- ����:Prioritized Experience Replay
- ��������:Curriculum Offline Imitating Learning
- ����:ICLR 2016
- ����:ǿ��ѧϰ ���� Replay Buffer
- ժҪ:�����ط����� online RL agent ��ס�����ù�ȥ�ľ��顣��֮ǰ�Ĺ�����,���� transition �Ǵ� replay buffer ��ͳһȡ���ġ�Ȼ��,���ַ���ֻ���� agent ʵ��ִ�� transition ����ͬƵ���ط���Щ transition,����������Ҫ����Ρ��ڱ�����,���ǿ�����һ�������ȴ����طž��� transition �Ŀ��,�Ա��Ƶ�����ط���Ҫ�� transition,�Ӷ�����Ч��ѧϰ�����ǽ����Ⱦ����ط��� DQN ����,������ Atari ��Ϸ��ʵ��������ˮƽ������,��������µ� SOTA,��49����Ϸ����41���ı�������ʹ�þ��Ⱦ����طŵ� DQN
1. Replay Buffer ����
- �����㷨ϸ��,�������� RL �㷨����������������

- �����ռ�(for predict):agent �뻷������,�ռ� episode/transition ����
- ѧϰ����(for control):�����ռ����������²���,����� return
1.1 On-policy ������
-
����� RL �㷨ͬʱ����������,���ǵõ��� on-policy �㷨���,�� agent �뻷����������Ϊ���Ժ�����ѧ���IJ�������ͬ��,������ʾ

������˵,���� on-policy ���� sarsa ��������ͼ����

-
ͬʱ��������,��Ҫͬʱ������ֵ�������ٵ����ȷ����Ͳ��Ը������ٵ�̽����������,��ᵼ�¼�������
ѵ�����ȶ�:Ҫ���õع��Ƽ�ֵ����,��Ҫ���εط������� s s s �� ( s , a ) (s,a) (s,a),��� agent ���ò��ѻ���̽����ϵ��������,����ʹ�� �� \varepsilon ��-greedy ����,�ⲻ�������˲��ȶ�����,����ֱ�ӵõ����Ų��ԡ�����Ҫ����,on-policy �㷨��̽����ֱ�ӽ��������ֵ�����ϵ�,����ֵ����������̽������,����ѭ������,��ᵼ�¸�ǿ�ķ���Ѱ����Ϊ(����ij״̬λ�ü�ֵ���Ƹ���,�ͻ��һ����������̽�⸽����λ��,�е�����������ζ),ʹ��ѵ�����ȶ����������ǿ:��������ʹ�ù켣�������� transition ��Ϊѵ������,��������������Ǻ�ǿ��(�����������Ϸ,������֡����֮��dz�����),��Υ���˻���ѧϰ������ i.i.d ԭ��,�����ݶ��½�ʱ,���һ��ʱ���ڵ��ݶȷ�����������,�ᵼ�¸��������������ʵ�:on-policy Ҫ�����ʹ�õ�����Ϊ���Բɼ��� transition ���²���,��˹�ȥ�ľ��� transition ������,����������һ�ξ��ӵ���,��Щ��ǰ����Ҫ��������Ҫ�� transition �������������,�����˷�����
1.2 Off-policy �� replay buffer
-
���� on-policy �㷨������������,��������� off-policy ���,�������ռ��Ͳ������������������ֱ���,�������������
��Ϊ����behavior policy�� b \pi_b ��b?:ר�Ÿ��� transition ���ݵĻ�ȡ,�������������������εز������� s s s �� ( s , a ) (s,a) (s,a)Ŀ�����target policy�� t \pi_t ��t?:������Ϊ�����ռ����������Լ�������������������������,�����ճ�Ϊ���Ų���
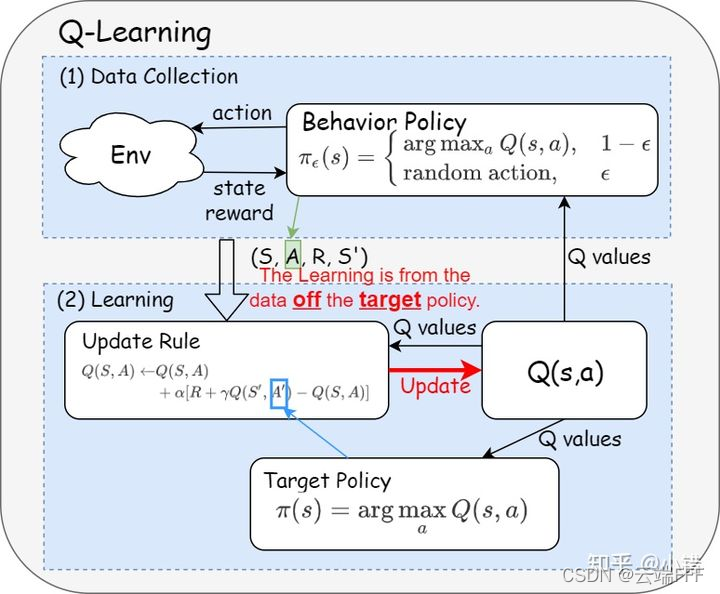
