��߶ȼ��
�����²�������ն�����
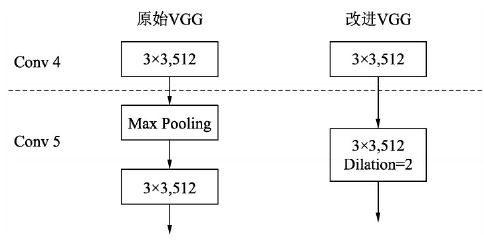
- ����С����������,����������²�����Ҳ������Ϊ��������ʽ,ͨ����������ֱ��ȥ�� Pooling ��,��������Ȼ��С���²�����,ȴ�ᵼ�º�����ĸ���Ұ��ԭ��ģ�Ͳ�ͬ,���ʹ��Ԥѵ��ģ�ͽ�����,��ģ�Ͳ��ܺܺõ�����,��˿���ʹ���ն�����,����֤���ı�����ֱ��ʵ�ǰ������������ĸ���Ұ����Ҫע�����,���ÿն�����Ҳ���ܱ�֤�ĺ�����ǰ�ĸ���Ұ��ȫ��ͬ,���ܹ�����ȵ�ʹ����Ұ�ڿɽ��ܵ������
Anchor ���
- Anchor ͨ���Ƕ����ͬ��С����ߵı߿�,�����С�������һ�鳬����,��Ҫ�����ֶ��������ڲ�ͬ�����ݼ���������,��������ij߶ȡ���С���в��,�������˼������ݼ���,���˱�ǩ���߱�ͨ��Ϊ 0.41,��ͨ������ı�ǩ����������,��ʱ����Ҫ��Ӧ�ص��� Anchor �Ĵ�С����ߡ�����,Anchor ����С����С����ļ��Ҳ��Ϊ��Ҫ,��� Anchor ����,��ʹС����ȫ���� Anchor ��,Ҳ����Ϊ���������С���� IoU ��,�Ӷ����©�졣���,��� Anchor ��ƵIJ�����,�����ݼ��е�����ֲ����ڲ��,����ģ�����������ϴ������,Ӱ��ģ�͵ľ���,������������
- ͨ������,���Դ����������Ƕȿ���������һ��õ� Anchor:
- (1) ͳ��ʵ��: ����ѵ�����ı�ǩ����Ƶ� Anchor ����ƥ������,�����ָ��������ѵ����ǩ���ٻ���,�Լ���������ƽ�� IoU ֵ����Ȼ,Ҳ��������ÿ����ǩ��������������ǩ����� IoU ����Ϊ����ָ�ꡣΪ�˷����ƥ��,�ڴ˲����� Anchor ���ǩ��λ��ƫ��,���ǰ����ߵ����ĵ����һ��,���������������Ϣ����ƥ�䡣����ͳ��ʵ��ʵ����ͨ���ֹ���Ƶķ�ʽ,Ѱ�����ǩ���߷ֲ���Ϊһ�µ�һ�� Anchor
- (2) �߿����: ��ѵ�����ı�ǩ��ֱ�Ӿ����һ����ʵ� Anchor (YOLO v2 ����ʹ���� K-means �㷨���б߿����)������һ�� Anchor �����������ͼ��ÿһ��λ����,���û��λ������,����ֻ��ע��ǩ����������,��û��Ҫ����������ֵ�λ��
��߶�ѵ�� (Multi Scale Training,MST)
- ���ڶ�߶�,�������ȿ������뵽����ͼ�����е�ͼ�������,��������ͼƬ���ŵ�����߶���,ÿһ���߶ȵ����ؼ�������ͼ,�����к����ļ�⡣���ַ�ʽ��Ȼһ���̶��Ͽ���������⾫��,�����ڶ���߶���ȫ����,��ʱ��
- ��ǰ����߶�ѵ��ͨ����ָ���ü��ֲ�ͬ��ͼƬ����߶�,ѵ��ʱ�Ӷ���߶������ѡȡһ�ֳ߶�,������ͼƬ���ŵ��ó߶Ȳ�����������,��һ�ּ�����Ч��������߶�������ķ�������Ȼһ�ε���ʱ���ǵ�һ�߶ȵ�,��ÿ�ζ�������ͬ,�����������³����,�ֲ��������ӹ���ļ���������������ʱ,Ϊ�˵õ���Ϊ���ļ����,Ҳ���Խ�����ͼƬ�ij߶ȷŴ�,����Ŵ� 4 ��,�������Ա�������С����
- ��߶�ѵ����һ��ʮ����Ч�� trick,�Ŵ���С����ij߶�,ͬʱ�����˶�߶�����Ķ�����,�ڶ������㷨�ж�����ֱ��Ƕ��,�ڲ�Ҫ���ٶȵij��ϻ��߸��������⾺������Ϊ����
�����ں�

�߶ȹ�һ��: SNIP (Scale Normalization for Image Pyramids)
Image Classification at Multiple Scales
- SOTA ��Ŀ���ⷽ��һ������ 800 �� 1200 800\times 1200 800��1200 �ķֱ�����ѵ��,������ȴ����ͼ��������Ͻ��е�,���м��С����ʱʹ�õķֱ��ʴﵽ�� 1400 �� 2000 1400\times2000 1400��2000,���������ѵ����������ʽ������ domain shift. ��������������� domain shift ������Ӱ��

- Naive Multi-Scale Inference (CNN-B;�߷ֱ���ѵ��,�ͷֱ��ʲ���): ���Ƚ� ImageNet �е�ͼ���²���Ϊ
48
��
48
48\times48
48��48,
64
��
64
64\times64
64��64,
80
��
80
80\times80
80��80,
96
��
96
96\times96
96��96 ��
128
��
128
128\times128
128��128 �ĵͷֱ���ͼ��,Ȼ�������ϲ���Ϊ
224
��
224
224\times224
224��224 ������ CNN-B,���� CNN-B ����
224
��
224
224\times224
224��224 �ķֱ�����ѵ���ġ�ʵ��������,ѵ��������ʱ��ͼ��ֱ��ʲ��Խ��,ģ������Խ��
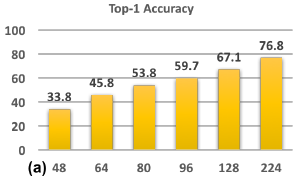
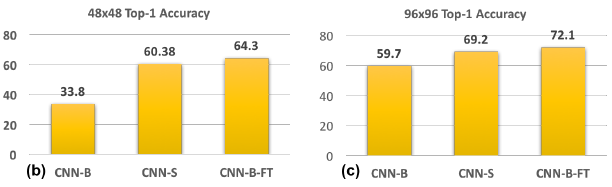
- Resolution Specific Classifiers (CNN-S;�ͷֱ���ѵ��,�ͷֱ��ʲ���): ���������۲�,һ�ּ����ģ��С���������ܵķ���������ģ���ڵͷֱ���ͼ����ѵ��,�����Ҫ������ܹ���ʹ�ø�С�� stride��ʵ�����, 48 �� 48 48\times48 48��48 �� 96 �� 96 96\times96 96��96 �ֱ����·ֱ�ѵ�������� CNN-S ���ܶ������� CNN-B,������ڵͷֱ���ͼ��ļ��,ר��Ԥѵ��һ����Եͷֱ���ͼ��� backbone ������ܻ�����ģ������
- Fine-tuning High-Resolution Classifiers (CNN-B-FT;�߷ֱ���ѵ��,�ͷֱ�����,�ͷֱ��ʲ���): ��һ�ּ�����С���������ܵķ����������ϲ�����ĵͷֱ���ͼ���϶� CNN-B ����,ʵ��������ַ������������,������Բ��ı�ģ�ͼܹ�,���Dz�ȡ�����ڸ߷ֱ�����ѵ��,�ͷֱ��������ķ�ʽ������ģ��С����������
Data Variation or Correct Scale?
