����˹�ֲ� MLE
posterior �������� likelihood * prior
p ( �� �O x ) �� p ( x �O �� ) ? p ( �� ) p(\theta | x) \propto p(x|\theta) * p(\theta) p(���Ox)��p(x�O��)?p(��)
�� �� �� �� �� �� �� �� �� �� �� �� �� ʾ �� x �� �� �� �� ֪ �� �� �� �� �� �� �� ? �� �� �� �� �� �� �� �� ����\theta�ĺ���ֲ� \propto ����\theta��ʾ��x�ֲ�����֪�����ж����� * ����\theta������ֲ� ��������������������������ʾ��x��������֪��������������?����������������
�� �� �� �� �� �� �� �� �� l i k e l i h o o d ? �� �� �� �� �� ������� \propto ������likelihood * ���������� ������������������likelihood?����������
MLE : max log_likelihood estimator
MAP: max a posterior
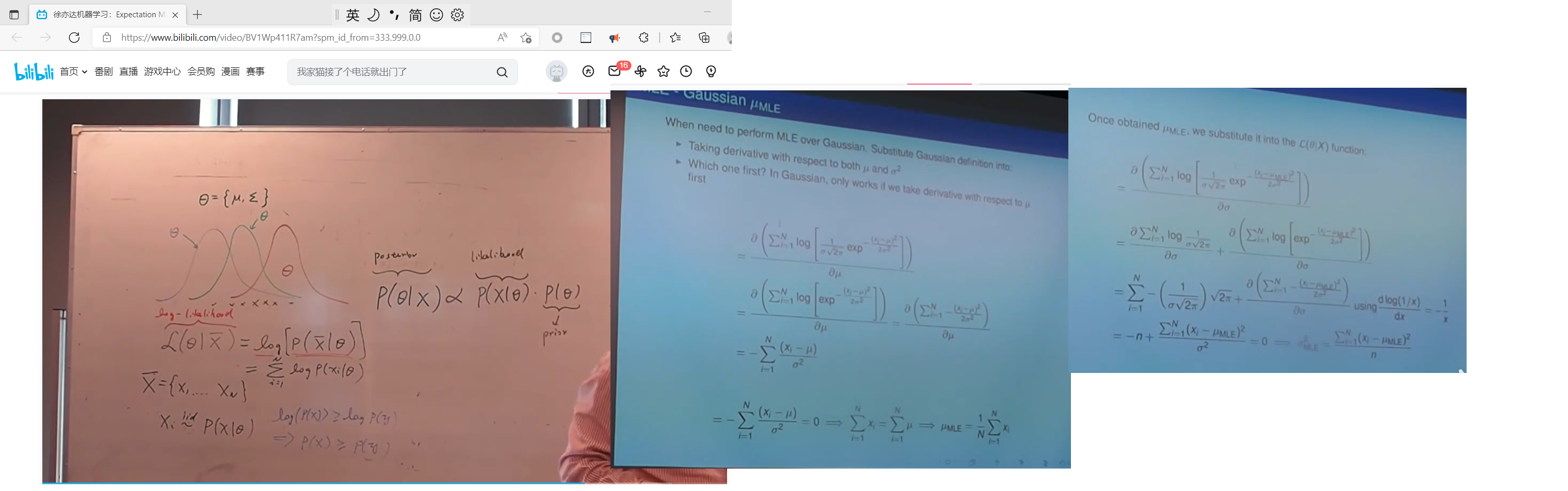
��ϸ�˹�ֲ�(�����˹�ֲ������һ��) MLE
����˹��Ϸֲ�, ֻ��Ҫ��: ? L ? u = 0 \frac{\partial{L}}{\partial{u}}=0 ?u?L?=0, ? L ? �� = 0 \frac{\partial{L}}{\partial{\Sigma}}=0 ?��?L?=0 ; ����һ����λ�ľ�ȷ����� u �� �� u��\Sigma u������ֵ
��ϸ�˹�ֲ�,����L����log(���ʽ�����), ��log(���ʽ�����)��������ǿ��Ե�, �� Ҫ�� ? L ? u = 0 \frac{\partial{L}}{\partial{u}}=0 ?u?L?=0�� ? L ? �� = 0 \frac{\partial{L}}{\partial{\Sigma}}=0 ?��?L?=0 �Ƚ���, ���� û��һ����λ��ȷ���,ֻ�ܵ������ �� �˵�����ⷽ�� �� EM�㷨