������˵,����� off-policy ���� Q-learning ʹ�� �� \varepsilon ��-greedy ��Ϊ��Ϊ����,ʹ�� greedy ��ΪĿ�����,��������ͼ����
-
Ϊ�˸�Ч�ؽ���̽��,��Ϊ����ͨ��������Ҫ�������Ƽ�ֵ��ָ��,on-policy �еIJ��ȶ�(ѭ������)�����������ǿ�����������ʵ͵ȼ���������Ȼ������������Ϣ��,off-policy ��ܷdz����,���ǿ���ʹ�ø����ֶ��ռ� transition ����,������ҵ�һ�� �������ġ� ��Ϊ����,������Ϊ�㷨�ṩ����ʵ�����,��ô�㷨��Ч�ʽ���õ�����
-
һ����Ȼ���뷨��,���ǿ����ѹ�ȥ�ľ��� transition ������������,��������һ�ٻ���������������,��������ȥ transition �Ļ��ƾ��� replay buffer,��������ͼʾ����

-
DQN ���� Playing Atari with Deep Reinforcement Learning �״ν����ѧϰ�� Q-learning ���,�������� replay buffer ���ơ���α����������ʾ,��ɫ���ְѲ��� transition ���� replay buffer,��ɫ���ִ� replay buffer �����Ȳ��������¼�ֵ��ֵ�������

-
�����طſ����ø���ļ�����ڴ�������ѧϰ�������������,��ͨ���� agent �뻷���Ľ����ijɱ���
2. ���ķ���
2.1 ˼��:���طŸ� TD error �� transition
-
�� 1.2 ��α������ʾ,ԭʼ�� replay buffer ��������Ȳ��������µ�,����ʵ��,��ͬ transition ����Ҫ���Dz�ͬ��,�����Ƶ�����ط���Ҫ�� transition,��ô���ܽ�һ������ѧϰЧ����Ϊ����֤����뷨,���߽�����һ����ʵ��,������ʾ

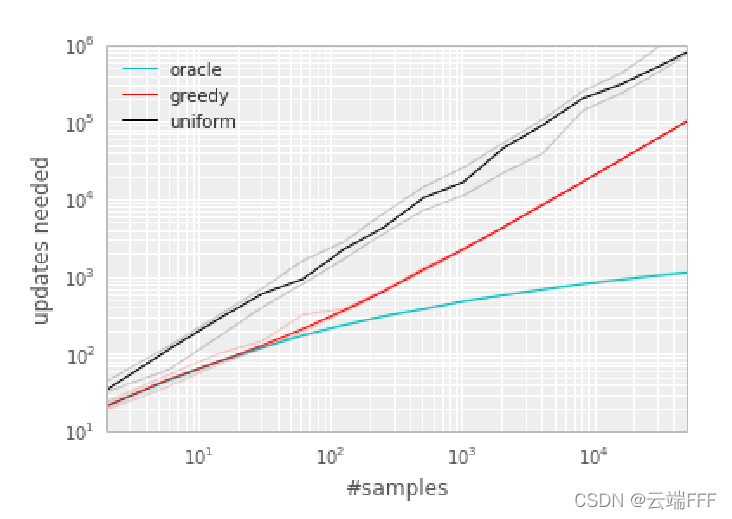
- ʵ�� MDP ����ͼ��ʾ,����һ��ϡ�轱������,agent �������������� n n n �����ܵõ�����(һ��������ж����л�ý����ļ����� 2 ? n 2^{?n} 2?n)�����������,�� reward ����ص� transition ����(���Ժ����ijɹ�)�����ڴ����߶�����Ĵ���������(����������������ڷ����������֮ǰ����ˤ��)
- ���߽� replay buffer ��ϵ� Q-leaning �㷨��,��һ�� agent ���ȵؽ��о����ط�,�ڶ��� agent ����һ�� oracle ��ȷ�� transition �����ȼ�(��� oracle ���ϵ��ӽ�,���ڲ������º�������� transition ����ȫ����ʧ�ij̶�)�����������˳��ִ�����п��е� 2 n 2^n 2n ���켣����� replay buffer
- ����ͨ���ı� n n n �Ĵ�С�õ�һϵ�в�ͬ�Ѷȵ�����,���� agent ѧϰֵ�������� learning step ����λ���Ա�����ͼ��ʾ,�ɼ���������ȼ��طſ���ָ�����ؼ���ѧϰ
-
���ȼ��طŵĺ������������ÿ�� transition ��Ҫ�Եı�
- ������ı��� agent ���Դӵ�ǰ״̬��ת����ѧϰ����(Ԥ��ѧϰ����,������ʵ���� oracle ������ֵ),�������ֵ��ֱ�Ӳ���
- һ��������������� transition �� TD error
��
\delta
�� �Ĵ�С,����� transition �ж� �����˾��ȡ� �� ���������ϡ�
�������������������� RL �㷨,�� SARSA �� Q-learning,��Ϊ�����Ѿ������ TD error �� \delta �� ,��������������²���
-