����ʵ������� Deformable-RFCN (D-RFCN),��˿������벻ͬ�ߴ��ͼƬ����Ŀ���⡣Deformable-RFCN ���� R-FCN,���� conv5 �������˿ɱ��ξ�������̬�����������Ұ����Ӧ����IJ�ͬ��С,ͬʱ��λ������ RoI �ػ��滻Ϊ�˿ɱ���λ������ RoI �ػ�
- ����ĶԱ����鶼�� 1400 �� 2000 1400\times2000 1400��2000 �ֱ��ʵ�ͼ���ϲ��Լ��С���������
- Training at different resolutions (Fig 5.1): �ֱ��� 800 �� 1400 800\times1400 800��1400 �� 1400 �� 2000 1400\times2000 1400��2000 �ֱ�����ʹ������ѵ����������ѵ�� (i.e. 80 0 a l l 800_{all} 800all?, 140 0 a l l 1400_{all} 1400all?)����ǰ��Ľ���һ��, 140 0 a l l 1400_{all} 1400all? �����ܳ����� 80 0 a l l 800_{all} 800all?,�����������������Դ�,������Ϊ�ڸ��߷ֱ�����ѵ����Ȼ������С����������,��Ҳ�ô�����ߴ��������Լ��,ģ����Ҫͬʱ���߶Ȳ��ܴ������,������ģ����,����������ģ������
- Scale specific detectors (Fig 5.2): ���������۲�,���߽�һ���� 1400 �� 2000 1400\times2000 1400��2000 �ֱ����½�ʹ��С�� 80 ���ص��ѵ����������ѵ�� (i.e. 140 0 < 80 p x 1400_{<80px} 1400<80px?),��ȴ����ģ�����ܷ��������ˡ��Դ�,������Ϊ�������������������������Ķ�����,����ģ�����ܲ������������
- Multi-Scale Training (MST) (Fig 5.3): ��߶�ѵ��������������ŵ���ͬ�ֱ����½���ѵ��,�Ᵽ֤��ģ�����ڶ���ֱ����¹۲����塣Ȼ��,MST ������ȴֻ��
80
0
a
l
l
800_{all}
800all? �ӽ�,�Դ�,������ΪӦ��ʹ���ʵ����ŵ�������������ѵ��,ͬʱҲҪ��֤�㹻������������ (Fig 5.4)


Object Detection on an Image Pyramid
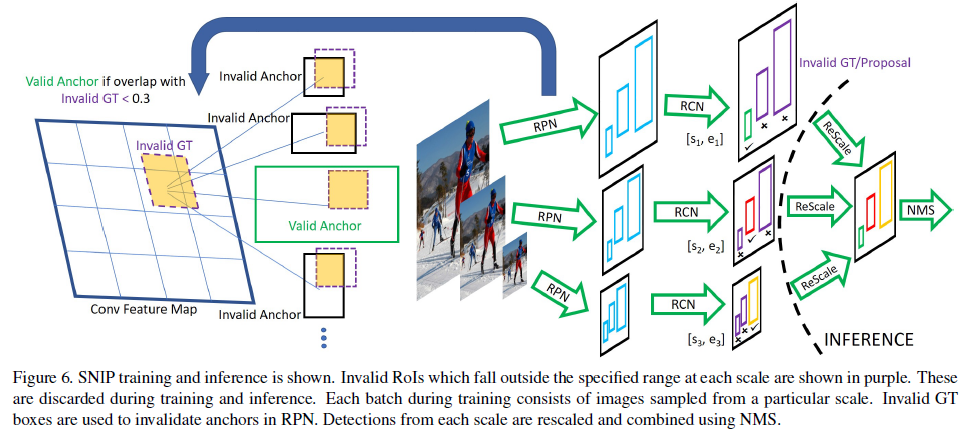
- Scale Normalization for Image Pyramids: SNIP �� MST �ĸĽ��汾,��ͼ�����ŵ���ͬ�ֱ���ʱ,ֻ����Ԥѵ�����ݼ��ֱ��ʳߴ� (typically 224 �� 224 224\times224 224��224) �ӽ�������ű�����ѵ���������ȱ�֤�����ݵĶ�����,�ֲ�����Ϊ����/��С�������Լ��������ģ�������½�
- �������,��ѵ��������ʱ,�������� GT ��� proposals �����ǩ,Ȼ������Щ�ߴ������С�� proposals �� GT ��ͬ����,��ѵ�� RPN ʱ,Ҳ���������� GT �������ê������ǩ,Ȼ������С GT ����Ϊ��Ч GT ��,��������Ч GT �� IoU ���� 0.3 ��ê��;����ʱ,���ڲ�ͬ�ֱ����·ֱ����Ԥ���,Ȼ����������С��Ԥ��� (ע��,�Ƕ���Ԥ������ proposals),���ʹ�� soft NMS ������յ�Ԥ���
�����: TridentNet
- TridentNet ���������ȷ����˲�ͬ��С�ĸ���Ұ���ڼ������Ӱ�졣ʵ��ֱ������ ResNet-50 �� ResNet-101 ��Ϊ Backbone,�����ı����һ���ε�ÿ��
3
��
3
3��3
3��3 �����Ŀն���,��Ҳ�����ڿն�������������ͬ�Ľṹ�����������²�����ʱ,�ı�����ĸ���Ұ��ʵ�������±���ʾ:
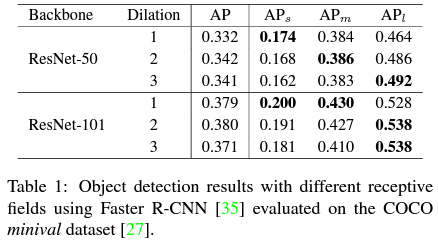 ����,
A
P
s
AP_s
APs?��
A
P
m
AP_m
APm? ��
A
P
l
AP_l
APl? �ֱ����С���С��� 3 ����ͬ�߶ȵ������Ӽ����ӽ�����Ժ�ֱ�۵ؿ���,��ͬ�߶ȵļ�����������Ұ�������,����ĸ���Ұ���ڴ�������Ѻ�,С�ĸ���Ұ����С������Ѻ������ڴ˽���,��һ������,�ܷ����� 3 �ֲ�ͬ�ļ�����ܽ��,ʵ�����ƻ�����?