��:
�ⷽ�� ? l o g ( �� �� ʽ �� �� �� �� ) ? �� �� һ �� �� �� \frac{\partial{log(���ʽ�ӵij˻�)}}{\partial{����һ������}} ?����һ������?log(����ʽ��������)? = 0 ����
�ⷽ�� ? l o g ( �� �� ʽ �� �� �� ) ? �� �� һ �� �� �� \frac{\partial{log(���ʽ�ӵĺ�)}}{\partial{����һ������}} ?����һ������?log(����ʽ������)? = 0 ������
ע��:���ߵĵ�����������ó���
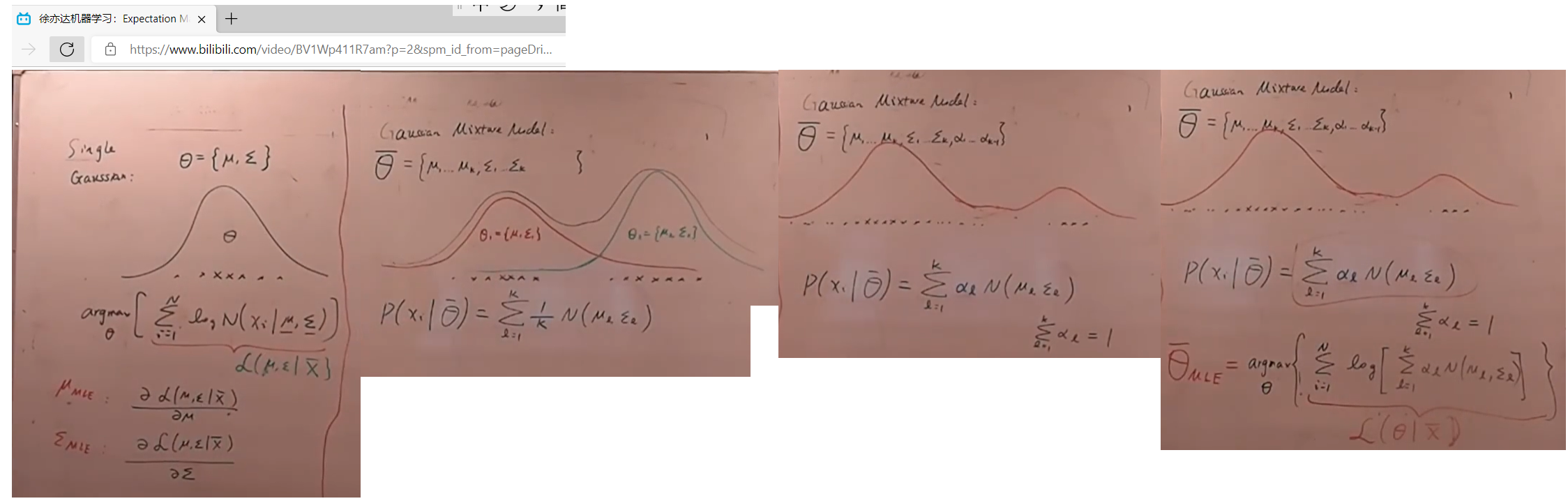
EM�㷨(��ϸ�˹�ֲ�)
���ĵ���ֵu����״��Э������� �� \Sigma ��

em�㷨����������ʾ
e m �� �� �� �� �� �� ʼ �� Ϊ �� ( 1 ) em�㷨����\Theta��ʼ��Ϊ\Theta^{(1)} em������������ʼ��Ϊ��(1)
e m �� �� �� 1 �� �� �� �� �� �� ( 2 ) em�㷨��1�ε������\Theta^{(2)} em������1������������(2)
e m �� �� �� 2 �� �� �� �� �� �� ( 3 ) em�㷨��2�ε������\Theta^{(3)} em������2������������(3)
e m �� �� �� f �� �� �� �� �� ( e m �� �� �� �� ʱ �� �� �� ) �� ( f ) em�㷨��f�ε������(em�㷨����ʱ�Ľ��) \Theta^{(f)} em������f����������(em��������ʱ������)��(f)

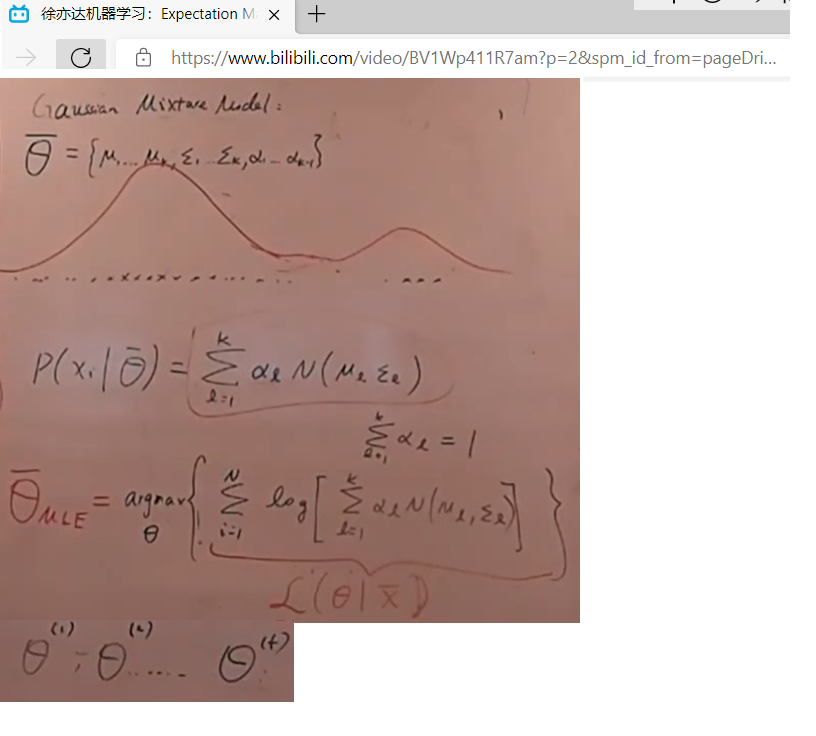
em��������
em�㷨������������:
�� ( g + 1 ) = �� ( g ) \Theta^{(g+1)}=\Theta^{(g)} ��(g+1)=��(g)