���߽�һ��ʵ����ʹ�� TD error ����ط����ȼ�����Ч��,ʵ�� MDP �� replay buffer ���ú�������ͬ,ʹ�� TD error ����ֵ �O �� �O |\delta| �O���O ��С��Ϊ���ȼ�,��̰�ĵ�ѡ�� �O �� �O |\delta| �O���O ���� transition �����طš�����δ�� transition,�ڼ��� replay buffer ʱ������Ϊ������ȼ�,�Ա�֤���� transition �����ټ���һ��,ʵ����������ʾ
�ɼ�,���� TD error ����ط����ȼ�,��Ȼ�����ϵ� Oracle,��Ҳ�����˲�С����������ע:���������ʵ���ж� Q ��ֵ�������ֹ۳�ʼ������ʹ�� TD error ��Ϊ�ط����ȼ�ʱ,���(���ֹ�)��ʼ���DZ�Ҫ��,��Ϊ�������ʼ��,���� reward �� transition ��� TD error �� = 0 \delta = 0 ��=0,����佫�������ڶ��еĵײ�,ֱ������ transition �ϵ� TD error ����������ֵ����(����������)����л��ᱻ�ط�
2.2 ���������
-
��Ҫ˵������,��ijЩ�����,̰�ĵذ��� TD error �����طſ�����һ���ܲ��ѡ��,������Ϊ TD error ֻ����������Ӧ�� ( s , a ) (s,a) (s,a) transition ʱ�Ż����,��¼������
- ���ij�� transition �ڵ�һ�η���ʱ TD error ��С,����� transition ���ѱ����������� replay buffer ʹ�û������ڸ���ʱ,����������Զ���ᱻ������
- ��������������,����������������Խ������ߺ����������,���ᱻ bootstrapping ���ƼӾ�
- ���� TD error ��Ҫ����ʱ��,����ζ��̰���㷨��Ƶ���طž����и� TD error ��һС���� transition,���� diversity ��ȱʧ�ᵼ�¹����(��һ���͵�һ�����)
-
Ϊ��,���DZ���Ҫ�ڻ��� TD error �ļ�̰���طŲ���������һЩ�����,���ұ�֤
- transition �����ȼ� p p p Ӧ���� TD error �� \delta �� �������,���ҹ��������ֵ �O �� �O |\delta| �O���O �ǵ�����
- transition �������ĸ��ʹ��������ȼ� p p p �ǵ�����
- ��ʹ�����ȼ���͵� transition,ҲҪ��һ���ĸ��ʱ��ط�
�����˵,��� i i i ���������ȼ�Ϊ p i > 0 p_i>0 pi?>0,���䱻�����ĸ���Ϊ
P ( i ) = p i �� �� k p k �� P(i) = \frac{p_i^\alpha}{\sum_k p_k^\alpha} P(i)=��k?pk��?pi��?? ���������� �� \alpha �� ���ƶ����ȼ�������̶�- �� �� = 0 \alpha=0 ��=0 ʱ,�˻�Ϊ���Ȳ���
- �� �� > 0 \alpha > 0 ��>0 ʱ,�� �� \alpha �� ָ�������������ȼ��ߵ� transition
-
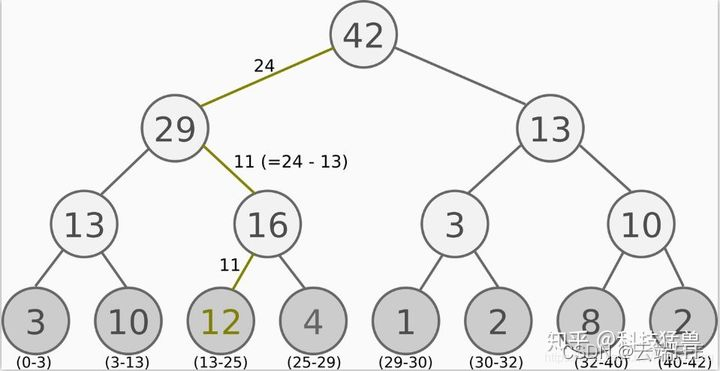
����ʵ����,����ʹ����һ�ֽ��� ��sum-tree�� �����ݽṹ����������ø������еļ��θ���ȥ����,�����ÿ�������� p i �� p_i^\alpha pi��? ����һ������,��ô������������ƴ��һ���� �� k p k �� \sum_k p_k^\alpha ��k?pk��? ������
- Ҫ����һ������,ֻ����������������ѡһ���㲢���������������Ӧ����������,��Ϊ�õ������ i i i ��������Ӧ����ĸ��ʾ��� P ( i ) = p i �� �� k p k �� P(i) = \frac{p_i^\alpha}{\sum_k p_k^\alpha} P(i)=��k?pk��?pi��??
