赛题介绍
赛题名称:
基于文本字符的验证码识别竞赛
出题单位:
兴业银行股份有限公司
赛题背景:
验证码作为性价较高的安全验证方法,在多场合得到了广泛的应用,有效地防止了机器人进行身份欺骗,其中,以基于文本字符的静态验证码最为常见。随着使用的深入,噪声点、噪声线、重叠、形变等干扰手段层出不穷,不断提升安全防范级别。RPA技术作为企业数字化转型的关键,因为其部署的非侵入式备受企业青睐,验证码识别率不高往往限制了RPA技术的应用。一个能同时过滤多种干扰的验证码模型,对于相关自动化技术的拓展使用有着一定的商业价值。
赛题任务:
本次大赛以已标记字符信息的实例字符验证码图像数据为训练样本,参赛选手需基于提供的样本构建模型,对测试集中的字符验证码图像进行识别,提取有效的字符信息。训练数据集不局限于提供的数据,可以加入公开的数据集。
数据简介
此次比赛为选手提供15000张带标注信息的训练数据集,每张训练数据都是包含一个4位文本字符的验证码图像,并对当前图像中的文本字符进行了标注;测试数据集含25000张验证码图像。



吐槽
对于这场比赛,吐槽的人非常多!总结下来有以下几点:
1、A榜和B榜的数据分布差距较大,导致很多前排变后排。令无数高手竟折腰。
2、比赛意义不大这是场为了比赛而比赛的赛题。
解决方案
在竞赛群里看大佬的聊天得知,大家用的上分手段有:五折交叉验证、CutOut、CutMix、MixUp、生成数据等。模型一般用EfficientNetV1、V2。
在上分手段段我也采用了上面的一些手段,我的方案是:EfficientNetV1-B7+MixUp+CutOut。后期加入了CutMix,没有来得及测试效果。把验证码识别按照多标签分类去做。
解决方案参考github:https://github.com/zyf-xtu/captcha_ocr
训练得分:0.9854,由于测评已经关闭,没有办法得知在A榜的得分了。
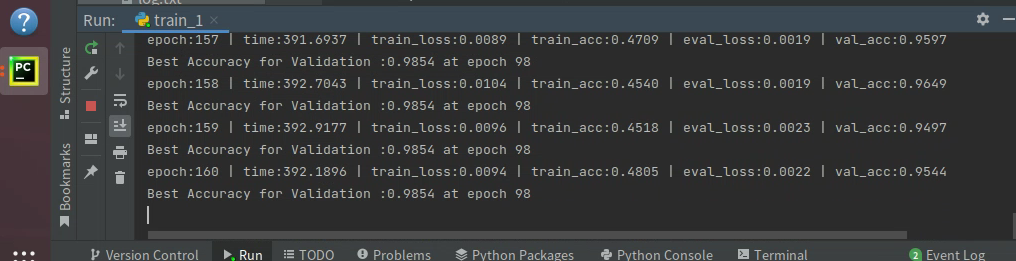
下面详细说一下我的方案。
数据
对数据部分的修改在captcha_dataset.py文件中。对geitem方法做了修改:
def __getitem__(self, index):
img_path, target = self.samples[index]
# #print('target', target)
# #print('random_t', random_t)
img = img_loader(img_path)
if np.random.random() > 0.5 and self.train_type==True:
img_arr = np.array(img)
index_arr=np.random.permutation(img_arr.shape[2])
img_arr=img_arr[:,:,index_arr]
img = Image.fromarray(img_arr.astype('uint8')).convert('RGB')
if np.random.random() > 0.5 and self.train_type==True:
img_random_path, random_t = self.samples[np.random.randint(0, len(self.samples))]
img_random = img_loader(img_random_path)
img_arr = np.array(img)
img_random_arr = np.array(img_random)
img_arr[:, 50:100, :] = img_random_arr[:, 50:100, :]
img = Image.fromarray(img_arr.astype('uint8')).convert('RGB')
target = target[:124] + random_t[124:]
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, torch.Tensor(target)
在这个方法里,我增加了两种数据增强,一种是对通道的随机,也就是RGB的随机;另一种是CutMix,将图片的前半部分和另一张图片的后半部分做拼接。然后Label也做相应的拼接。
训练
训练是最重要的部分,这些修改在train_1.py中,我把我修改的地方列举出来:
image_sizeh,image_sizew=240,600
将图片的Resize尺寸设置为240×600,放大了6倍。
数据增强我增加了CutOut:
Cutout使用到了torchtoolbox,如果没有torchtoolbox则需要安装:
pip install torchtoolbox
安装完成后导入:
from torchtoolbox.transform import Cutout
然后再transforms中调用。
# transform = [, transforms.GaussianBlur(21, 10)]
train_transform = transforms.Compose([
Cutout(),
transforms.Resize((image_sizeh, image_sizew)), # 图像放缩
transforms.RandomRotation((-5, 5)), # 随机旋转
# transforms.RandomVerticalFlip(p=0.2), # 随机旋转
transforms.ToTensor(), # 转化成张量
transforms.Normalize(
mean=train_mean,
std=train_std
)
])
加载数据部分我做了修改:
# 加载训练数据集,转化成标准格式
train_dataset = CaptchaData(train_paths,train_type=True, transform=train_transform)
# 加载验证集,转化成标准格式
val_dataset = CaptchaData(val_paths,train_type=False, transform=val_transform)
增加了train_type字段,判断是否是训练,如果是训练则做数据增强,如果不是则不作数据增强。
# 如果是多个gpu,数据并行训练
device_ids = [0, 1]
model = torch.nn.DataParallel(model, device_ids=device_ids)
增加多GPU并行,我本地的环境有两块3090,所以device_ids设置为0、1。
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
对学习率的调整,我用余弦退火。学习率初始值为1e-3,最小设置为1e-6。
inputs, labels_a, labels_b, lam = mixup_data(inputs, labels, 0.2)
# 预测输出
outputs = model(inputs)
# 计算MixUp loss
loss = mixup_criterion(loss_func, outputs, labels_a, labels_b, lam)
增加mixup,mixup提分还是比较明显的。
本次比赛另一位大佬也做了开源,github地址:https://github.com/xiaoxiaokuaile/2022DCIC_OCR
总结
这次比赛虽然不完美,但是在比赛中学到了不少的知识,我觉得这才是最重要的。
完整的代码:https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/85050647