�� ( g + 1 ) = a r g m a x �� �� z l o g p ( X , z �O �� ) p ( z �O X , �� ( g ) ) d z \Theta^{(g+1)}={argmax}_{\Theta}\int_{z} {log p(X,z|\Theta) p(z|X,\Theta^{(g)})} dz ��(g+1)=argmax��?��z?logp(X,z�O��)p(z�OX,��(g))dz (������ Ū����� ��ͷҪ��ȷһ��)

em�㷨�����������zӦ�ñ��ֱ�Ե�ֲ�����:

����� z i z_i zi? ����ǰ��"EM�㷨(��ϸ�˹�ֲ�)" �е� �� l \alpha_l ��l?
��ͼ p ( x i ) p(x_i) p(xi?) ���� p ( x i �O �� ) p(x_i|\Theta) p(xi?�O��)
em�㷨�� log_likelihood l o g p ( X �O �� ) log p(X|\Theta) logp(X�O��) ������ �Ƶ� 1
��� �������� �� \Theta �� �� H ( �� ( g ) , �� ( g ) ) �� H ( �� , �� ( g ) ) H(\Theta^{(g)}, \Theta^{(g)} ) \ge H(\Theta, \Theta^{(g)} ) H(��(g),��(g))��H(��,��(g)),
�� H ( �� ( g ) , �� ( g ) ) �� H ( �� ( g + 1 ) , �� ( g ) ) H(\Theta^{(g)}, \Theta^{(g)} ) \ge H(\Theta^{(g+1)}, \Theta^{(g)} ) H(��(g),��(g))��H(��(g+1),��(g))

em�㷨�� log_likelihood l o g p ( X �O �� ) log p(X|\Theta) logp(X�O��) ������ �Ƶ� 2
Jensen��s inequality (��������ʽ)

��
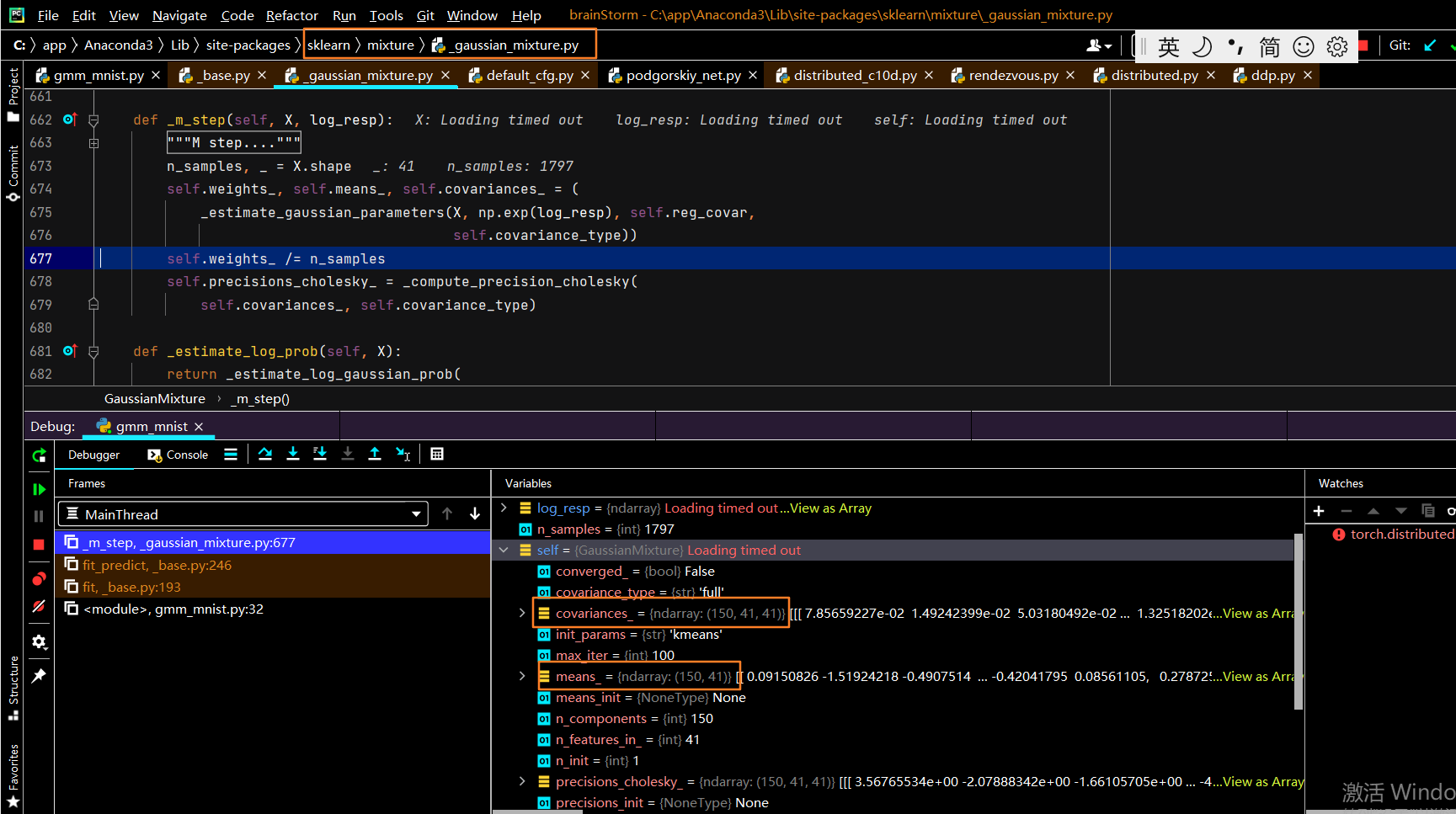
"""sklearn ��д�������ݼ� gmm ���� (ͼƬ��һ�����ص㱻����һ���������)
���� https://jakevdp.github.io/PythonDataScienceHandbook/05.12-gaussian-mixtures.html
�� https://github.com/jakevdp/PythonDataScienceHandbook/blob/master/notebooks/05.12-Gaussian-Mixtures.ipynb
"""
