ǰ��
ʵ��Ŀ�ĺ�Ҫ��:
- ʹ�ø��ʷֲ����з���
- ѧϰ���ر�Ҷ˹�����������ı�����
- ���ʵս֮���������ʼ�
�Ƽ�ʹ��Jupyter Notebook ,�����������,��Ȼ��pycharmҲ���ԡ�
�����Ĵ�������ĺ����
һ����Ҷ˹�����۸���
��Ҷ˹�������������˼��:ѡ��߸��ʶ�Ӧ�����
������p1(x,y)��ʾ���ݵ�(x,y)�������1�ĸ���,��p2(x,y)��ʾ���ݵ�(x,y)�������2�ĸ���,��p1(x,y) > p2(x,y),��ô���Ϊ1��
��ô������Ҫ���˽�һ�¸������е����������������:P(A|B)��ʾ�¼�B�Ѿ�������ǰ����,�¼�A�����ĸ���,P(B|A)�����¼�B�������¼�A���������ʡ��������ʽΪ:P(A|B) = P(AB)/P(B) P(B|A) = P(A|B)*P(B)/P(A)
��Ӧ:P(���|����) = P(����|���)*P(���)/P(����)
�ٸ��������������:
������һ��������,���һ����Ů����,��������Ů�����,�������ĸ��ص�ֱ��Dz�˧,�Ը�,���߰�,���Ͻ�,�����ж�һ��Ů���Ǽ��Dz���?
���µı�������ǰ��֪��һЩ���� (����ʵ��һ������Ϲ���( ��, �� )��)
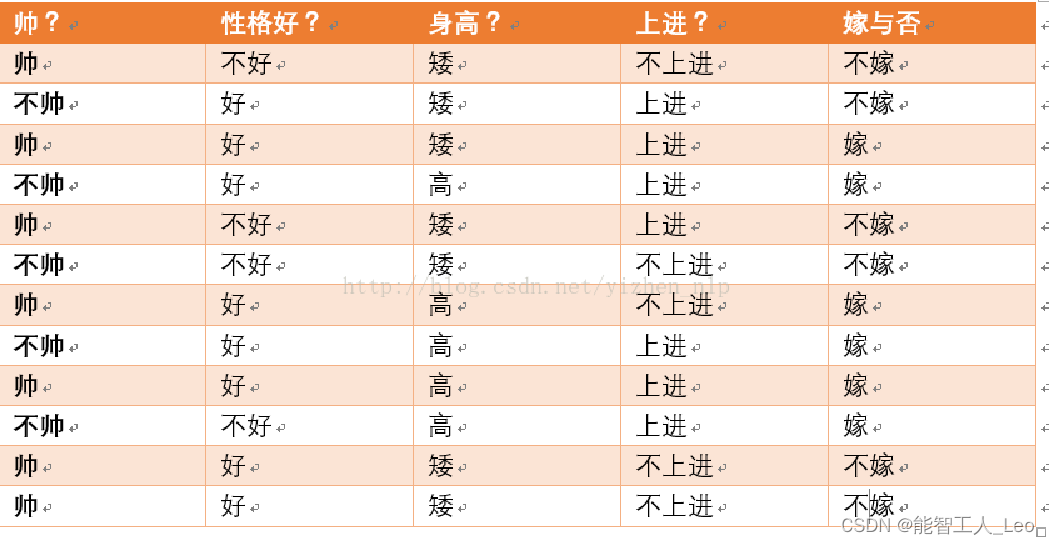
����һ�����͵ķ�������,תΪ ��ѧ���� ���DZȽ���������:
p(��|(��˧���Ըá����߰������Ͻ�))
p(����|(��˧���Ըá����߰������Ͻ�))
��������֪�����µĸ���,˭�ĸ��ʴ�,���ܸ������߲��Ĵ�!
Ȼ�����������չ����:

����������������:
p(��) = 6/12(��������) = 1/2
p(��˧|��) = 3/6 = 1/2
p(�Ը�|��)= 1/6
p(��|��) = 1/6
p(���Ͻ�|��) = 1/6
p(��˧) = 4/12 = 1/3
p(�Ը�) = 4/12 = 1/3
p(���߰�) = 7/12
p(���Ͻ�) = 4/12 = 1/3
�õ��ľ��� p(��|(��˧���Ըá����߰������Ͻ�)) ,������˧���Ըá����߰������Ͻ� ��������,�õ����Ϊ �� �ĸ���(����һ��,���ֻ�� 5%���ҡ�)
����ʵս֮�ĵ�����
1.�ȵ��� numpy ������ݼ��Լ�������������ǩ����
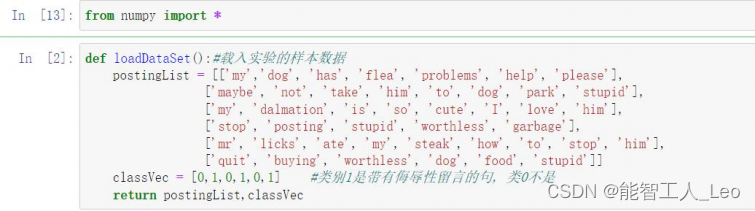
2.��Ҫ�����ݼ��е����е�������һ���ʻ�� �� set ��������,���ü���Ԫ�ص�Ψһ��,����ôʻ��
 3. ��������,����Ϊ�ʻ�����µ�����;������������ʻ�,�� ������ʳ��ֺʹʻ��ƥ��,��ô���ص�������Ӧ������ֵΪ 1
3. ��������,����Ϊ�ʻ�����µ�����;������������ʻ�,�� ������ʳ��ֺʹʻ��ƥ��,��ô���ص�������Ӧ������ֵΪ 1

���ú����鿴���ֵ


- ������Ҫ����
trainMatrix Ϊѵ�����ľ����ڴʻ���г���λ�������б�,traincategory Ϊѵ������Ӧ�ı� ǩ0 �� 1;
�����������,��Ϊ�����Ծ��ӵ�����ǩΪ 1,ֱ���� sum ��ǩ������ 1 �ٳ�����������,�� �� pAbusive;
֮��ѭ���������о���,���ڱ�ǩΪ 1 ��,���� p1Num �� 1,ͬʱ p1Denom Ҳ���� 1;���ڱ�ǩΪ 0 ��,ֱ�Ӽ��Ǿ��ӵ�λ������,��Ӧ�Ĵʼ� 1;
��ص���ȡ���������� p1Vect �� p0Vect,�����������ĸ��ʷֲ���

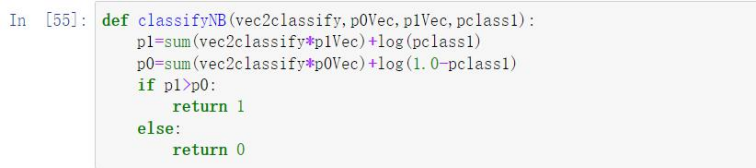
- ���ຯ�� classifyNB,�����Ѿ�֪��������� 1 ����� 0 �ĸ��ʷֲ�;p1 ��ʾ���� ��������� 1 �ĸ���,�� p0 ��ʾ���ݵ�������� 0 �ĸ���,�� p1> p2,��ô���Ϊ 1
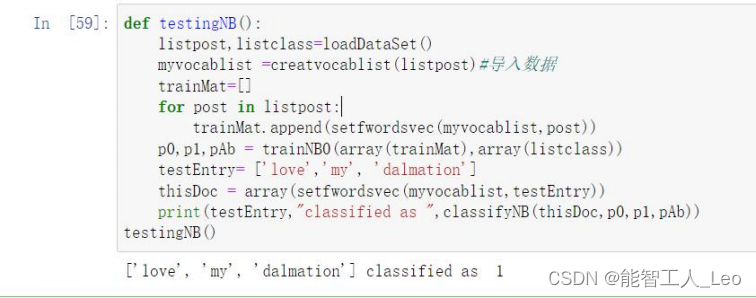
- ���Ժ���,����һ���µ�����[��love��,��my��, ��dalmation��],Ӧ��֮ǰ ��ѵ�����ͷ�����,��ɷ�������
�������������ʼ�
1.���Ƚ����ı���Ϣ¼��,�� txt �ļ������ݱ��һ�������б�
��������й����г��ֵĴ��� ��gbk�� codec can��t decode byte 0xae in position 199: illegal multibyte sequence Ϊ�ı��в����ַ���ʶ��,�����ų��� 23 ���ļ�����,����ʶ����ַ�ɾȥ