����,
A
P
s
AP_s
APs?��
A
P
m
AP_m
APm? ��
A
P
l
AP_l
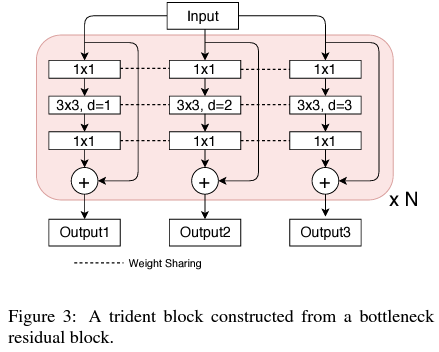
APl? �ֱ����С���С��� 3 ����ͬ�߶ȵ������Ӽ����ӽ�����Ժ�ֱ�۵ؿ���,��ͬ�߶ȵļ�����������Ұ�������,����ĸ���Ұ���ڴ�������Ѻ�,С�ĸ���Ұ����С������Ѻ������ڴ˽���,��һ������,�ܷ����� 3 �ֲ�ͬ�ļ�����ܽ��,ʵ�����ƻ�����? - ���ڴ�,�������� 3 �ֲ�ͬ�ĸ���Ұ���粢�л�,���������ͼ��ʾ�ļ���ܡ����� ResNet ��Ϊ Backbone,ǰ���� stage ����ԭʼ�Ľṹ,�ڵ��ĸ� stage ʹ������������Ұ��ͬ�IJ������� (Trident Block):
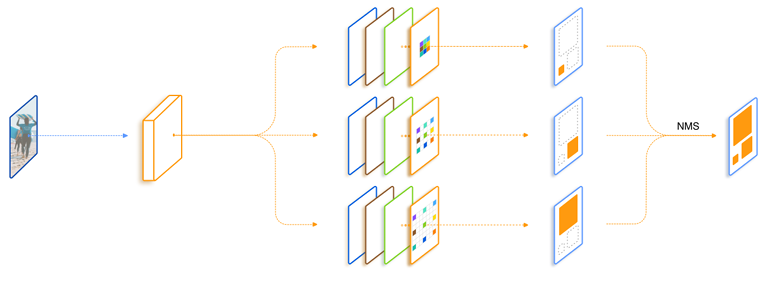 ����,���� 3 ����֧Ҫ������������ͬ�ġ�Ҫѧϰ������Ҳ����ͬ��,ֻ�������γ��˲�ͬ�ĸ���Ұ����ⲻͬ�߶ȵ�����,���,3 ����֧����Ȩ��,�����ȳ��������������Ϣ,ѧϰ�������ʵ���������Ϣ,Ҳ�����˲����������ϵķ��� (RPN �� RCNN ����Ҳ�ǹ�����)
����,���� 3 ����֧Ҫ������������ͬ�ġ�Ҫѧϰ������Ҳ����ͬ��,ֻ�������γ��˲�ͬ�ĸ���Ұ����ⲻͬ�߶ȵ�����,���,3 ����֧����Ȩ��,�����ȳ��������������Ϣ,ѧϰ�������ʵ���������Ϣ,Ҳ�����˲����������ϵķ��� (RPN �� RCNN ����Ҳ�ǹ�����)
- Scale-Aware Training: TridentNet ������� SNIP ��˼��,��ÿһ����֧��ֻѵ��һ���ߴ緶Χ�ڵ�����,�����˹������С�����������������ܲ���Ӱ��
- Fast Inference Approximation: �ڲ���ʱ,����û������ı�ǩ��ѡ��ͬ�ķ�֧�����м��֧�Խ�С�ͽϴ�����ļ�����ܶ��ȽϺ�,���ֻ������һ���м�һ����֧����ǰ�����������ǰ��ֻ�������ľ�����ʧ,ͬʱ��������ģ�������ٶ�
ӵ�����ڵ�
- ��ͨ�õ����������,�ڵ����������˵ļ���и�Ϊ�ձ�,������Ҳ�����˼������Ϊ���ֵ�����֮һ�����ڽ�������˼��ĽǶ�,�����ڵ�����ı���,�Լ���ν�����˼���е��ڵ�����
���˼������
Faster RCNN �������������,�����˼������� SSD ��һ�������������,ͨ����Ϊ���˼��Ļ����ṹ
���˼������ݼ�
- (1) Caltech: һ����ģ�ϴ�����˼�����ݼ�,������˴�Լ 25 ����ͼƬ,2300 �����˱�ǩ,��һ��ʮ�ֳ��õ����˼�����ݼ�
- (2) CityPersons: �� Cityscape �������ݼ��Ļ�����,��ע�˸�Ϊȫ������˱�ǩ,�����˵�������С���塢�ڵ��ķḻ������,��ʤ�����������ݼ�,���ѳ�Ϊ���˼���������ѡ�����������ݼ�
��߶ȼ��
- �����˼����,��߶ȼ��������ͬ������,���ʹ���ϲ����������²����ʡ�SNIP�������ںϵ�,Ҳ������Ч�������˼�������
- ������Ҫָ������,�������˾����������״,���߿��ȼ����� 2.41 ����,����������Ը�ǿ�� Anchor,Ҳ������Ч�������ľ���
�����ڵ��龰
- (1) ����֮������ڵ�: ����֮������ڵ�������Ӱ���������,��Ҫ������ (i) ��λ��ȷ:����ȡ���˵�����ʱ,�ڵ������������ȱʧ,���Ҿ���ܽ��������������Ӱ��,��������,�ⶼ�ή�����˶�λ��ȷ��;(ii) �� NMS ����ֵ��Ϊ����

- (2) ���˱����������ڵ�: �����ڵ��ᵼ�´��������Ϣȱʧ,��ʹ����Ҳ�������ж����˵ı߿����λ��,���������ϸߵ�����©��

��������ڵ�����
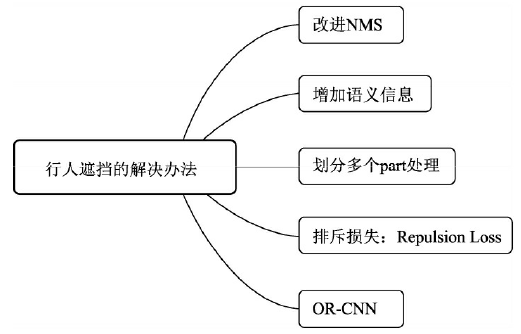
- (1) �Ľ� NMS:Soft NMS��IoU-Net��
- (2) ����������Ϣ:�ڵ���������˲�����Ϣ��ȱʧ,��˿��Գ���������������,��ָ���Ϣ���ݶȺͱ�Ե��Ϣ��,��ϸ�����ɼ� CVPR 2017 �е� HyperLearner
- (3) ���ֶ�� part ����:��������֮�����״��Ϊ����,��˿����������������Ϣ,�����˰��ղ�ͬ��λ,��ͷ�����������ֱ۵Ȼ���Ϊ��� part ���е�������,Ȼ�����ۺϿ���,������һ���̶��ϻ����ڵ�������������Ϣȱʧ
�ų���ʧ: Repulsion Loss
- �����忿��̫��ʱ,��Χ��������ʵ����Ļع���ɸ��š����ڴ�,������� Repulsion Loss ����������֮����Ӱ����Repulsion Loss �Ļع���ʧ����ʽ��ʾ:
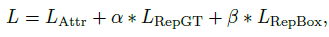
- Attraction Term
L
a
t
t
r
L_{attr}
Lattr? ������ǰ����Ԥ�������ֵ�������ع���ʧ,������ Faster RCNN ��
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ����
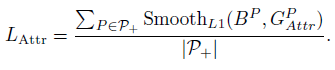 ����,
P
��
P
+
P\in \mathcal P_+
P��P+? Ϊ positive proposal,
G
A
t
t
r
P
=
arg?max
?
G
��
G
I
o
U
(
G
,
P
)
G_{Attr}^P=\argmax_{G\in\mathcal G}IoU(G,P)
GAttrP?=G��Gargmax?IoU(G,P),
B
P
B^P
BP �� proposal
P
P
P �ع�õ���Ԥ���
����,
P
��
P
+
P\in \mathcal P_+
P��P+? Ϊ positive proposal,
G
A
t
t
r
P
=
arg?max
?
