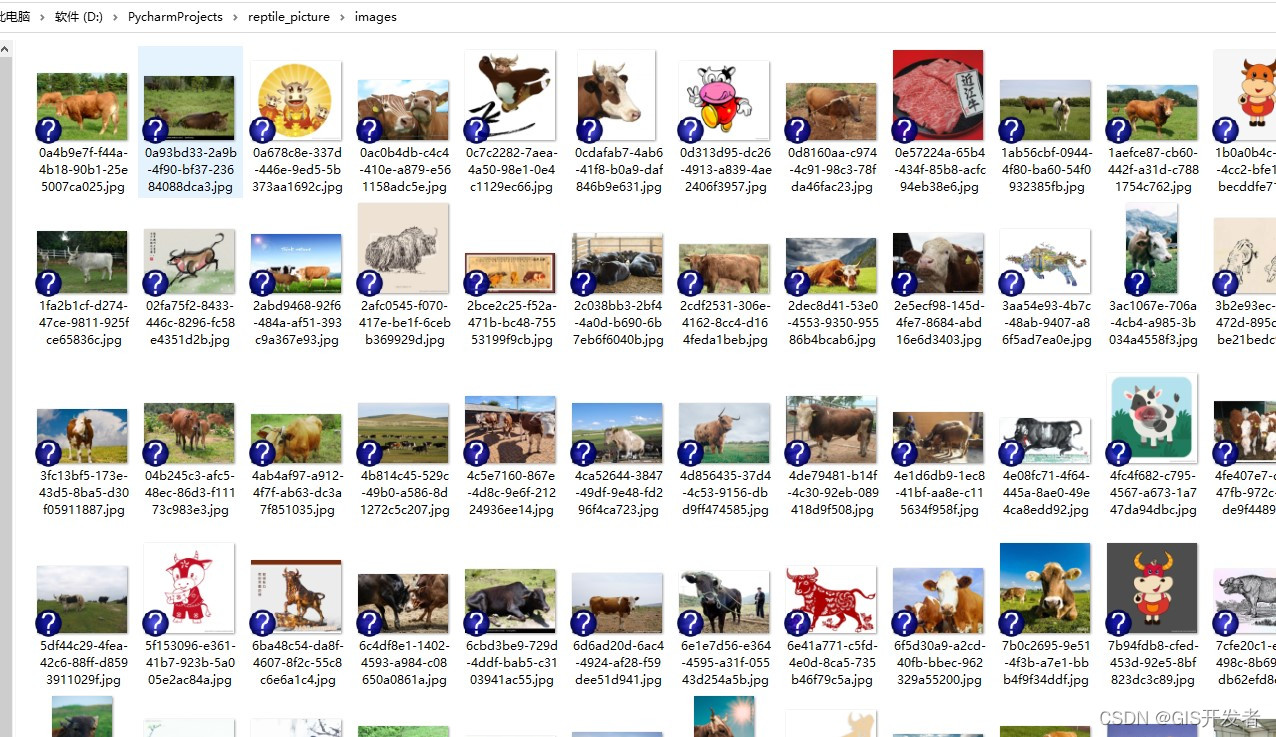
在工作中,我们经常遇到需要大量图片的场景。尤其是机器学习方向,需要大量的图片作为样本进行训练。这里用python+scrapy实现一个从百度图片爬取图片的工具。经实际测试,效率非常快。以前没有使用过scrapy框架,查阅一下资料,发现,使用起来真的非常简单。
安装scrapy:
我的运行环境是python3.9,全局安装下面的工具
- 安装wheel支持:
pip3 install wheel
- 安装scrapy框架:
pip install scrapy
pip3 install pillow # 图片爬虫时必须安装,否则图片不会下载
创建项目
通过下面命令可以创建一个爬虫的模版项目
scrapy startproject reptile_picture
创建爬虫模版
通过下面命令可以创建一个爬虫内容的模版
scrapy genspider -t basic book image.baidu.com
百度图片规则分析
直接爬取百度图片的html网页是无效的,因为里面的图片内容都是通过动态请求和加载出来的。可以直接爬取百度图片的查询接口的策略。通过浏览器的控制台可以分析出接口请求的规律。这里我就不详细的叙述了,有兴趣的可以点浏览一下百度图片的页面,自己对比一下控制台发出的请求。
代码编写
book.py
import scrapy
import time
import re
from ..items import ReptilePictureItem
def translate(num):
# 10进制转16进制字符串
num = str(hex(num))
return num.replace("0x", "", 1)
def get_timestamp():
# 获取当前时间戳字符串
t = time.time()
return str(int(round(t * 1000)))
class BookSpider(scrapy.Spider):
# 爬虫名
name = 'book'
# 爬虫允许的爬取域名范围,最好根据你所要爬取的网站来确定,不能乱写,否则会搜索不到内容,使爬虫不受控制
allowed_domains = ['image.baidu.com']
# 构建url的起始值offset,具体由网页分析后确定
offset = 30
current_offset = 30
max_times = 300 # 测试时使用,限制最大爬取次数
# 此处url的'https://'一定要写,不然会报错,而且不容易找出
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8605576373647774920&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E5%AD%99%E5%85%81%E7%8F%A0&queryWord=%E5%AD%99%E5%85%81%E7%8F%A0&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={}&rn=30&gsm={}&{}='
# 起始url,列表内字符串的拼接
start_urls = [url.format(str(current_offset), translate(current_offset), get_timestamp())]
def parse(self, response):
# 使用scrapy shell 返回的内容为json格式,正则匹配出图片链接并提取
pattern = re.compile(r'"middleURL":"(.*?)",', re.S)
# 此datas返回的是一个正则表达式列表,可迭代取出里面的url
datas = re.findall(pattern, response.text)
for data in datas:
# 实例化item
item = ReptilePictureItem()
# print("图片链接是:", data)
item['imageLink'] = data
# 生成器,返回给pipelineItem文件
# 由一个url获取一个图片的url列表,列表内有若干个图片链接url,依次获取发送图片链接的url,直至发送完,跳出循环
yield item
