lr
num_classes = args.num_classes
batch_size = args.batch_size * args.n_gpu
max_iterations = args.max_iterations
# db_train = Synapse_dataset(base_dir=args.root_path, list_dir=args.list_dir, split="train",
# transform=transforms.Compose(
# [RandomGenerator(output_size=[args.img_size, args.img_size])]))
#换成自己的
db_train = ImageFolder(args.root_path, mode='train')
print("The length of train set is: {}".format(len(db_train)))
def worker_init_fn(worker_id):
random.seed(args.seed + worker_id)
# trainloader = DataLoader(db_train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True,
# worker_init_fn=worker_init_fn)
#换成自己的
trainloader = DataLoader(
db_train,
batch_size=batch_size,
shuffle=True,
num_workers=0,
pin_memory=True,
worker_init_fn=worker_init_fn)
if args.n_gpu > 1:
model = nn.DataParallel(model)
model.train()
# ce_loss = CrossEntropyLoss()
# bce_loss = nn.BCELoss()
# dice_loss = DiceLoss(num_classes)
bce_loss = nn.BCEWithLogitsLoss()
dice_loss = BinaryDiceLoss()
loss_fn = L.JointLoss(first=dice_loss, second=bce_loss, first_weight=0.5, second_weight=0.5).cuda()
# optimizer = optim.SGD(model.parameters(), lr=base_lr, momentum=0.9, weight_decay=0.0001)
optimizer = torch.optim.AdamW(model.parameters(),lr=base_lr, weight_decay=1e-3)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=2, # T_0就是初始restart的epoch数目
T_mult=2, # T_mult就是重启之后因子,即每个restart后,T_0 = T_0 * T_mult
eta_min=1e-6 # 最低学习率
)
writer = SummaryWriter(snapshot_path + '/log')
iter_num = 0
max_epoch = args.max_epochs
max_iterations = args.max_epochs * len(trainloader) # max_epoch = max_iterations // len(trainloader) + 1
logging.info("{} iterations per epoch. {} max iterations ".format(len(trainloader), max_iterations))
best_performance = 0.0
iterator = tqdm(range(max_epoch), ncols=70)
for epoch_num in iterator:
# for i_batch, sampled_batch in enumerate(trainloader):
for image_batch, label_batch in trainloader:
# image_batch, label_batch = sampled_batch['image'], sampled_batch['label']
image_batch, label_batch = image_batch.cuda(), label_batch.cuda()
outputs = model(image_batch)
# print(outputs) #torch.Size([6, 2, 224, 224])
# print(label_batch.shape) #torch.Size([6, 1, 224, 224])
#这里的ce_loss = CrossEntropyLoss()常用于多分类,换成BCELoss
# loss_ce = ce_loss(outputs, label_batch[:].long())
# loss_dice = dice_loss(outputs, label_batch, softmax=True)
# loss = 0.4 * loss_ce + 0.6 * loss_dice
outputs= torch.squeeze(outputs)
label_batch = torch.squeeze(label_batch)
# loss_ce = bce_loss(outputs, label_batch)
# loss_dice = dice_loss(outputs, label_batch)
# loss = 0.4 * loss_ce + 0.6 * loss_dice
loss = loss_fn(outputs, label_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_ = base_lr * (1.0 - iter_num / max_iterations) ** 0.9
for param_group in optimizer.param_groups:
param_group['lr'] = lr_
iter_num = iter_num + 1
writer.add_scalar('info/lr', lr_, iter_num)
writer.add_scalar('info/total_loss', loss, iter_num)
# writer.add_scalar('info/loss_ce', loss_ce, iter_num)
# logging.info('iteration %d : loss : %f, loss_ce: %f' % (iter_num, loss.item(), loss_ce.item()))
if iter_num % 20 == 0:
image = image_batch[1, 0:1, :, :]
image = (image - image.min()) / (image.max() - image.min())
writer.add_image('train/Image', image, iter_num)
# outputs = torch.argmax(torch.softmax(outputs, dim=1), dim=1, keepdim=True)
# writer.add_image('train/Prediction', outputs[1, ...] * 50, iter_num)
outputs = torch.sigmoid(outputs)
outputs[outputs>=0.5] = 1
outputs[outputs<0.5] = 0
temp = torch.unsqueeze(outputs[0],0)
writer.add_image('train/Prediction', temp * 50, iter_num)
labs = label_batch[1, ...].unsqueeze(0) * 50
