【强化学习】??手把手带你走进强化学习 2?? OPP 算法实现月球登陆器 (PyTorch 版)_我是小白呀的博客-CSDN博客
PPO算法原理简介
接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;与之对应的就是off-policy的策略,即想要训练的agent和与环境进行交互的agent不是同一个agent,简单来说,就是拿别人的经验来训练自己。举个下棋的例子,如果你是通过自己下棋来不断提升自己的棋艺,那么就是on-policy的,如果是通过看别人下棋来提升自己,那么就是off-policy的:

那么为了提升我们的训练速度,让采样到的数据可以重复使用,我们可以将on-policy的方式转换为off-policy的方式。即我们的训练数据通过另一个Actor(对应的网络参数为θ'得到。这要怎么做呢?通过下面的思路:
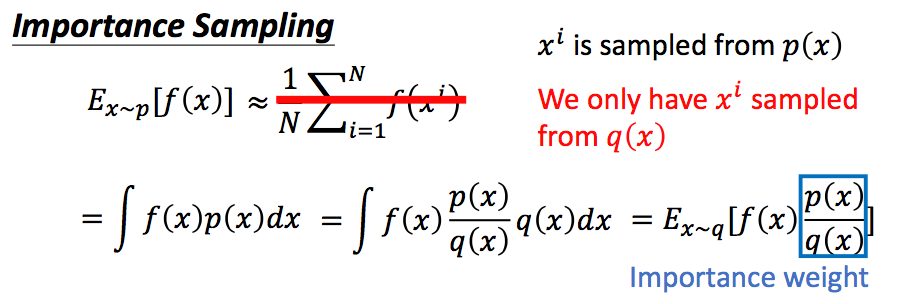
通过这种方式,我们的p(x)和q(x)的分布不能差别太大,否则需要进行非常多次的采样,才能得到近似的结果:
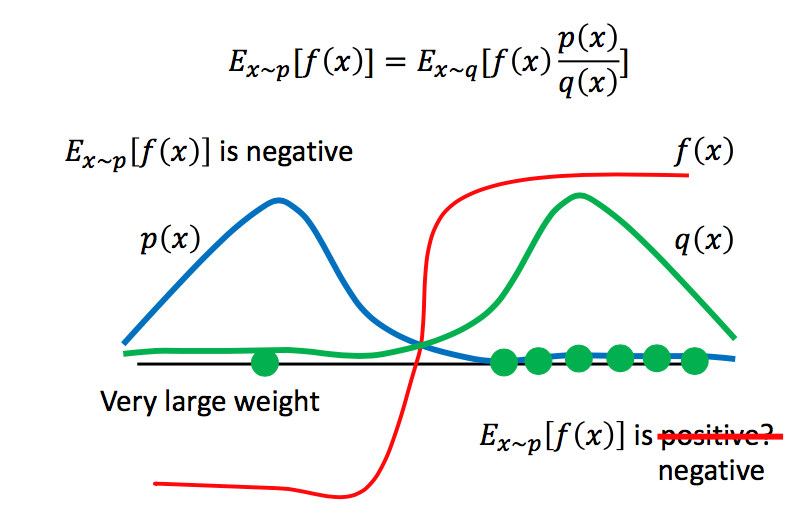
如上图所示,很显然,在x服从p(x)分布时,f(x)的期望为负,此时我们从q(x)中来采样少数的x,那么我们采样到的x很有可能都分布在右半部分,此时f(x)大于0,我们很容易得到f(x)的期望为正的结论,这就会出现问题,因此需要进行大量的采样。
那么此时我们想要期望奖励最大化,则变为:

则梯度变为:

最后一项因为我们假设两个分布不能差太远,所以认为他们是相等的,为了求解方便,我们直接划掉。此时似然函数变为:
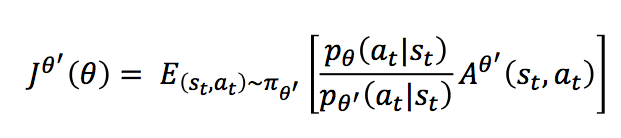
由梯度变为似然函数,使用的还是下面式子,大家可以自己手动算一下:
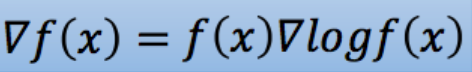
到这里,我们马上就要得到我们的PPO算法了,再坚持一下!
我们前面介绍了,我们希望θ和θ'不能差太远,这并不是说参数的值不能差太多,而是说,输入同样的state,网络得到的动作的概率分布不能差太远。得到动作的概率分布的相似程度,我们可以用KL散度来计算,将其加入PPO模型的似然函数中,变为:
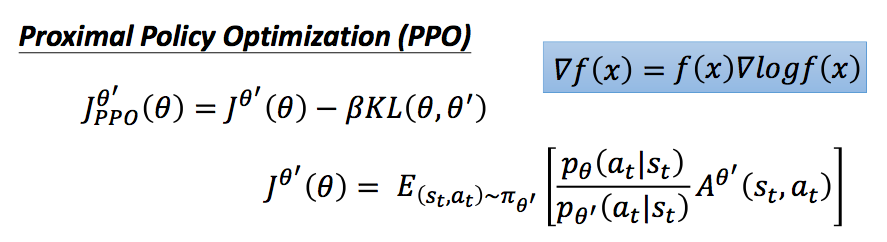
在实际中,我们会动态改变对θ和θ'分布差异的惩罚,如果KL散度值太大,我们增加这一部分惩罚,如果小到一定值,我们就减小这一部分的惩罚,基于此,我们得到了PPO算法的过程:

PPO算法还有另一种实现方式,不将KL散度直接放入似然函数中,而是进行一定程度的裁剪:
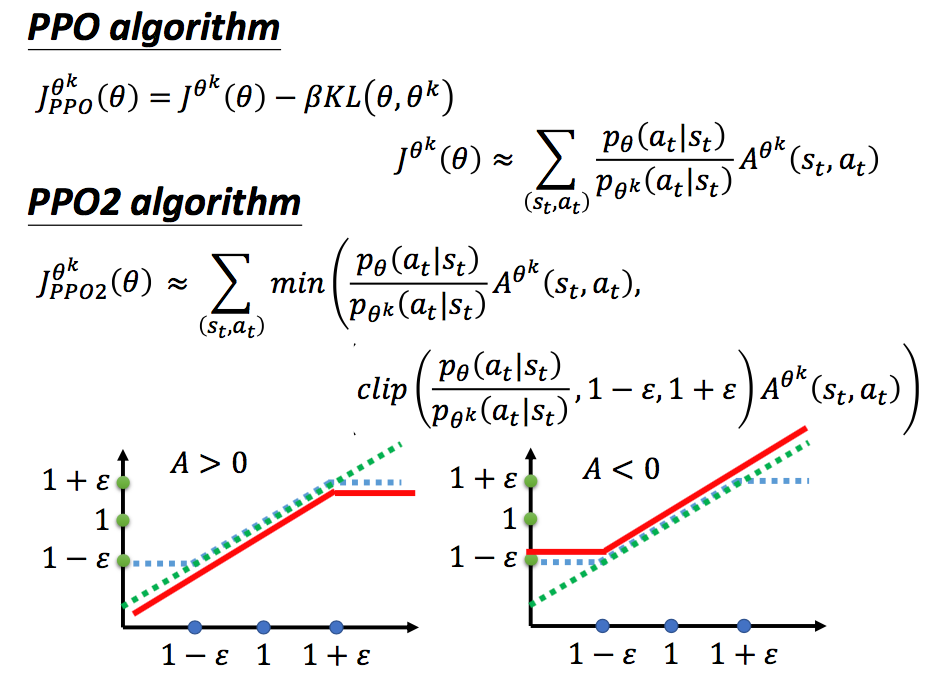
上图中,绿色的线代表min中的第一项,即不做任何处理,蓝色的线为第二项,如果两个分布差距太大,则进行一定程度的裁剪。最后对这两项再取min,防止了θ更新太快。
Proximal Policy Optimization(PPO)算法原理及实现! - 简书
?