- ���ڳ����� mini-batch ���,Ҫ���� k k k ������,�����Ȱ�������ȷָ�Ϊ k k k ��,Ȼ����ÿһ�������ѡһ����,ȡ�� k k k �������������Ӧ����������
��ͼ�� sum-tree �IJ���ʾ��(sum-tree ��ʵ����һ����,ÿ�����ڵ��С���������ӽڵ�ĺ�),��ϸ˵�����Բο� off-policyȫϵ��(DDPG-TD3-SAC-SAC-auto)+���Ⱦ���ط�PER-����-ʵ��������
-
�������ǽ�һ�������������ȼ� p i p_i pi? �����
2.2.1 ���ȼ�����һ:Proportional prioritization
- ��һ�������Ƚ�ֱ��,���� TD error �Ĵ�С����ֱ���������ȼ�,������˵����Ϊ
p i = �O �� i �O + ? p_i = |\delta_i| + \epsilon pi?=�O��i?�O+? ���� ? > 0 \epsilon>0 ?>0 ��һ��С����,��������Ϊ������ �� = 0 \delta=0 ��=0 ���²������� P ( i ) = 0 P(i)=0 P(i)=0 �ı߽��������,���е���������˹ƽ��ע:����Լ�ֵ���� 0 ��ʼ��,��ô �� = 0 \delta=0 ��=0 �� transition ��ѵ�������ر�,�����ϡ�轱��������������ˡ�
- ���ַ�����������Ϣ���϶�,���Է�ӳ������ transition TD error �ķֲ��ṹ,����³���Խϲ�,�����ܵ�����ֵӰ��
2.2.2 ���ȼ�������:Rank-based prioritization
- �ڶ��������Ǽ�ӵ�,���� TD error ����ֵ��С��������������ȼ�,������˵����Ϊ
p i = 1 rank(i) p_i = \frac{1}{\text{rank(i)}} pi?=rank(i)1? ���� rank(i) \text{rank(i)} rank(i) �� �O �� i �O |\delta_i| �O��i?�O �Ĵ�С����,�������ǵõ������ȼ��������ɷֲ�
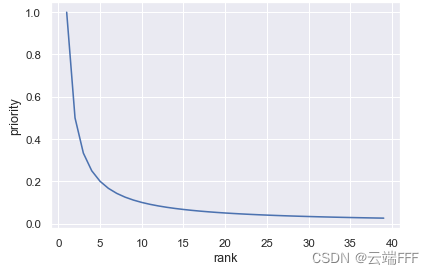
�������ɷֲ�������β����,�������Ա�֤����ʱ�Ķ����� - ���ַ�����������Ϣ������,����ӳ���� transition TD error �ķֲ��ṹ,����³���Խ�ǿ
2.3 ����ƫ��
- �Ǿ��Ȳ�����ı�ij������ �� \pi �� �յ��� ( s , a ) (s,a) (s,a) �ֲ�(����˵�ı��˲��Ե�ռ�ö���),��ᵼ��ѧϰ��ֵ����ʱ�ݶȷ������ƫ������Ѿ����طſ�����Ϊ���Ե�һ���ֿ��ܸ�������һ��,��ʹ��IJ��� �� \pi �� �ǹ̶���,ʹ�ò�ͬ�ľ����ط�Ҳ�ᵼ�²�ͬ����Ϊ����,����ʹ�ü�ֵ������������ͬλ��
2.3.1 ����ƫ���ԭ��
- ������һ���Ƚ�����˼������,PER ����Ϊ DQN ϵ�з�����һ���Ľ����ɱ����,�� DQN �� Q-learning �����ѧϰ�Ľ��,��һϵ�� off-policy ������,Ϊ�� Q-learning �� DQN ������Ҫ����ƫ����? Ҫ֪�� off-policy �� MC ��������Ҫ����Ҫ�Բ�����ȥ����ƫ���
-
���� Q-learning ����,��ʹ�� Bellman optimal equation ��Ϊ���¹�ʽ,����ʹ�����ż�ֵ����,�� Bellman һ��������������һ���������ʽ��ʾ,�������������ض��IJ������ӹ�ʽ�Ͽ�, Q-learning ��ѧϰĿ������
Q ? ( s , a ) = max ? E �� ? [ G t �O S t = s , A t = a ] = max ? E �� ? [ R t + 1 + �� G t + 1 �O S t = s , A t = a ] = E [ R t + 1 + �� max ? a �� Q ? ( S t + 1 , a �� ) �O S t = s , A t = a ] = �� s �� , r p ( s �� , r �O s , a ) [ r + �� max ? a �� Q ? ( s �� , a �� ) ] \begin{aligned} Q_*(s,a) &= \max\mathbb{E}_{\pi_*}[G_t|S_t=s,A_t=a] \\ &= \max \mathbb{E}_{\pi_*}[R_{t+1}+\gamma G_{t+1}|S_t=s,A_t=a] \\ &= \mathbb{E}[R_{t+1}+\gamma \max_{a'}Q_*(S_{t+1},a')|S_t=s,A_t=a] \\ &= \sum_{s',r}p(s',r|s,a)[r+\gamma \max_{a'}Q_*(s',a')] \end{aligned} Q??(s,a)?=maxE��???[Gt?�OSt?=s,At?=a]=maxE��???[Rt+1?+��Gt+1?�OSt?=s,At?=a]=E[Rt+1?+��a��max?Q??(St+1?,a��)�OSt?=s,At?=a]=s��,r��?p(s��,r�Os,a)[r+��a��max?Q??(s��,a��)]? ��ʽ�Ҳ������ֻ��״̬ת�Ʒֲ��йض��������,����ѵ�� transition �������ĸ�����,���� Q-learning �ĸ���ʽ���¶���ʹ Q Q Q �����ӽ� Q ? Q^* Q?,����Ϊ Q-learning ��һ�������ͷ���,û�з�����,��һ�� ( s , a ) (s,a) (s,a) �ļ�ֵ������ȫ����Ӱ�쵽���� ( s , a ) (s,a) (s,a) �ļ�ֵ����,�������ʹ��ʲô��Ϊ����ȥ�ռ� transition,����������ƫ��,Ҳ�Ͳ���Ҫ��Ҫ�Բ���������,��ͬ��Ϊ���Ե��µļ�ֵ�������̻��Dz�һ����,��Ϊ���Ը�Ƶ������ transition �ļ�ֵ���������,������ transition ������������ʱ,�������������� ( s , a ) (s,a) (s,a) ����Ϊ�������ջ�ѧ��һ���ļ�ֵ���� Q Q Q��ͺ������ò����һ�ѱ����ﵹˮ,��һ�����ӵ�ˮ��������������ӡ���Ϊ����ָ��������Щ���ӵ�,��Ƶ�����ʵı��Ӹ���װ��ˮ(��ֵ����),������б��ӱ����ʵĸ��ʶ����� 0,��ʱ����������ʱ����ʹ���б���װ��ˮ(��ֵȫ����������ͬλ��)
-
��������������Ƽ�ֵʱ,�����䷺����,���������ͬ�������� DQN ϵ�з�������,��ʹ�� L 2 L_2 L2? ��ʧ�����Ż���������ݶ��½��Ļ�,�� i i i �ֵ�����ʧ����Ϊ
L i = E s , a �� �� ( ? ) [ ( y i ? Q ( s , a , �� i ) 2 ) ] \mathcal{L_i} = \mathbb{E}_{s,a\sim\rho(��)}\big[(y_i-Q(s,a,\theta_i)^2)\big] Li?=Es,a����(?)?[(yi??Q(s,a,��i?)2)] ���� �� \rho �� ����Ϊ�����յ��� ( s , a ) (s,a) (s,a) �ֲ�, y i y_i yi? �� TD target y i = E s �� �� env [ r + �� max ? a �� Q ( s �� , a �� , �� i ? 1 ) �O s , a ] y_i = \mathbb{E}_{s'\sim \text{env}}\big[r+\gamma\max_{a'}Q(s',a',\theta_{i-1})|s,a\big] yi?=Es����env?[r+��a��max?Q(s��,a��,��i?1?)�Os,a] ��ʧ�����ݶ�Ϊ