writer.add_image('train/GroundTruth', labs, iter_num)
logging.info('iteration %d : loss : %f' % (iter_num, loss.item()))
save_interval = 10 # int(max_epoch/6)
if epoch_num > int(max_epoch / 2) and (epoch_num + 1) % save_interval == 0:
save_mode_path = os.path.join(snapshot_path, 'epoch_' + str(epoch_num) + '.pth')
torch.save(model.state_dict(), save_mode_path)
logging.info("save model to {}".format(save_mode_path))
if epoch_num >= max_epoch - 1:
save_mode_path = os.path.join(snapshot_path, 'epoch_' + str(epoch_num) + '.pth')
torch.save(model.state_dict(), save_mode_path)
logging.info("save model to {}".format(save_mode_path))
iterator.close()
break
scheduler.step()
writer.close()
return "Training Finished!"utils.py,小改动,主要是加了二分类的diceloss函数
import numpy as np
import torch
from medpy import metric
from scipy.ndimage import zoom
import torch.nn as nn
import SimpleITK as sitk
class BinaryDiceLoss(nn.Module):
"""Dice loss of binary class
Args:
smooth: A float number to smooth loss, and avoid NaN error, default: 1
p: Denominator value: \sum{x^p} + \sum{y^p}, default: 2
predict: A tensor of shape [N, *]
target: A tensor of shape same with predict
reduction: Reduction method to apply, return mean over batch if 'mean',
return sum if 'sum', return a tensor of shape [N,] if 'none'
Returns:
Loss tensor according to arg reduction
Raise:
Exception if unexpected reduction
"""
def __init__(self, smooth=1, p=2, reduction='mean'):
super(BinaryDiceLoss, self).__init__()
self.smooth = smooth
self.p = p
self.reduction = reduction
def forward(self, predict, target):
assert predict.shape[0] == target.shape[0], "predict & target batch size don't match"
predict = predict.contiguous().view(predict.shape[0], -1)
target = target.contiguous().view(target.shape[0], -1)
num = torch.sum(torch.mul(predict, target), dim=1) + self.smooth
den = torch.sum(predict.pow(self.p) + target.pow(self.p), dim=1) + self.smooth
loss = 1 - num / den
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
elif self.reduction == 'none':
return loss
else:
raise Exception('Unexpected reduction {}'.format(self.reduction))
class DiceLoss(nn.Module):
def __init__(self, n_classes):
super(DiceLoss, self).__init__()
self.n_classes = n_classes
def _one_hot_encoder(self, input_tensor):
tensor_list = []
for i in range(self.n_classes):
temp_prob = input_tensor == i # * torch.ones_like(input_tensor)
tensor_list.append(temp_prob.unsqueeze(1))
output_tensor = torch.cat(tensor_list, dim=1)
return output_tensor.float()
def _dice_loss(self, score, target):
target = target.float()
smooth = 1e-5
intersect = torch.sum(score * target)
y_sum = torch.sum(target * target)
z_sum = torch.sum(score * score)
loss = (2 * intersect + smooth) / (z_sum + y_sum + smooth)
loss = 1 - loss
return loss
def forward(self, inputs, target, weight=None, softmax=False):
if softmax:
inputs = torch.softmax(inputs, dim=1)
target = self._one_hot_encoder(target)
#这里多了一个维度,去掉
if not softmax:
inputs = torch.squeeze(inputs)
target = torch.squeeze(target)
if weight is None:
weight = [1] * self.n_classes
assert inputs.size() == target.size(), 'predict {} & target {} shape do not match'.format(inputs.size(), target.size())
class_wise_dice = []
loss = 0.0
for i in range(0, self.n_classes):
dice = self._dice_loss(inputs[:, i], target[:, i])
class_wise_dice.append(1.0 - dice.item())
loss += dice * weight[i]
return loss / self.n_classes
def calculate_metric_percase(pred, gt):
pred[pred > 0] = 1
gt[gt > 0] = 1
if pred.sum() > 0 and gt.sum()>0:
dice = metric.binary.dc(pred, gt)
hd95 = metric.binary.hd95(pred, gt)
