�������ֻ�ת�����˹����ܷ�չ,AIӦ�������������,������Ȼ�����˹���������,����,��ҵ�������ѽ�������AIӦ������,�������ɵ���Ҫ��:
- Ԥ���ʶ���ȷ��
- ģ�������
- ³����
- ��ȫ��
- ������˽
- ������
- ��ƽ��
- �ɽ�����
������,���Ľ��ӻ���ѧϰģ�Ϳ������̡�AIӦ��������������,��ϲ��Թ���,̸̸��ν��л���ѧϰAIģ�Ͳ�����ģ������������
ע:Ϊ�˱�������,�������ڼලѧϰ�㷨Ӧ�÷�Χ��
1. ����ѧϰAIӦ������������������Թ���
AIӦ��������������(����ֱ�ӵ����㷨API�ӿ�����)�봫ͳ��Ϣ��Ӧ��������רҵ�����Ա�,�и������IJ��,�����㷨ģ��ѧϰ����,ͨ��������ѵ���㷨ģ��,�㷨ģ��ͨ��������������,������Ӧ�������л���������Ӧ�á�
����,AIӦ��������ʹ�õ�����,һ����Ҫ��������Ԥ����,��Ϊ�㷨ģ����ʹ�á�
���ڿ��������е��㷨ģ��ѧϰ������Ԥ��������,���Թ������ڴ�ͳ�Ĺ��ܡ�ϵͳ���Ի�����,�������ӡ����������㷨ģ�͡�����

�����˹����ܵķ�չ��Ӧ��,��ͳ�Ĺ��ܲ��Բ��Զ����㷨���Զ���,�������������,����������˹����� (AI) ���������ϡ�
2. AIӦ���������Թ���
2.1. ��ͳӦ����������
�Դ�ͳӦ������Ϊ��,���Թ��̰������Լƻ�����д��������������Ի�����ִ�в��ԡ���д���Ա��桢�ٿ���̱��������Ҫ�ڵ㡣

����,����Ի�����,��������������,�ܶ�ʱ��,�����������Ǹ��dz�רҵ�����صĹ���,������������:
- ����GUI�������ɲ�������;
- ͨ��API�������ɲ�������;
- ͨ�����ݿ�������ɲ�������;
- �ۺ�����API�����ݿ�ķ�ʽ���ɲ������ݡ�
�Ӳ������ݴ�����ʱ������,��Ҫ��ΪOn-the-fly(ʵʱ����)��Out-of-box(���ȴ�����������)�����������������и��Ե���ȱ��,�Լ����õ���ѳ�����
2.2. AIӦ�ò��Թ���
�Բ�����Ա�ӽ�,AIӦ�ò��Թ����봫ͳ�������Թ��̶Ա�,�������㷨ģ�Ͳ�����������,��ν����㷨ģ�Ͳ���,AIӦ���������ԡ�

���̽����ʵ���Ĺ���,AI�㷨ģ�Ͳ��Դ��°������¼������ԡ�
- �㷨���Լ�������
- �㷨ģ���������
- �㷨���ܲ���
- �㷨���ܲ���
- �㷨Ч������(ģ������ָ��)
- �㷨ָ��������
- �㷨���Ա���
3. �㷨ģ�Ͳ��Թؼ���
3.1. �㷨���Լ�������
3.1.1. ���Լ�������
3.1.1.1. �������������ݼ�(hold-out)
�������DZȽϳ��õķ���,��ֱָ�ӽ����ݼ�D����Ϊ��������ļ���,����һ��������Ϊѵ����S,����һ����Ϊ���Լ�T,��D=S��T,S��T=�ռ�����S��ѵ����ģ�ͺ�,��T��������������,��Ϊ�Է������Ĺ��ơ�
����,����������,���˻���Ϊ���Լ�,��֤���������ֻ��ַ�ʽ��
- ѵ������,��֤���ݺͲ������ݰ���6:2:2�ķ�ʽ�������ݼ�
- ���������dz���ʱ,����ʹ�� 98 : 1 : 1 �ı�������ѵ������,��֤���ݺͲ�������

��Ҫע�������:
- ѵ��/���Լ��Ļ���Ҫ�����ܵı������ݷֲ���һ����,���������ݻ��ֹ�����������ƫ��������ս������Ӱ�졣