G
��
G
I
o
U
(
G
,
P
)
G_{Attr}^P=\argmax_{G\in\mathcal G}IoU(G,P)
GAttrP?=G��Gargmax?IoU(G,P),
B
P
B^P
BP �� proposal
P
P
P �ع�õ���Ԥ��� - Repulsion Term (RepGT)
L
R
e
p
G
T
L_{RepGT}
LRepGT? ��ʾ��ǰԤ�������Χ��ʵ������ų���ʧ,Ŀ�����õ�ǰԤ�����Զ����Χ�ı�ǩ����
G
R
e
p
P
G_{Rep}^P
GRepP?,Ҳ���dz���Ԥ�����Ҫ�ع������֮��,���Ԥ�������� IoU �������ǩ
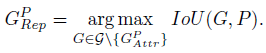 �� IoU Loss ������,�������Ԥ�������Χ�����ǩ�ľ���ʹ���� IoG (Intersection over GroundTruth) ����
�� IoU Loss ������,�������Ԥ�������Χ�����ǩ�ľ���ʹ���� IoG (Intersection over GroundTruth) ����
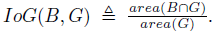 ���Կ���,
I
o
G
(
B
,
G
)
��
[
0
,
1
]
IoG(B,G)\in[0,1]
IoG(B,G)��[0,1],�� IoG �ķ�ĸ�dz���,��С IoG ֻ��ͨ����С
B
B
B ��
G
G
G ���ص���������������� IoU ��Ϊ���뺯�����Ż��Ļ�,���ڷ�ĸ���dz���,������Ԥ�������Ҳ���Դﵽ��С IoU ��Ŀ��,�������ǵ���������һ��,�����ģ���Ż����ȶ������⡣����,RepGT ������Ϊ
���Կ���,
I
o
G
(
B
,
G
)
��
[
0
,
1
]
IoG(B,G)\in[0,1]
IoG(B,G)��[0,1],�� IoG �ķ�ĸ�dz���,��С IoG ֻ��ͨ����С
B
B
B ��
G
G
G ���ص���������������� IoU ��Ϊ���뺯�����Ż��Ļ�,���ڷ�ĸ���dz���,������Ԥ�������Ҳ���Դﵽ��С IoU ��Ŀ��,�������ǵ���������һ��,�����ģ���Ż����ȶ������⡣����,RepGT ������Ϊ
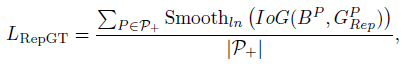
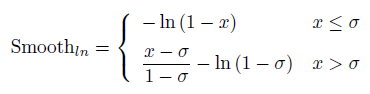 ����,
��
��
[
0
,
1
)
\sigma\in[0,1)
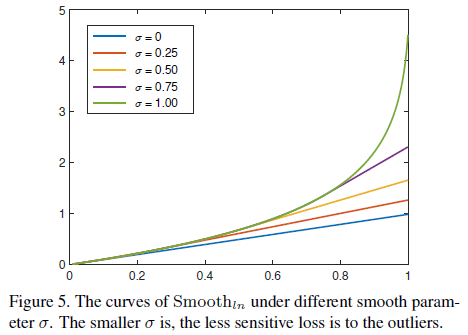
����[0,1) Ϊƽ������,
S
m
o
o
t
h
l
n
Smooth_{ln}
Smoothln? ��
(
0
,
1
)
(0,1)
(0,1) ��������
����,
��
��
[
0
,
1
)
\sigma\in[0,1)
����[0,1) Ϊƽ������,
S
m
o
o
t
h
l
n
Smooth_{ln}
Smoothln? ��
(
0
,
1
)
(0,1)
(0,1) ��������
- Repulsion Term (RepBox)
L
R
e
p
B
o
x
L_{RepBox}
LRepBox? ��ʾ��ǰԤ�������Χ����Ԥ���֮����ų���ʧ,Ŀ���DZ��Ȿ�������������Ԥ���,����һ���� NMS ���Ƶ�������ͼ���е������ǩ,���ǿ��Խ�����Ԥ���Ϊ�����,ͬ��֮���Ԥ���ع����ͬһ�������ǩ,��ͬ��֮���Ԥ����Ӧ���Dz�ͬ�������ǩ��������
g
g
g ������,����ʽ����ʽ��ʾ:
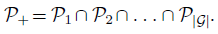 Ȼ��,���ڲ�ͬ��֮���Ԥ���
P
i
��
P
i
P_i\in\mathcal P_i
Pi?��Pi? ��
P
j
��
P
j
P_j\in\mathcal P_j
Pj?��Pj?,����ϣ��
B
P
i
B^{P_i}
BPi? ��
B
P
j
B^{P_j}
BPj? ֮����ص�����ԽСԽ��:
Ȼ��,���ڲ�ͬ��֮���Ԥ���
P
i
��
P
i
P_i\in\mathcal P_i
Pi?��Pi? ��
P
j
��
P
j
P_j\in\mathcal P_j
Pj?��Pj?,����ϣ��
B
P
i
B^{P_i}
BPi? ��
B
P
j
B^{P_j}
BPj? ֮����ص�����ԽСԽ��:

- ���� 3 ������ʧʹ���� �� �� �� �� �� �� �� ��������ʧȨ��,ʵ�����,�� �� �� �� �� �� �� �� ��Ϊ 0.5 ʱ,����������
- Attraction Term
L
a
t
t
r
L_{attr}
Lattr? ������ǰ����Ԥ�������ֵ�������ع���ʧ,������ Faster RCNN ��
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ����
OR-CNN (Occlusion-aware R-CNN)
�ۼ���ʧ:Aggregation Loss
- OR-CNN ���� Faster RCNN������ RPN �� RCNN �ζ������˾ۼ���ʧ��ʹ�ö��ƥ�䵽ͬһ�������ǩ�� Anchor �����ؿ��� (locate closely and compactly to the ground-truth object),������쵽��Χ�ٽ������ˡ��ۼ���ʧ
L
a
g
g
\mathcal L_{agg}
Lagg? Ϊ
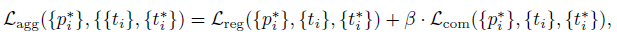 ����,
i
i
i Ϊ mini-batch �� proposal ������,
p
i
p_i
pi? ��
t
i
t_i
ti? ΪԤ��ķ���÷ֺ�����,
p
i
?
p^*_i
pi?? ��
t
i
?
t^*_i
ti?? Ϊ��ֵ,
��
\beta
�� Ϊƽ��������ʧ��ij���
����,
i
i
i Ϊ mini-batch �� proposal ������,
p
i
p_i
pi? ��
t
i
t_i
ti? ΪԤ��ķ���÷ֺ�����,
p
i
?
p^*_i
pi?? ��
t
i
?
t^*_i
ti?? Ϊ��ֵ,
��
\beta
�� Ϊƽ��������ʧ��ij��� - �ع���ʧ
L
r
e
g
\mathcal L_{reg}
Lreg? ʹ�� proposals �� GT �����ӽ�,������ Faster RCNN ��
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ��ʧ����
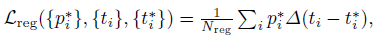 ����,
N
r
e
g
N_{reg}
Nreg? Ϊ�ܵ� proposal ��,
��
(
t
i
?
t
i
?
)
\Delta(t_i-t_i^*)
��(ti??ti??) Ϊ
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ��ʧ
����,
N
r
e
g
N_{reg}
Nreg? Ϊ�ܵ� proposal ��,
��
(
t
i
?
t
i
?
)
\Delta(t_i-t_i^*)
��(ti??ti??) Ϊ
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ��ʧ - ������ʧ (Compactness Loss)
L
c
o
m
\mathcal L_{com}
Lcom? ʹ��Ҫ�ع鵽ͬһ�������ǩ������ Anchor �����ܿ��ĸ���
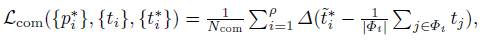 ����,
��
=
N
c
o
m
\rho=N_{com}
��=Ncom? Ϊ�ж�� Anchors ��Ӧ�� GT ������������ GT ��
i
i
i �ж�� Anchors ��֮��Ӧ,��
t
~
i
?
\tilde t_i^*
t~i?? Ϊ��Щ Anchors ��Ӧ��������ֵ,
��
i
\Phi_i
��i? Ϊ��Щ Anchors ��������,
1
�O
��
i
�O
��
j
��
��
i
t
j
\frac{1}{|\Phi_i|}\sum_{j\in\Phi_i}t_j
�O��i?�O1?��j����i??tj? Ϊ��Щ Anchors ��λ�þ�ֵ,
��
(
?
)
\Delta(\cdot)
��(?) Ϊ
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ��ʧ����
����,
��
=
N
c
o
m
\rho=N_{com}
��=Ncom? Ϊ�ж�� Anchors ��Ӧ�� GT ������������ GT ��
i
i
i �ж�� Anchors ��֮��Ӧ,��
t
~
i
?
\tilde t_i^*
t~i?? Ϊ��Щ Anchors ��Ӧ��������ֵ,
��
i
\Phi_i
��i? Ϊ��Щ Anchors ��������,
1
�O
��
i
�O
��
j
��
��
i
t
j
\frac{1}{|\Phi_i|}\sum_{j\in\Phi_i}t_j
�O��i?�O1?��j����i??tj? Ϊ��Щ Anchors ��λ�þ�ֵ,
��
(
?