return dice, hd95
elif pred.sum() > 0 and gt.sum()==0:
return 1, 0
else:
return 0, 0
def test_single_volume(image, label, net, classes, patch_size=[256, 256], test_save_path=None, case=None, z_spacing=1):
image, label = image.squeeze(0).cpu().detach().numpy(), label.squeeze(0).cpu().detach().numpy()
if len(image.shape) == 3:
prediction = np.zeros_like(label)
for ind in range(image.shape[0]):
slice = image[ind, :, :]
x, y = slice.shape[0], slice.shape[1]
if x != patch_size[0] or y != patch_size[1]:
slice = zoom(slice, (patch_size[0] / x, patch_size[1] / y), order=3) # previous using 0
input = torch.from_numpy(slice).unsqueeze(0).unsqueeze(0).float().cuda()
net.eval()
with torch.no_grad():
outputs = net(input)
out = torch.argmax(torch.softmax(outputs, dim=1), dim=1).squeeze(0)
out = out.cpu().detach().numpy()
if x != patch_size[0] or y != patch_size[1]:
pred = zoom(out, (x / patch_size[0], y / patch_size[1]), order=0)
else:
pred = out
prediction[ind] = pred
else:
input = torch.from_numpy(image).unsqueeze(
0).unsqueeze(0).float().cuda()
net.eval()
with torch.no_grad():
out = torch.argmax(torch.softmax(net(input), dim=1), dim=1).squeeze(0)
prediction = out.cpu().detach().numpy()
metric_list = []
for i in range(1, classes):
metric_list.append(calculate_metric_percase(prediction == i, label == i))
if test_save_path is not None:
img_itk = sitk.GetImageFromArray(image.astype(np.float32))
prd_itk = sitk.GetImageFromArray(prediction.astype(np.float32))
lab_itk = sitk.GetImageFromArray(label.astype(np.float32))
img_itk.SetSpacing((1, 1, z_spacing))
prd_itk.SetSpacing((1, 1, z_spacing))
lab_itk.SetSpacing((1, 1, z_spacing))
sitk.WriteImage(prd_itk, test_save_path + '/'+case + "_pred.nii.gz")
sitk.WriteImage(img_itk, test_save_path + '/'+ case + "_img.nii.gz")
sitk.WriteImage(lab_itk, test_save_path + '/'+ case + "_gt.nii.gz")
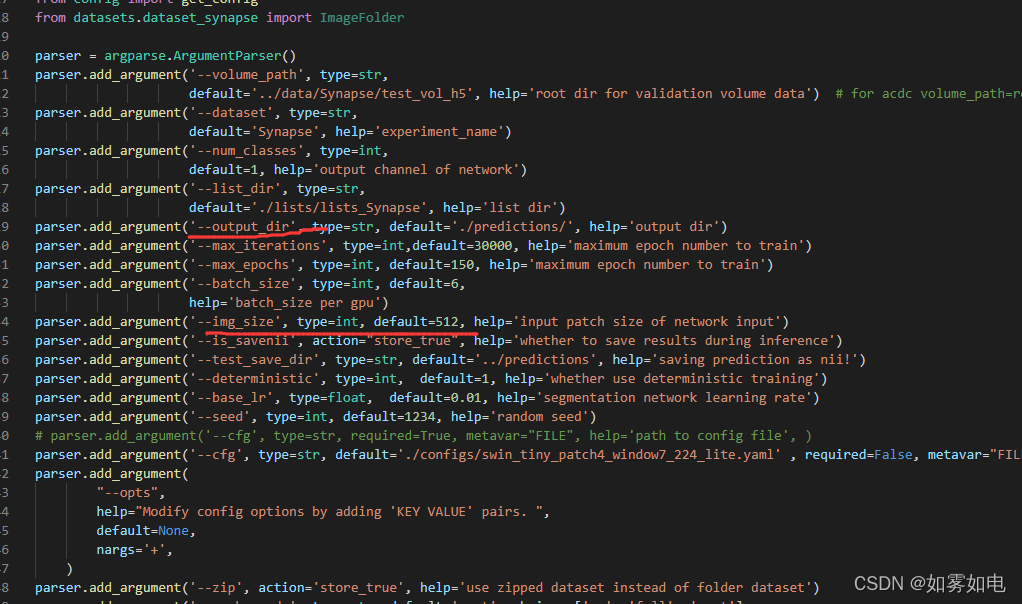
return metric_listtest.py,大改动,原始的测试是要加载标签做评价的,这里我直接注释了然后加了自己的数据加载直接做预测看效果,不评价
import argparse
import logging
import os
import random
import sys
import cv2
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
from torch.utils.data import DataLoader
from tqdm import tqdm
from datasets.dataset_synapse import Synapse_dataset
from utils import test_single_volume
from networks.vision_transformer import SwinUnet as ViT_seg
from trainer import trainer_synapse
from config import get_config
from datasets.dataset_synapse import ImageFolder
parser = argparse.ArgumentParser()
parser.add_argument('--volume_path', type=str,
default='../data/Synapse/test_vol_h5', help='root dir for validation volume data') # for acdc volume_path=root_dir
parser.add_argument('--dataset', type=str,
default='Synapse', help='experiment_name')
parser.add_argument('--num_classes', type=int,
default=1, help='output channel of network')
parser.add_argument('--list_dir', type=str,
default='./lists/lists_Synapse', help='list dir')
parser.add_argument('--output_dir', type=str, default='./predictions/', help='output dir')
parser.add_argument('--max_iterations', type=int,default=30000, help='maximum epoch number to train')
parser.add_argument('--max_epochs', type=int, default=150, help='maximum epoch number to train')
parser.add_argument('--batch_size', type=int, default=6,
help='batch_size per gpu')
parser.add_argument('--img_size', type=int, default=512, help='input patch size of network input')
parser.add_argument('--is_savenii', action="store_true", help='whether to save results during inference')
parser.add_argument('--test_save_dir', type=str, default='../predictions', help='saving prediction as nii!')