�� �� i L i = E s , a �� �� ( ? ) , s �� �� env [ ( r + �� max ? a �� Q ( s �� , a �� , �� i ? 1 ) ? Q ( s , a , �� i ) ) �� �� i Q ( s , a , �� i ) ] \triangledown_{\theta_i}\mathcal{L}_i = \mathbb{E}_{s,a\sim\rho(��),s'\sim \text{env}}\big[\big(r+\gamma\max_{a'}Q(s',a',\theta_{i-1})-Q(s,a,\theta_i)\big)\triangledown_{\theta_i} Q(s,a,\theta_i)\big] ����i??Li?=Es,a����(?),s����env?[(r+��a��max?Q(s��,a��,��i?1?)?Q(s,a,��i?))����i??Q(s,a,��i?)] ��Ȼ������Ȼ�ǻ��� Bellman optimal equation ��������,����Ҫע��ݶ������� �� \rho �� ���ܵ���Ϊ����Ӱ�����Ȿ����������������ķ����Ե��µ�,��������ݶȸ��»�Ӱ�쵽���� ( s , a ) (s,a) (s,a) �ļ�ֵ,�����ݶȷ������� mini-batch �е� transition ����,��Щ�����IJɼ����ܵ���Ϊ����Ӱ��,���Dz�ͬ����Ϊ���Ծͻᵼ�¼�ֵ������������ͬλ����ͺ�������ˮͰ��һ�ѱ�����ˮ,��һ���ط���ˮ,���б��Ӷ��ὦ��,ˮ����������������Ϊ����ָ��������Щ��ˮ,��ʱ��Ϊ���Ե�һ�������,���ᵼ�¸����������յ�ˮ����ͬ
������Ƕȷ���,�� replay buffer ʹ�þ��Ȳ���ʱ,����Ϊ����Ӱ�첻����,������Ҫ����ƫ��(replay transition �ķֲ��ǽ�����Ϊ�����յ� ( s , a ) (s,a) (s,a) �ֲ���ƽ���ֲ�)
��ʵ��,DQN ��ԭʼ������ȫû���ᵽ��������ƫ�������,����Ϊ������ʵ���ǻ���һ��ƫ���,��Ϊ online RL ����Ϊ�����ڲ��ϱ仯,replay buffer �е� transition �Ͼ��������ԱȽ��ϵIJ���
�� -
���� DQN ϵ�з����м��� RER ʱ,��ʱ����ȥ���¼�ֵ����� ( s , a ) (s,a) (s,a) �ֲ�����Ϊ�����յ��� ( s , a ) (s,a) (s,a) �ֲ����кܴ�������,���������緺���Ե�Ӱ��,��ֵ����ƫ��ͻ��úܴ���(��ֵ��������ϵ�Ƶ�������طŵ� transition ��),��˱�������Ҫ�Բ���
-
2.3.2 ����ƫ��
-
Ϊ��ʹ��ֵ������������ͬ�Ľ��,����Ҫ�Բ���,ʹ��ϵ�� w ( i ) w(i) w(i) �����ڵ� i i i �� transition ��������ʧ,��
L PER = w ( i ) L ( �� ( i ) ) \mathcal{L}_{\text{PER}} = w(i)\mathcal{L}(\delta(i)) LPER?=w(i)L(��(i)) �����ϵ��ʹ����Ҫ�Բ���Ȩ��(importance sampling weights),����Ϊ
