记录写的第一个深度学习网络–pytorch做回归任务
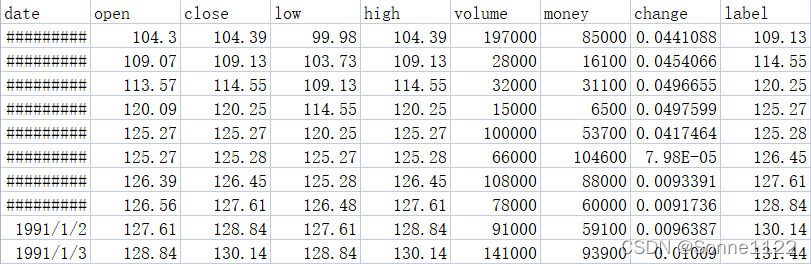
数据格式
用open-change7个变量预测label
代码
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
from sklearn import preprocessing
# 导入数据集
# 训练集和测试集导入数据
data = pd.read_csv(r'stock_train.csv',encoding='utf-8')
data_test1 = pd.read_csv(r'stock_test.csv',encoding='utf-8')
# 导入训练集因变量
y_train = np.array(data.label)
y_train = y_train.reshape(-1, 1)
y_train = preprocessing.StandardScaler().fit_transform(y_train)
# 导入训练集自变量
data_train = data.drop('label', axis = 1)
data_train = data_train.drop(columns = 'date', axis = 1)
x_train = np.array(data_train)
x_train = preprocessing.StandardScaler().fit_transform(x_train)
# 导入测试集因变量
y_test = np.array(data_test1.label)
y_test = y_test.reshape(-1, 1)
y_test = preprocessing.StandardScaler().fit_transform(y_test)
# 导入测试集自变量
data_test = data_test1.drop('label', axis = 1)
data_test = data_test.drop(columns = 'date', axis = 1)
x_test = np.array(data_test)
x_test = preprocessing.StandardScaler().fit_transform(x_test)
# 设置参数,有7个输入特征,一个含有128个神经元的隐藏层,因为是回归问题所以一个输出特征
input_size = 7
hidden_size = 128
output_size = 1
batch_size = 16
# 构建网络
model = torch.nn.Sequential(
# 7--》128
torch.nn.Linear(input_size, hidden_size),
# 激活函数
torch.nn.Sigmoid(),
# 128--》1
torch.nn.Linear(hidden_size, output_size)
)
# 定义损失函数,因为是回归均方误差采用MSE
cost = torch.nn.MSELoss()
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
losses = []
train_loss = []
# 定义迭代次数,尝试后发现迭代500次结果已经很好了
for i in range(500):
batch_loss = [] # 记录每一个batch的损失值
pre = []
for start in range(0, len(data_train), batch_size):
end = start + batch_size if start + batch_size < len(data_train) else len(data_train)
# 输入一个batch数据的自变量
xx = torch.tensor(x_train[start:end], dtype = torch.float, requires_grad = True)
# 输入一个batch数据的因变量
yy = torch.tensor(y_train[start:end], dtype = torch.float, requires_grad = True)
# 前向传播
prediction = model(xx)
# 计算损失值
loss = cost(prediction, yy)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward(retain_graph=True)
# 更新参数
optimizer.step()
batch_loss.append(loss.data.numpy())
train_loss=batch_loss # 记录最后一次迭代的损失值
print(np.mean(train_loss))
# 测试数据
x = torch.tensor(x_test, dtype = torch.float)
predict = model(x).data.numpy()
plt.plot(data_test1['date'], y_test, label = 'truth_ground')
plt.plot(data_test1['date'], predict, label = 'test_pre')
plt.legend()
plt.show()
# 验证数据
x = [210.34,211.86,209.71,211.97,32650000,22263100,0.008520969]
x = x.reshape(1, -1)
x = preprocessing.StandardScaler().fit_transform(x)
x_vertify = torch.tensor(x, dtype = torch.float)
predict = model(x_vertify).data.numpy()
print(predict)
一些记录
- x.reshape(1,-1)含义是将x改变成一行,任意列大小的数组,-1的含义是不用指定具体个数
- torch.nn.MSELoss() reduction = ‘none’则返回一组向量,reduction ≠ ‘none’则返回一个数,有sum和mean(默认)两种方法
- torch.nn.X和torch.nn.functional.X区别:前面的是类用之前需要实例化,后面的是函数直接调用