- ������
���Ƕ�������,������ 26 ���ʼ��ͱ�Ƕ���

���,��������ķ�ʽ�ָ���Լ�;��Ȼ�� trainNB ������Ϊѵ������, ѭ������,�õ����ʷֲ� p0V,p1V,pSpan;���,�÷�����ʶ��,��������ʡ�
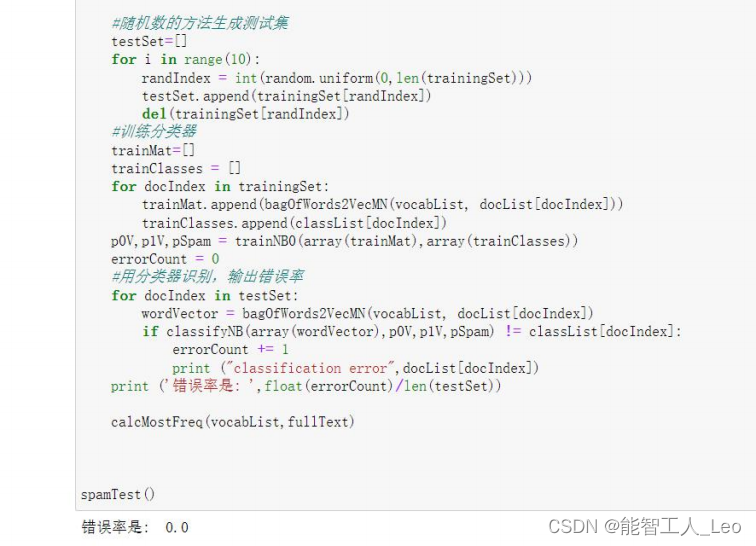
���δ�����Ϊ 0,֮�δ�����Ϊ 0.1
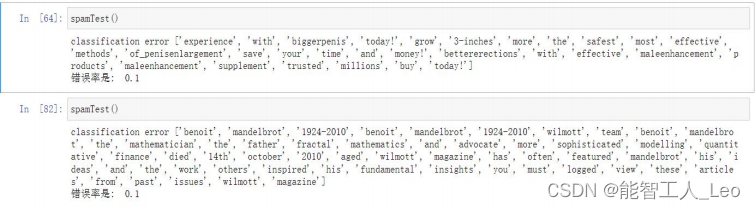
����ʵ���������
-
������Ϊ�λ���Ϻ���,ԭ���Dz��Լ�Ϊ������ɵķ�ʽ
-
��Ҷ˹�����ʼ����������ñ�Ҷ˹��������Ҷ˹�����������ʼ�����������ʹ���˼���:
��һ��,������Ϣ�������ĸ���,֪��һ�������ĵ��ʳ����ڴ���Ϣ��;
�ڶ���,������Ϣ�������ĸ���,���ǵ����е����Ĵ�(�����ǵ�һ������Ӽ�)
�ܴ���
1.�ĵ�����
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1]
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print ("the word: %s is not in my Vocabulary!" % word)
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num = ones(numWords)
p0Denom = 2.0; p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def calcMostFreq(vocabList,fullText):
import operator
freqDict = {}
for token in vocabList:
freqDict[token]=fullText.count(token)
sortedFreq = sorted(freqDict.items(), key=operator.itemgetter(1), reverse=True)
return sortedFreq[:30]
testingNB()
2.���������ʼ�
�ļ�·���� D:/email ��,�����Լ������
def textParse(bigString): #����Ԥ����
import re
listOfTokens = re.split(r' |\n|\t|,|\.', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
def spamTest(): # ��������ʼ�
docList=[]
classList = []
fullText =[]
for i in range(1,26):
# ��ȡ���е�26ƪ�����ʼ�,�����б�
wordList = textParse(open('D:/email/spam/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1) #���Ϊ1
# ��ȡ���е�26ƪ�������ʼ�,�����б�
wordList = textParse(open('D:/email/ham/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)#���Ϊ0
#�����ݱ������
vocabList = createVocabList(docList)
trainingSet = list(range(50))
#������ķ������ɲ��Լ�
testSet=[]
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
#ѵ��������
trainMat=[]
trainClasses = []
for docIndex in trainingSet:
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
#�÷�����ʶ��,���������
for docIndex in testSet:
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print ("classification error",docList[docIndex])
print ('��������: ',float(errorCount)/len(testSet))
calcMostFreq(vocabList,fullText)
spamTest()