parser.add_argument('--deterministic', type=int, default=1, help='whether use deterministic training')
parser.add_argument('--base_lr', type=float, default=0.01, help='segmentation network learning rate')
parser.add_argument('--seed', type=int, default=1234, help='random seed')
# parser.add_argument('--cfg', type=str, required=True, metavar="FILE", help='path to config file', )
parser.add_argument('--cfg', type=str, default='./configs/swin_tiny_patch4_window7_224_lite.yaml' , required=False, metavar="FILE", help='path to config file', )
parser.add_argument(
"--opts",
help="Modify config options by adding 'KEY VALUE' pairs. ",
default=None,
nargs='+',
)
parser.add_argument('--zip', action='store_true', help='use zipped dataset instead of folder dataset')
parser.add_argument('--cache-mode', type=str, default='part', choices=['no', 'full', 'part'],
help='no: no cache, '
'full: cache all data, '
'part: sharding the dataset into nonoverlapping pieces and only cache one piece')
parser.add_argument('--resume', help='resume from checkpoint')
parser.add_argument('--accumulation-steps', type=int, help="gradient accumulation steps")
parser.add_argument('--use-checkpoint', action='store_true',
help="whether to use gradient checkpointing to save memory")
parser.add_argument('--amp-opt-level', type=str, default='O1', choices=['O0', 'O1', 'O2'],
help='mixed precision opt level, if O0, no amp is used')
parser.add_argument('--tag', help='tag of experiment')
parser.add_argument('--eval', action='store_true', help='Perform evaluation only')
parser.add_argument('--throughput', action='store_true', help='Test throughput only')
args = parser.parse_args()
if args.dataset == "Synapse":
args.volume_path = os.path.join(args.volume_path, "test_vol_h5")
config = get_config(args)
def inference(args, model, test_save_path=None):
db_test = args.Dataset(base_dir=args.volume_path, split="test_vol", list_dir=args.list_dir)
testloader = DataLoader(db_test, batch_size=1, shuffle=False, num_workers=1)
logging.info("{} test iterations per epoch".format(len(testloader)))
model.eval()
metric_list = 0.0
for i_batch, sampled_batch in tqdm(enumerate(testloader)):
h, w = sampled_batch["image"].size()[2:]
image, label, case_name = sampled_batch["image"], sampled_batch["label"], sampled_batch['case_name'][0]
metric_i = test_single_volume(image, label, model, classes=args.num_classes, patch_size=[args.img_size, args.img_size],
test_save_path=test_save_path, case=case_name, z_spacing=args.z_spacing)
metric_list += np.array(metric_i)
logging.info('idx %d case %s mean_dice %f mean_hd95 %f' % (i_batch, case_name, np.mean(metric_i, axis=0)[0], np.mean(metric_i, axis=0)[1]))
metric_list = metric_list / len(db_test)
for i in range(1, args.num_classes):
logging.info('Mean class %d mean_dice %f mean_hd95 %f' % (i, metric_list[i-1][0], metric_list[i-1][1]))
performance = np.mean(metric_list, axis=0)[0]
mean_hd95 = np.mean(metric_list, axis=0)[1]
logging.info('Testing performance in best val model: mean_dice : %f mean_hd95 : %f' % (performance, mean_hd95))
return "Testing Finished!"