w i = ( 1 N ? 1 p ( i ) ) �� w_i = (\frac{1}{N}��\frac{1}{p(i)})^\beta wi?=(N1??p(i)1?)�� ���� N N N �� replay buffer �е�������,�� �� = 1 \beta=1 ��=1 ʱ�˻�Ϊ���Ȳ���(���ǻ������طŸ� TD error �� transition,����Щ transition ��Ӱ���ݶȵIJ�����С,�����ݶȺ;��Ȳ����ط�ʱ���)���ڵ��͵�ǿ��ѧϰ������,���ڲ��ԡ�״̬�ֲ�������Ŀ��ı仯,�ݶȸ��µ���ƫ����ѵ������ʱ�ӽ�����ʱ��Ϊ��Ҫ,��Ϊ����������ζ��Ǹ߶ȷ�ƽ�ȵ�,���Զ� �� \beta �� �����˻���,�� �� 0 < 1 \beta_0<1 ��0?<1 �������ӵ� 1 1 1�������Ҫ�Բ�����������ȫ���� distribution shift,��Ϊ�ݶ��½���Ӱ�������ƻ���������,���� �� < 1 \beta<1 ��<1 ʱ��ɵ�Ӱ���Ի���ڡ�������ѵ����������˻�,Ȼ���ھ����طŵ�����¼���ѵ���ϳ�ʱ��,�Ի�������Ӱ�졣��������Ҳ������ʹ �� \beta �� ����� 1 �����,ͬ��ȡ������������
���,Ϊ�������ȶ���,ͨ���������ֵ�� w ( i ) w(i) w(i) ѹ���� ( 0 , 1 ] (0,1] (0,1] ֮��,��
w ( i ) = w i max ? j w j w(i) = \frac{w_i}{\max_j w_j} w(i)=maxj?wj?wi?? -
�������л����������������һ���ŵ�,TD error �O �� ( i ) �O |\delta(i)| �O��(i)�O �ߵ� transition,����ʧ�ݶ�Ҳ�Ƚϴ�,ͨ����Ҫ�Բ���Ȩ�ؿ��Լ�С�����ݶ�,���е��൱������Ӧ�ص���ѧϰ��,ʹ�㷨�ܸ��õظ��ٸ߶ȷ����Եĺ�������
2.4 ���
- ���߰� PER �� DDQN ����,α��������

- һ��Ҫע��ĵ���,���ڳ��μ����� transition,�ڼ��� replay buffer ʱҪ�������ȼ���Ϊ���,�Ա�֤���ٱ�����һ��
3. ʵ��
- ������ 49 �� Atari ��Ϸ�����Ϻ�ʹ�þ��Ȳ����طŵ� DQN �� DDQN �����˶Ա�ʵ��,ģ�������� PER DDQN �;��� DDQN ��ȫһ��,ֻ�Dz�����ʽ�ı���,�������� PER �����ѡ��� �O �� �O |\delta| �O���O transition,���� �� \eta �� ��С���ı�
- ������ѡ����,���߽����˼���������,�������
- Rank-based prioritization: �� = 0.7 , �� = 0.5 \alpha=0.7,\beta=0.5 ��=0.7,��=0.5
- Proportional prioritization: �� = 0.6 , �� = 0.4 \alpha=0.6,\beta=0.4 ��=0.6,��=0.4
- ʵ�������,���ߴ�����켣�в����켣���(as introduced in Nair et al., 2015 and used in van Hasselt et al., 2016),���ַ�ʽҪ�� agent ���и�ǿ��³���Ժͷ�������,��Ϊ�䲻���������ظ�ij����ס�Ĺ켣
3.1 ���ܶԱ�
- 49 ����Ϸƽ����������
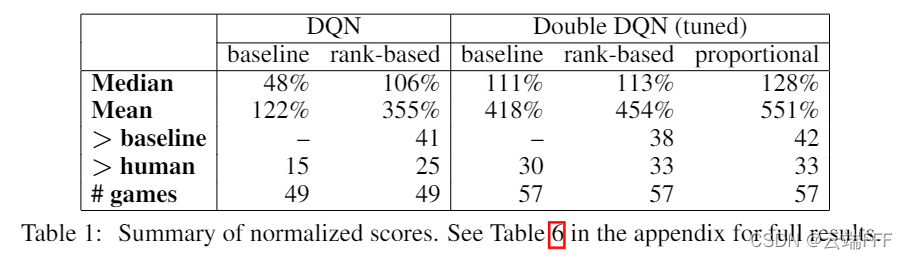
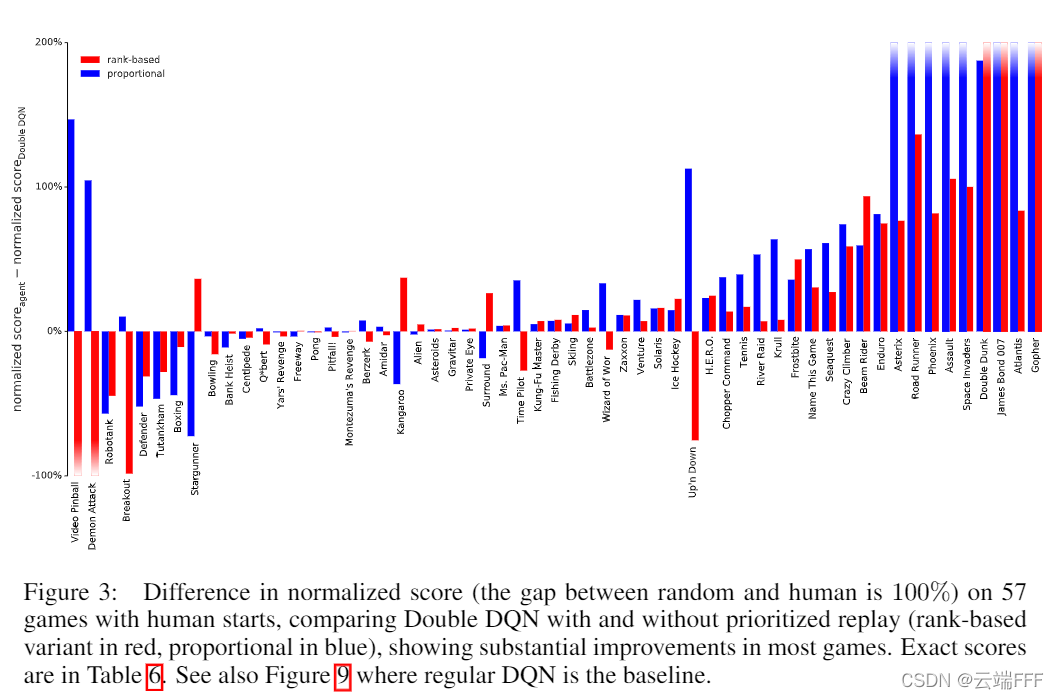
- 49 ����Ϸ���� 41 �������ܵõ�����(ֻҪ��һ�����ȼ��������������ܾ���)�����Թ۲쵽