)
\Delta(\cdot)
��(?) Ϊ
s
m
o
o
t
h
L
1
smooth_{L_1}
smoothL1?? ��ʧ����
���˲�λ���ijػ�:PORoI Pooling (Part Occlusion-aware RoI Pooling)
- �����˷ֶ����λ���,�ֱ���ȡ��ͬ��λ������,���ںϼ��,���ǽ�Ϊ�����Ĵ����ڵ�����Ľ���취��OR-CNN ����˸�˼��,��������˼���ںϵ��� RoI Pooling �Ĺ�����,����� PORoI Pooling
- ����,PORoI Pooling �������˵�����֪ʶ,������ (i.e. proposal
Q
Q
Q) �ֳ��� 5 ����λ
(
P
1
,
.
.
.
,
P
5
)
(P_1,...,P_5)
(P1?,...,P5?),5 ����λ�Ĵ�С�����˵Ŀ�����Ϊ�̶��ı�����ϵ�������� RoI Pooling �õ�����
(
F
1
,
.
.
.
,
F
5
)
(F_1,...,F_5)
(F1?,...,F5?) Ȼ�������ڵ�������Ԫ�õ��ɼ��ȵ÷� (visibility score)
(
o
1
,
.
.
.
,
o
5
)
(o_1,...,o_5)
(o1?,...,o5?)������֮��,��ֱ�Ӷ� proposal
Q
Q
Q ʹ�� RoI Pooling �õ���������
F
\mathcal F
F�����ͨ����Ԫ�ؼ���������յ�����Ϊ
F
��
(
o
1
?
F
1
)
��
(
o
2
?
F
2
)
��
(
o
3
?
F
3
)
��
(
o
4
?
F
4
)
��
(
o
5
?
F
5
)
\mathcal{F} \oplus\left(o_{1} \cdot F_{1}\right) \oplus\left(o_{2} \cdot F_{2}\right) \oplus(o_{3}\cdot F_3)\oplus(o_{4}\cdot F_4)\oplus(o_{5}\cdot F_5)
F��(o1??F1?)��(o2??F2?)��(o3??F3?)��(o4??F4?)��(o5??F5?)
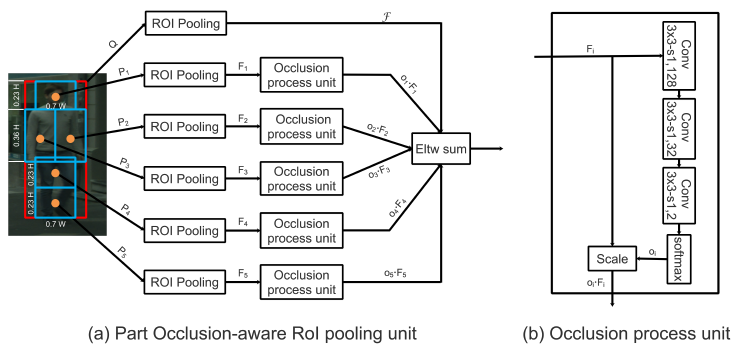 ����,�ڵ�������Ԫ��Ҫ����ÿ�����ֵ��ɼ��ȵ÷���ֵ
o
?
o^*
o? ��Ϊѵ��ʱ�ı�ǩȻ��ʹ�ý�������ʧ (i.e.
L
o
c
c
\mathcal L_{occ}
Locc?) ����ѵ��������ò��ֵ�һ���ǿɼ���,��
o
?
=
1
o^*=1
o?=1,��֮Ϊ 0,���Ҫ�����ȶ���Щ�����ǿɼ���,��Щ�Dz��ɼ��Ľ��б�ע
����,�ڵ�������Ԫ��Ҫ����ÿ�����ֵ��ɼ��ȵ÷���ֵ
o
?
o^*
o? ��Ϊѵ��ʱ�ı�ǩȻ��ʹ�ý�������ʧ (i.e.
L
o
c
c
\mathcal L_{occ}
Locc?) ����ѵ��������ò��ֵ�һ���ǿɼ���,��
o
?
=
1
o^*=1
o?=1,��֮Ϊ 0,���Ҫ�����ȶ���Щ�����ǿɼ���,��Щ�Dz��ɼ��Ľ��б�ע
��������,OR-CNN �� RPN ������ʧΪ:
RCNN ������ʧΪ:
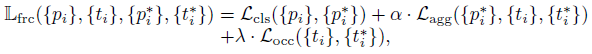
�����
- �����ѧϰ֮ PyTorch ������ʵս��