yolov5实践纪录,
模型训练
训练时需要修改的几个地方,
不论如何,先git下载代码,然后下载单独的模型,在根目录下yolov5s.pt文件。
data文件夹下修改,yaml文件
举例:
train: ../train/images
val: ../valid/images
nc: 2
names: ['mask', 'no-mask']
数据集格式
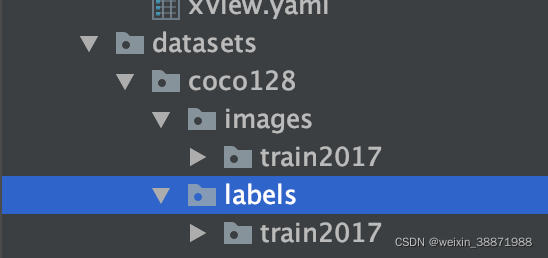
labels每个文件和images每个图片原文件相同,文件内容,每行包含识别的标签,和每个预测框的初始坐标和长宽。一个文件可以包含多行,即包含多个预测目标
训练的时候需要修改的几个超参数的地方
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
# parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/mask_kouzhao.yaml', help='dataset.yaml path')
# parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=10)
# parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
# parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add
参考如上
预测
上代码:
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
主要就这三个地方需要修改
单独写一个预测文件flask部署识别问题,明天再代码补上。
导出
导出时需要注意的几个点,批次的修改,修改为16,不知道是不是对最后问题的原因,待定。
部署在Android时,如有问题,需要卸掉软件重新安装,Android端导入的模型需要与原来的名字相同,yolos…plt
输出维度你的修改需要做输出类别加5,的操作。
然后,然后好像就可以了哇
部署
数据处理的问题
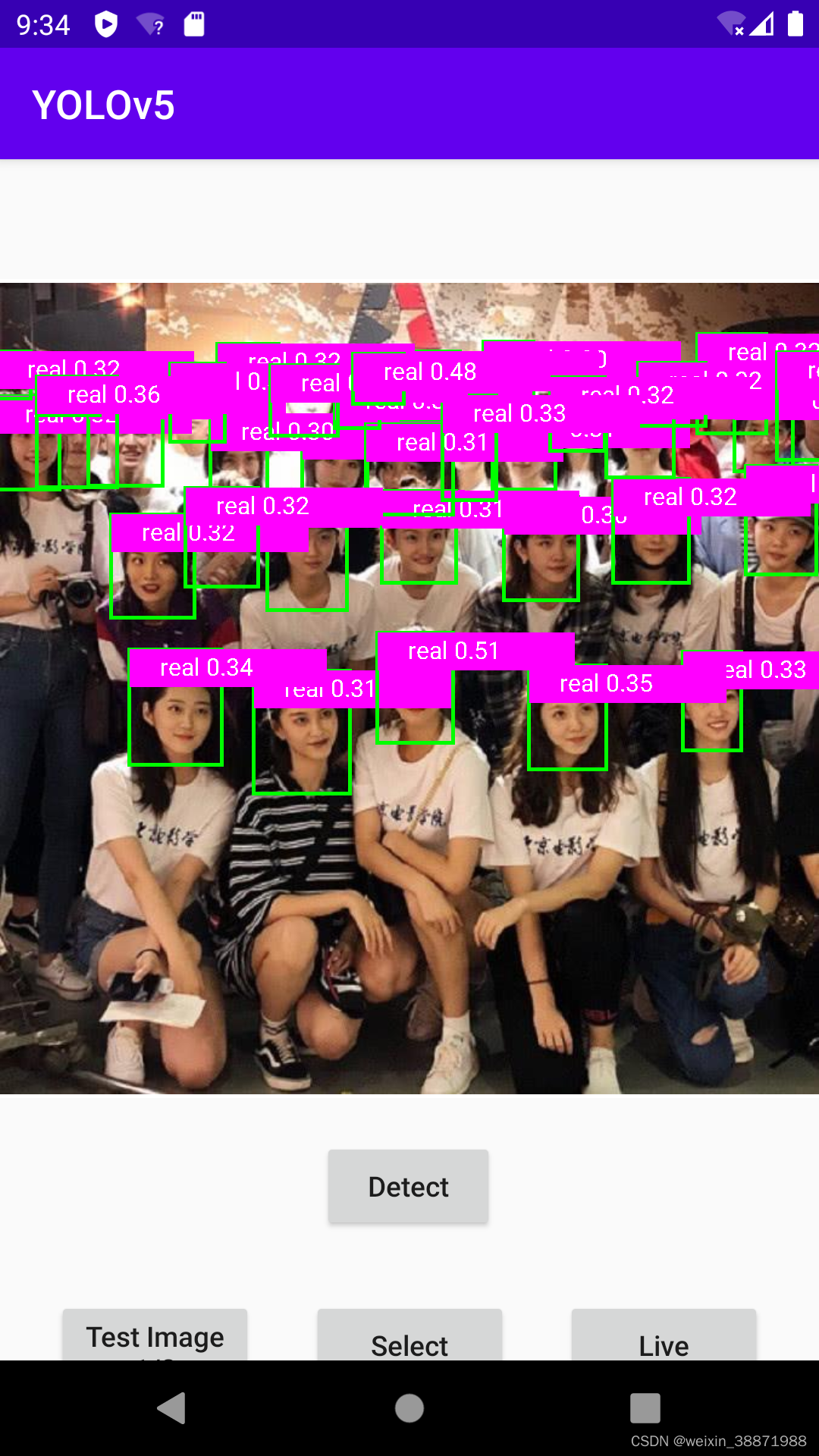
不放张图不足以慰风尘