- �ڸ���ѵ��/���Լ�������������,��Ȼ���ڶ��ֻ��ַ�ʽ�Գ�ʼ���ݼ�D���л���,���ܻ��ģ�������Ľ������Ӱ�졣���,����ʹ���������õ��Ľ�����������ȶ��ɿ�,��ʹ��������ʱ,һ��������ɴ�������֡��ظ�����ʵ��������ȡ��ƽ��ֵ��Ϊ���������������
3.1.1.2. ������֤��
k �۽�����֤ͨ���� k ����ͬ����ѵ���Ľ������ƽ�������ٷ���,���ģ�͵����ܶ����ݵĻ��־Ͳ���ô���С�

- ��һ��,���ظ�������ԭʼ���������Ϊ k �ݡ�
- �ڶ���,ÿһ����ѡ���� 1 ����Ϊ���Լ�,ʣ�� k-1 ����Ϊѵ��������ģ��ѵ����
- ������,�ظ��ڶ��� k ��,����ÿ���Ӽ�����һ�λ�����Ϊ���Լ�,���������Ϊѵ��������ÿ��ѵ������ѵ����õ�һ��ģ��,�����ģ������Ӧ�IJ��Լ��ϲ���,���㲢����ģ�͵�����ָ��,
- ���IJ�,���� k ����Խ����ƽ��ֵ��Ϊģ�;��ȵĹ���,����Ϊ��ǰ k �۽�����֤��ģ�͵�����ָ�ꡣ
3.1.1.3. ������
��ͳ��ѧ��,������(Bootstrap Method,Bootstrapping������������)��һ�ִӸ���ѵ�������зŻصľ��ȳ���,Ҳ����˵,ÿ��ѡ��һ������,���ȿ��ܵر��ٴ�ѡ�в����ٴ����ӵ�ѵ�����С�
���ݼ�D�д���m������,��������������,�����ݼ������зŻصij���m�κ�,����ʼ�ղ����ɵ��ĸ���Ϊ ( 1 ? 1 m ) m (1- \frac{1}{m})^m (1?m1?)m,ȡ���õ�:
lim ? ( 1 ? 1 m ) m = 1 e �� 0.368 \lim(1-\frac{1}{m})^m=\frac{1}{e}\approx0.368 lim(1?m1?)m=e1?��0.368
��ͨ����������,��ʼѵ����D��Լ��36.8%������δ�����ڲ������ݼ�D���С����ǿɽ�D������ѵ����,D/D���������Լ���
�����������ݼ�С,���Ի���ѵ��/���Լ�ʱ���á�
3.1.2. ���Լ��淶Ҫ��
���Լ��������������㷨���Զ��Էdz���Ҫ,һ����Լ����������迼�����¼���:
- ���Լ��ĸ��Ƕ�
- ���Լ��Ķ�����
- ���Լ���ȷ��
3.1.2.1. ���Լ��ĸ��Ƕ�
���,���Լ���ֻ�������ѡȡ��������,��������ɲ��Խ����ʧ��,�����㷨ģ����������Ŀɿ��ԡ�
�ñȴ�ͳ�������ܲ���,���ݹ��ܲ������,�����Ӧ�����ݽ��в��Ը��ǡ��㷨ģ�Ͳ�����Ȼ,����������㷨����,���˿���ѡȡ����������������,����Ҫ���������������������ĸ���,������ռ�ȡ�ģ���ȡ����ա���̬(�Ƕ�)��������(�ڵ�)��������
�Դ����,�����ͻ���չԤ��IJ��Լ�(����ѵ����),���Ⱥ�ֲ�,�������ȡѵ����,���簴�ͻ���Աʱ�����������������������Ʒƫ�á��۸����С���ֵϰ�ߵ�������
����,�������������ĸ���,Ҳ��Ҫ����������Դ�ĸ���,���ʵ��Ӧ�û��������������ݽ�������ģ�⡢����
����,���ڲ������ݵ�����,һ����������������Խ��Խ�ܿ۵ķ�ӳ�㷨����ʵЧ��,�����ڲ��Գɱ��Ŀ���,�������価,����ѡȡ��2�����ҵ�ͼƬ���в��ԡ�ѡȡ10���Ա�ͻ����ԡ�
3.1.2.2. ���Լ��Ķ�����
���Լ��Ķ�������Ҫ���Dz������ݼ�����ŵ��²��Խ����ʧ����ա�
3.1.2.3. ���Լ���ȷ��
���ݼ���ȷ��һ��ָ�������ݱ�ע��ȷ��,����Jack����Ƭ��Ӧ��עΪTom,��Ƭģ����������Ӧ��עΪ������������ݱ�ע����,��ôֱ��Ӱ�����㷨ģ��ָ�����Ľ����
3.2. �㷨ģ���������
��������ѧϰģ�͵Ļ��������Լ��������漰����Ҫ�������ͼ��ʾ��
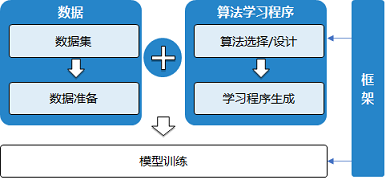
����ѧϰģ�͵Ŀ���������Ҫ�����ݡ�ѧϰ����ѧϰ��ܵȶ��������н���,��ÿ����������ܰ����������,�ڽ��л���ѧϰ����ʱ,������Ա������Ҫ���Բ���ÿ������е�bug,�������ݡ�ѧϰ����Ϳ�ܡ��ر���,������һ�������ص�����,����ѧϰ����,��Ϊ���֮�����ϵ�ȴ�ͳ����������,���������ÿ������ѧϰ�������Ҫ�ԡ�
3.2.1. ����
����ѧϰϵͳ����Ϊ�ںܴ�̶���ȡ�������ݡ������еĴ����Ӱ�����ɵ�ģ�͵�����,���ҿ��ܻᱻ�Ŵ�,��һ��ʱ���ڲ��������ص����⡣�����еĴ����������������Ƿ��㹻����ѵ�������ģ��(Ҳ��Ϊ���ݵ�������)�������Ƿ����δ�����ݡ������Ƿ������������(������ƫ���ı�ǩ)��ѵ�����ݺͲ�������֮���Ƿ����ƫ��Լ��Ƿ���ڿ���Ӱ��ģ�����ܵ������ж��������Ϣ�����⡣
3.2.1. ���
��ܲ��Լ�����ѧϰ�Ŀ���Ƿ��п��ܵ�������ϵͳ��������Ĵ���
3.2.3. ѧϰ����
ѧϰ������Է�Ϊ��������:�ɿ�����Ա��ƻ�ӿ����ѡ����㷨,�Լ�������ԱΪʵ�֡�����������㷨����д��ʵ�ʴ��롣ѧϰ�����п��ܻ���ִ���,���������Ϊ�㷨��ơ�ѡ������ò���ȷ,��������Ϊ������Ա��ʵ������Ƶ��㷨ʱ���� ����
3.3. �㷨Ч������(ģ������ָ��)
�ڻ���ѧϰ�����ѧϰ�������ھ�����,��ҵ�����������ʵ�ʵ�ҵ���ⶨ��Ӧ��ҵ��ָ�ꡣ�����㷨ģ��һ���Ϊ�������⡢�ع����⡢�Ż�Ŀ�������ָ�ꡣ
3.3.1. ����ָ�����
3.3.1.1. ������������ָ��
��ʵ,������������ָ�����ʺ϶���������,ֻ�Ǿ��������Ƕ������,������Ȼ����ָ��ʱ���Զ����ʼ,���ǹ�ʽ������չ������ࡣ
- ȷ�� �C Accuracy
- ��ȷ��(����)- Precision
- �ٻ���(��ȫ��)- Recall
- F1����
- ROC����
- AUC����
3.3.1.2. �ع���������ָ��:
- MAE
- MSE
3.3.1.3. �Ż�Ŀ��ָ��:
- ������ �� cross-entropy
- rmse
3.3.2. ����ָ�����
3.3.2.1. ��������
��������(confusion matrix)Ҳ��������,�DZ�ʾ�������۵�һ�ֱ���ʽ,�� n n n�� n n n�еľ�����ʽ����ʾ�����˹�������,�ر����ڼලѧϰ��������һ�������������ȷ�̶�,�ȽϷ�������ʵ�ʲ��ֵ,���ѷ������ľ�����ʾ��һ�������������档
�������������ڶ������������,����Ϊ���ö��������������,����д���֡�5������ʶ���Ԫ����Ļ�������Ϊ��˵����

- ������(True Positive,TP):��������ʵ���������,����ģ��Ԥ��Ľ��Ҳ������
- ������(True Negative,TN):��������ʵ����Ǹ���,����ģ�ͽ���Ԥ���Ϊ����
- ������(False Positive,FP):��������ʵ����Ǹ���,����ģ�ͽ���Ԥ���Ϊ����
- ������(False Negative,FN):��������ʵ���������,����ģ�ͽ���Ԥ���Ϊ����
3.3.2.2. ȷ��P���ٻ���R��F1 ֵ

���������֪�����֮�����ֵ����,�鿴�Ƿ����ض�����������,�Ϳ����û��������������ϸԤ���������ڰ��������������,���Ժ������ķ�ӳ�����֮��Ĵ��ָ��ʡ�
- ȷ��(Accuracy): A c c = T P + T N T P + T N + F P + F N Acc=\frac{TP+TN}{TP+TN+FP+FN} Acc=TP+TN+FP+FNTP+TN?��ͨ�ؽ�,����Ԥ����ȷ�Ľ��ռ�������İٷֱȡ�
��Ȼȷ�ʿ����ж��ܵ���ȷ��,������������ƽ�� �������,��������Ϊ�ܺõ�ָ��������������ٸ�������,������һ����������,������ռ 90%,������ռ 10%,���������ز�ƽ��ġ������������,����ֻ��Ҫ��ȫ������Ԥ��Ϊ���������ɵõ� 90% �ĸ�ȷ��,��ʵ�������Dz�û�к����ĵķ���,ֻ���������һ�ֶ��ѡ����˵����:����������ƽ�������,�����˵õ��ĸ�ȷ�ʽ�����кܴ��ˮ�֡������������ƽ��,ȷ�ʾͻ�ʧЧ��
- ����(Precision): P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP?��ͨ�ؽ�,����Ԥ����ȷ����������ռԤ��Ϊ�������ݵı�����
- �ٻ���(Recall): R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP?��ͨ�ؽ�,����Ԥ��Ϊ����������ռʵ��Ϊ�������ݵı���
- F1ֵ(F1 score):
F
1
=
2
1
P
+
1
R
F1=\frac{2}{\frac{1}{P} + \frac{1}{R}}
F1=P1?+R1?2?���ֳ�ƽ��F����(balanced F Score),��������Ϊ��ȷ�ʺ��ٻ��ʵĵ���ƽ������
F1��ֵͬʱ�ܵ�P��R��Ӱ��,��������P��R��������û��̫�����á���ʵ��ҵ����,�������������,��ȷ��һ���dz�����ս���¡�
3.3.2.3. ROC��AUC����
ROC������Receiver Operating Characteristic Curve�ļ��,������Ϊ�������߹����������ߡ���
ROC���ߵĺ�����Ϊ��������(False Positive Rate,FPR);������Ϊ��������(True Positive Rate,TPR)��FPR��TPR�ļ��㷽���ֱ�Ϊ:
- ��������:
T
P
R
=
T
P
T
P
+
F
N
TPR= \frac{TP}{TP+FN}
TPR=TP+FNTP?
? - ��������: F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP?
ROC���ɵ�(TPR,FPR)��ɵ�����,AUC����ROC�������
һ����˵,AUCԽ��Խ��;���TPRԽ��,ͬʱFPRԽ��(��ROC����Խ��),��ôģ�͵����ܾ�Խ��;ROC�ǹ⻬��,��ô���������ж�û��̫���overfitting?��
Ϊʲôʹ�� ROC ����
��Ȼ�Ѿ���ô�����۱�,Ϊʲô��Ҫʹ�� ROC �� AUC ��?��Ϊ ROC �����и��ܺõ�����:�����Լ��е����������ķֲ��仯��ʱ��,ROC �����ܹ����ֲ��䡣��ʵ�ʵ����ݼ��о���������ƽ��(class imbalance)����,������������������ܶ�(�����෴),���Ҳ��������е����������ķֲ�Ҳ��������ʱ��仯��
3.4. ��Ԫ����
����ѧϰģ�Ͳ�������Ԫ����,�������������Ϊ����ѧϰȱ���ȶ���,�������м���̺����ս����ƽ�ȡ�ԭ������:
- ������ȶ���(Computational Stability)
- �㷨�ȶ���(Algorithmic Stability)���Ŷ�(Perturbation)
- ���ݵ��ȶ���(Data Stability)
- ����һ����Ҫ��ԭ������������������һ���ں�,�����ִ���������ģ��,�����������ء�
ʲô����¿�������Ԫ����?