import numpy as np
from sklearn.datasets import load_digits
from matplotlib import pyplot as plt
def plot_digits(data):
fig, ax = plt.subplots(10, 10, figsize=(8, 8),
subplot_kw=dict(xticks=[], yticks=[]))
fig.subplots_adjust(hspace=0.05, wspace=0.05)
for i, axi in enumerate(ax.flat):
im = axi.imshow(data[i].reshape(8, 8), cmap='binary')
im.set_clim(0, 16)
plt.show()
digits = load_digits()
print(digits.data.shape)#(1797, 64)
# plot_digits(digits.data)
from sklearn.decomposition import PCA
pca = PCA(n_components=0.99, whiten=True)
data = pca.fit_transform(digits.data)
print(data.shape)#(1797, 41)
from sklearn.mixture import GaussianMixture
"""
n_components = np.arange(50, 210, 10)
models = [GaussianMixture(n_components=n, covariance_type='full', random_state=0) for n in n_components]
aics = [model.fit(data).aic(data) for model in models]
plt.plot(n_components, aics); plt.show()
"""
gmm = GaussianMixture(n_components=150, covariance_type='full', random_state=0)
gmm.fit(data)
print(gmm.converged_)
data_new,label_new = gmm.sample(n_samples=100)
print(data_new.shape)
digits_new = pca.inverse_transform(data_new)
plot_digits(digits_new)