# 跳出循环后offset自增30(网页决定)
self.current_offset = self.current_offset + self.offset
if self.current_offset > 300:
# 控制爬取次数,防止程序一直运行
return
# 调用此生成器,并发送下一个网页url,回调函数调用self.parse自身,再次循环处理列表中的图片链接url,循环往复获取图片
yield scrapy.Request(self.url.format(str(self.current_offset), translate(self.current_offset), get_timestamp()),
callback=self.parse)
items.py
import scrapy
class ReptilePictureItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
imageLink = scrapy.Field()
pass
pipelines.py
from scrapy.pipelines.images import ImagesPipeline
import scrapy
from scrapy.exceptions import DropItem
from scrapy.utils.project import get_project_settings
import uuid
class ReptilePicturePipeline(ImagesPipeline):
# 使用settings.py中的设置
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
# 此函数的第一个对象request就是当前下载对应的scrapy.Request对象,这个方法永汉返回保存的文件名,将图片链接的最后一部分党文文件名,确保不会重复
def file_path(self, request, response=None, info=None):
url = request.url
file_name = str(uuid.uuid4())
# 判断图片格式
if url.find("f=PNG") >= 0:
file_name = file_name + ".png"
else:
file_name = file_name + ".jpg"
return file_name
# 第一个item对象是爬取生成的Item对象,可以将他的url字段取出来,直接生成scrapy.Request对象,此Request加入到调度队列,等待被调度,然后执行下载
def get_media_requests(self, item, info):
image_url = item["imageLink"]
yield scrapy.Request(image_url)
# 这是单个Item完成下载时的处理方法,各种原因,并不是每张图片都会下载成功,此方法可以剔除下载失败的图片
# result是该Item对应的下载结果,是一个列表形式,列表每个元素是一个元组,其中包含了下载成功与失败的信息,这里遍历下载结果,找出所有下载成功的列表,如果列表为空,那么此Item对应的图片链接下载失败,随即跑出异常DropItem,该Item忽略,否则返回Item,该Item有效
def item_completed(self, result, item, info):
image_path = [x["path"] for ok, x in result if ok]
if not image_path:
raise DropItem('Image Dowload Failed')
return item
settings.py
BOT_NAME = 'reptile_picture'
SPIDER_MODULES = ['reptile_picture.spiders']
NEWSPIDER_MODULE = 'reptile_picture.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
ROBOTSTXT_OBEY = False
IMAGES_STORE = "./images"
ITEM_PIPELINES = {
'reptile_picture.pipelines.ReptilePicturePipeline': 300,
}
运行爬虫程序
scrapy crawl book
爬虫效果