����ѧϰ������Ҫ�е�Ԫ���Ե�,��Tensorflow��Theano֮������ѧϰ��ܡ���������һ���ܵĵ�Ԫ����Ҳ���Կ����������:ģ����С����
����ʹ��TensorFlowTestCase���е�Ԫ���ԡ�
3.5. ��������ָ�����
-
������˽����ָģ������Զ����û�������ͼ��ȡ�û���˽���ݻ�ģ�Ͳ�����Ϣ����ȡ������Ϊʱ�Ĵ���������
-
³����(robustness)Ҳ����Ϊ��׳�Ի����Ƚ���,��ָ����ģ�Ͷ��쳣���β������쳣����Ĵ���������ȱʧֵ������ֵ���������ͻ��ʽ��ͳһ,�Կ���Ϣ�ȶ�����Ӱ��ģ�͵�����,��Щ������ģ��³�����о������ݡ�������,ѧ�����ģ�͵ĶԿ�³�����о��϶�,���ǰ�ȫ�ؼ��������Ҫ���Ǻͽ�������⡣
-
��ȫ��������Ӣ�ĵ��ʶ�Ӧ:Security��Safety��securityǿ��ģ�Ͷ������ⲿ���ڲ����������⡱����ʱ�Ĵ����������Կ�����������Ͷ������������security�ķ��롣Safety��ȻҲ�а�ȫ�Եĺ���,����ǿ��ģ������Կ۴��ڵ�DZ��Σ��ʱ�Ĵ���������
4. �ܽ�
4.1. ��ͳ����������AIӦ���������ԶԱȷ���
| ��� | �Ա���� | ��ͳ�������� | AIӦ���������� |
|---|---|---|---|
| 1 | �������(Bug������) | ������ | ������ݡ�ѧϰ����Ϳ���е����ݺʹ��� |
| 2 | �����е���Ϊ | ��Ϊ������̶���ͨ���ǹ̶��� | ��Ϊ���ܻ�����ѵ�����ݵĸ��¶�Ƶ���仯 |
| 3 | �������� | ͨ���Dz��Դ���ʱ���������� | ����������ܻ��и������ʽ,��������� |
| 4 | ����������Դ | �Ϳ�����Ա����,���Զ�������ֵ��֤��� | ����һ������ֵ���ɴ�,�ֶ�ȷ��,����,�������������ݱ�ǩ��˾������ֶ���ǩ |
| 5 | ���Գ���Ա� | ������/������� | �� |
| 6 | ���Ĵ����г����� | ���� | �ձ� |
| 7 | ���Խ�ɫ | ������ | ���ݿ�ѧ�ҡ��㷨����ߡ������� |
- ��ע��,���ǽ����������롱�͡��������ݡ��Ķ���ֿ����ر��,����ʹ�á��������롱��ָ�����ڽ��л���ѧϰ���Ե��κ���ʽ������;�����������ݡ�ר��ָ������֤MLģ����Ϊ�����ݡ����,ML�����еIJ������������,���Dz����ڲ������ݡ�������ѧϰ����ʱ,�����������������Բ������ݵĵ�������ʵ�������ѵ����;����������ʱ,�������������ѧϰ����
- ���Գ���Ա����ڶ��Ѳ��Ե�Ŀ�������ij̶��ṩ����������
4.2. ����������ģ������������AIӦ���������Ժ���
����ѧϰAIӦ������ϵͳ��Ϊ����ϵͳ,����Դ����������������Ѿ��㷺�о���������֪�Ľ����������ͬ��,������ѧϰϵͳ��ͳ�����ʼ����������ߵ�����Ϊ������������˶���ġ�������ս�Ե��о�����:
-
����ѧϰϵͳ��������ѭ���������ı�̷���,���о�������ͨ������ѧϰ�㷨��ϵ�ṹ�µ�ѵ�����ݵ�ѵ�����̻�õġ���ģ�͵���Ϊ���ܻ�����ʱ������ƶ��ݱ�,����Ӧ�����ݵ�Ƶ���ṩ��
-
AIӦ�ò��Թ����Ǹ��dz�����ս�Ե�����,�������ѧϰϵͳ���Ѳ��Ե�����,Ҫ����������˼ά���в���������,��ѡ����ʵ�ģ������������
���ڱ���ˮƽ����,��ӭ�����о���
�ο�:
[1]. �������Կ�������ջ. ���˹����� (AI)��չӦ�ÿ��㷨���ԵIJ��Բ���. ����ͷ��. 2019.07
[2]. ����ѧϰ���������Ԫ����(Unit Test)�����ģ���ȶ���?. ֪��. 2017.08
[3]. �� venus��. ����ѧϰģ��������Ԥ��. CSDN����. 2019.08
[4]. Andrew Wan . ����ѧϰ/���ѧϰϵͳ���� (һ) . ֪�� . 2020.03
[5]. Andrew Wan . ����ѧϰ/���ѧϰϵͳ���� (��) . ֪�� . 2020.10
[6]. ����� . [���Ľ��]���ڻ���ѧϰ����,����һƪ���ľ��� Machine Learning Testing: Survey ,Landscapes and Horizons. CSDN���� . 2020.03
[7]. isisiwish. �����ԡ� - �������� & ���������� - δ���. ֪�� . 2019.11
[8]. Ф����. ��ƽ����������ģ������ָ��̽����sklearn.metricsʵ��. CSDN����. 2021.05