# def inference(model, test_root, test_save_path):
# db_test = ImageFolder(test_root,mode='test')
# testloader = DataLoader(
# db_test,
# batch_size=1,
# shuffle=True,
# num_workers=0)
# for image_batch, label_batch in testloader:
# image_batch, label_batch = image_batch.cuda(), label_batch.cuda()
# outputs = model(image_batch)
# print(outputs.shape)
DEVICE = 'cuda:0' if torch.cuda.is_available() else 'cpu'
def inference_single(model, model_path, test_path, save_path):
model.to(DEVICE)
model.load_state_dict(torch.load(model_path))
model.eval()
im_names = os.listdir(test_path)
for name in im_names:
full_path = os.path.join(test_path, name)
img = cv2.imread(full_path)
# img = cv2.resize(img, (512,512), interpolation = cv2.INTER_NEAREST)
# image = np.array(img, np.float32) / 255.0
image = np.array(img, np.float32) / 255.0 * 3.2 - 1.6
image = np.array(image, np.float32).transpose(2, 0, 1)
image = np.expand_dims(image, axis=0)
image = torch.Tensor(image)
image = image.cuda()
output = model(image).cpu().data.numpy()
output[output < 0.5] = 0
output[output >= 0.5] = 1
output = np.squeeze(output)
save_full = os.path.join(save_path, name)
cv2.imwrite(save_full, output*255)
if __name__ == "__main__":
# if not args.deterministic:
# cudnn.benchmark = True
# cudnn.deterministic = False
# else:
# cudnn.benchmark = False
# cudnn.deterministic = True
# random.seed(args.seed)
# np.random.seed(args.seed)
# torch.manual_seed(args.seed)
# torch.cuda.manual_seed(args.seed)
# dataset_config = {
# 'Synapse': {
# 'Dataset': Synapse_dataset,
# 'volume_path': args.volume_path,
# 'list_dir': './lists/lists_Synapse',
# 'num_classes': 9,
# 'z_spacing': 1,
# },
# }
# dataset_name = args.dataset
# args.num_classes = dataset_config[dataset_name]['num_classes']
# args.volume_path = dataset_config[dataset_name]['volume_path']
# args.Dataset = dataset_config[dataset_name]['Dataset']
# args.list_dir = dataset_config[dataset_name]['list_dir']
# args.z_spacing = dataset_config[dataset_name]['z_spacing']
# args.is_pretrain = True
# net = ViT_seg(config, img_size=args.img_size, num_classes=args.num_classes).cuda()
# snapshot = os.path.join(args.output_dir, 'best_model.pth')
# if not os.path.exists(snapshot): snapshot = snapshot.replace('best_model', 'epoch_'+str(args.max_epochs-1))
# msg = net.load_state_dict(torch.load(snapshot))
# print("self trained swin unet",msg)
# snapshot_name = snapshot.split('/')[-1]
# log_folder = './test_log/test_log_'
# os.makedirs(log_folder, exist_ok=True)
# logging.basicConfig(filename=log_folder + '/'+snapshot_name+".txt", level=logging.INFO, format='[%(asctime)s.%(msecs)03d] %(message)s', datefmt='%H:%M:%S')
# logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
# logging.info(str(args))
# logging.info(snapshot_name)
# if args.is_savenii:
# args.test_save_dir = os.path.join(args.output_dir, "predictions")
# test_save_path = args.test_save_dir
# os.makedirs(test_save_path, exist_ok=True)
# else:
# test_save_path = None
# inference(args, net, test_save_path)
args = parser.parse_args()
config = get_config(args)
net = ViT_seg(config, img_size=args.img_size, num_classes=args.num_classes).cuda()
test_root = 'D:/csdn/Swin-Unet/data/build512/val/images/'
test_save_path = './predictions/'
model_path = './weights/epoch_179.pth'
inference_single(net, model_path, test_root, test_save_path)2.训练
做好以上改动后,把下面标号的地方改成自己的路径和想设置的参数就可以直接在命令行
python train.py 开始训练了(注意img_size改了以后记得在config.py里对应的也改,不然报错)
?3.预测
同上?
上面已经是改动代码加注释了,应该可以跟着改肯定可以跑通的,下面的付费,建议不要管,实在不行的可以考虑