- ��Ȼ�������ȼ�����ı���ͨ����������ƵĽ��,������Щ��Ϸ��,����һ����Ȼ�ӽ� DDQN Baseline,����һ�ֻ�����ܴ������
- PER ���������������� DDQN ���������������ǻ�����
3.2 ѧϰ�ٶȶԱ�
- ͨ��ѧϰ�������۲�ѧϰ�ٶ�
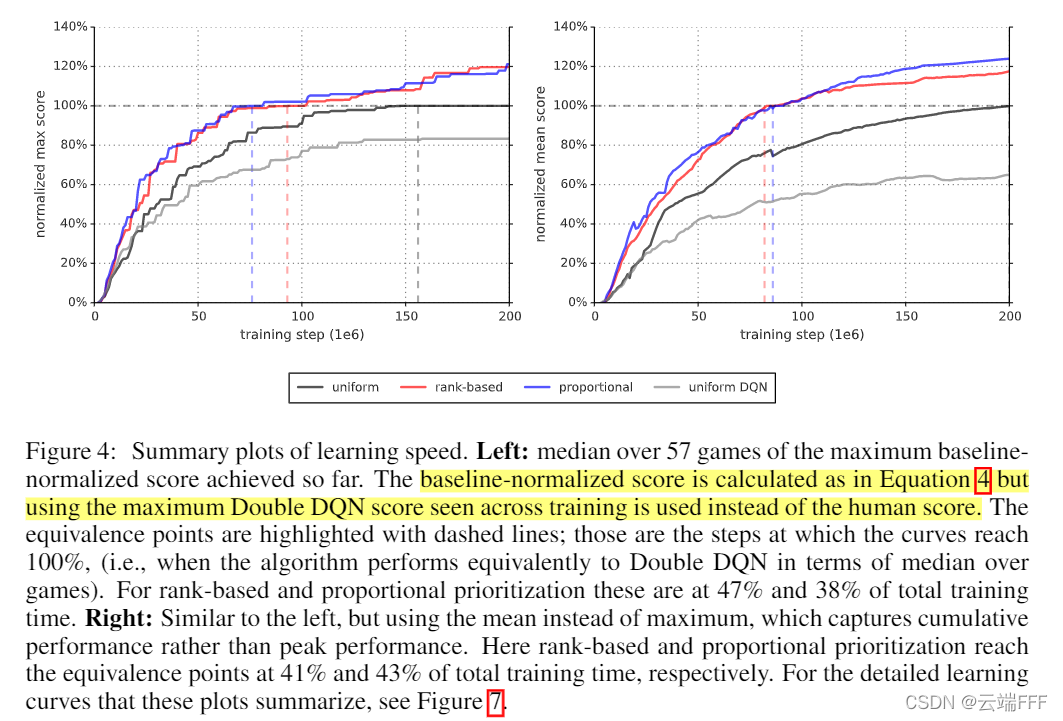
���߷���ʹ�� PER ���Խ�ƽ��ѧϰ�ٶ���������,��һ���۲첻ͬ��Ϸ��ѧϰ����,��������Ȳ����طŵ� Baseline ���,�� Battlezone, Zaxxon �� Frostbite ���ܵ��ӳ�Ӱ�����Ϸ��,���ȼ��طſ�����Ч��������������ǰ��äĿʱ��
3.3 ��ȫ����ƫ��
- �� 2.3.2 �����Ƿ�����,���߶Գ�����
��
\beta
�� ���õ��˻���Ի��ڼ�ֵ����������ݶȷ���������ƫ��,���߲���������趨
��
\beta
�� ����� 1(����ȫ����ƫ��)��Ч��

- ���������,��ȫ���� PER �� Baseline �IJ���
��
\eta
�� ��ͬ,����ȫ���� PER �IJ���Ϊ��
1
4
\frac{1}{4}
41?�����߷���
- �벻��ȫ���� PER ���,��ȫ���� PER ʹѧϰ����ô����,һ���浼�³�ʼѧϰ����,����һ���浼�¹��������ķ��ս�С,��ʱ���ս������
- ������ط����,��ȫ���� PER ƽ�����ܸ���
4. ����
-
�����������ȼ�����,���߲���
- rank-based ��������Ƚ�,��Ϊ�������쳣ֵ������С��Ӱ��,��β���Ա�֤�������Ķ�����,�������Բ�ͬ�������ķֲ����,��������ѵ�������б����ܵ� mini-batch �ݶȱȽ��ȶ�
- ��һ����,rank-based ������������� TD error �ij߶�,��Ҫ���õ� TD error �ķֲ��ṹʱ,����ܻᵼ�������½�,����ϡ�轱������
ʵ�鷢�����ֱ�����ʵ���б�������,������������Ϊ�� DQN �㷨�д���ʹ���� clipping ����(�� reward �� TD error �ü���һ��С������),���ȥ���쳣ֵ,���� Proportional prioritization �����ܵ�̫��Ӱ��
-
���߹۲��� TD error �ֲ���ʱ��ı仯���,����

�����ߵ���ɫ��ʾ�����Ӧ��ʱ��(��ɫ�ǿ�ʼʱ��,��ɫ�ǽ���ʱ��),���߷������۾��Ȳ����طŻ��� PER,����ʹ TD error �ֲ��ӽ���β��ʽ,���� PER ������������,��Ӿ�������֤�� PER ��ʽ P ( i ) = p i �� �� k p k �� P(i) = \frac{p_i^\alpha}{\sum_k p_k^\alpha} P(i)=��k?pk��?pi��?? ����ʽ -
������һ�������ľ��Ȳ����طź� PER ������
- ���Ȳ����طŵ� transition �ڼ��� replay buffer ʱû�и������������ȶ�,����طŵĺܶྭ�鶼�ǹ�ʱ��,������Щ transition �Ӷ����طŹ�,PER ���������һ��
- ���߰����������Ķ���(ѧϰ transition �ı�ʾ)��ײ�(���Ƽ�ֵ����)���ֿ���,��ʾ���õ� transition ��Ѹ�ټ��� TD error,Ȼ���طŵĴ�������,�Ӷ����ӶԱ�ʾ�ϲ������ transition ��ѧϰ
-
��������������һЩ��չ̽��,��ο�ԭ��