WaveNet取代了对音频信号使用傅里叶变换的传统方法。它通过令神经网络找出要执行的转换来实现。因此,转换可以反向传播,原始音频数据可以通过一些技术来处理,例如膨胀卷积、8位量化等。但是人们一直在研究将WaveNet方法与传统方法相结合的方式,尽管该方式将损失函数转换为多元回归的损失函数而不是WaveNet所使用的分类。
WaveNet的基本构建模块是膨胀卷积,它取代了RNN获取上下文信息的功能
下图展示了WaveNet在进行预测时如何提取有关上下文的信息。图片的底部是输入,这是原始音频样本。例如,一个16kHz的音频样本在一秒内有16 000个数据点,如果与自然语言的序列长度(每个单词将是一个数据点)相比,那么这个数量是巨大的。这些长序列是RNN处理原始音频样本不太有效的一个很大的原因。 下图是没有膨胀卷积的WaveNet图像。
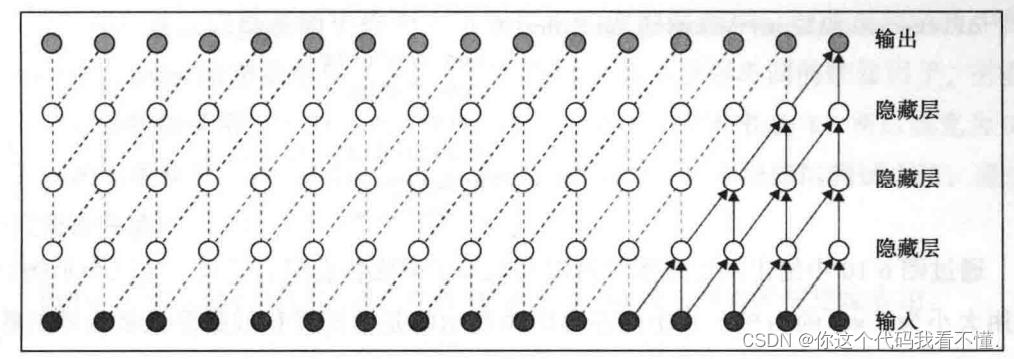
LSTM 网络可以记住实际序列长度为50~100的上下文信息。上图中具有三个隐藏层,这些隐藏层使用上一层的信息。第一层输入通过一维卷积层以生成第层的数据。卷积可以并行完成,这与RNN的场景不同。在 RNN中,每个数据点都需要前一个输人依次传入。为了收集更多上下文,我们可以增加层数。在上图中,位于第五层的输出将从输入层的五个节点获取上下文信息。因此,每一层将增加个输入节点到上下文中。也就是说,如果我们有10个隐藏层,则最后一层将从12个输入节点获取上下文信息。
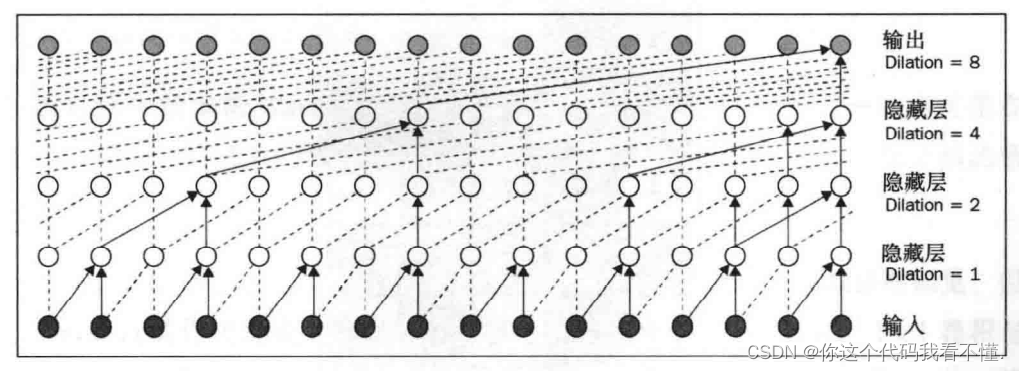
到目前为止,很明显,要实现LSTM 网络上下文容纳能力为50~100的实际限制,网络需要有98层,这在计算上是很昂贵的。这就是使用膨胀卷积的地方。为使用膨胀卷积,将为每一层设定一个膨胀因子,以指数形式增加该因子将以对数形式减少任何特定上下文窗口宽度所需的层数。
下展示了WaveNet中使用的膨胀卷积方案(尽管为了更好地理解膨胀卷积,我们在这里使用的是二维图片,但 WaveNet使用一维卷积)。尽管该实现忽略了中间参数的记录,但最终的节点仍通过这种巧妙的方案从上下文中的所有节点获取信息。基于膨胀卷积和3个隐藏层,先前的实现覆盖了16个输人节点,而没有膨胀卷积的实现仅覆盖了5个输入节点。
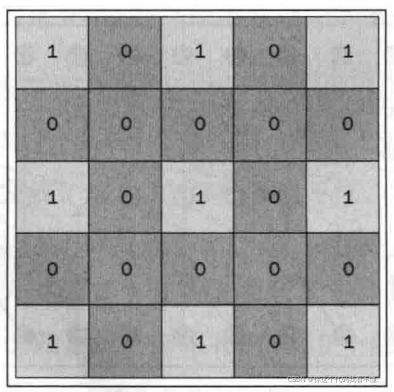
下图给出的二维图片可以直观地了解膨胀卷积的实现。这三个示例都使用大小为3×3的内核,其中最左边的块显示的是常规卷积或膨胀系数为零的膨胀卷积。中间的块使用相同的内核,但膨胀因子为2。最后一个块的膨胀因子为4。膨胀卷积的实现技巧是在内核之间添加零以扩展内核的大小,如第二张图所示。

WaveNet的完整架构建立在膨胀卷积网络和卷积后的门控激活的基础之上。WaveNet中的数据流从因果卷积运算(一种常规的一维卷积)开始,然后传递到膨胀卷积节点。第二张图中的每个白色圆圈都是一个膨胀卷积节点。然后,将常规卷积的数据点传递给膨胀卷积节点,然后将其分别通过sigmoid门和 tanh激活函数。接下来,两个运算的输出结果经过一个逐点乘法运算和一个1×1的卷积。WaveNet使用残差连接和跳跃连接对数据流进行平滑。与主流程并行的残差线程通过加法运算与1×1卷积的输出进行合并。
下面是WaveNet的网络结构。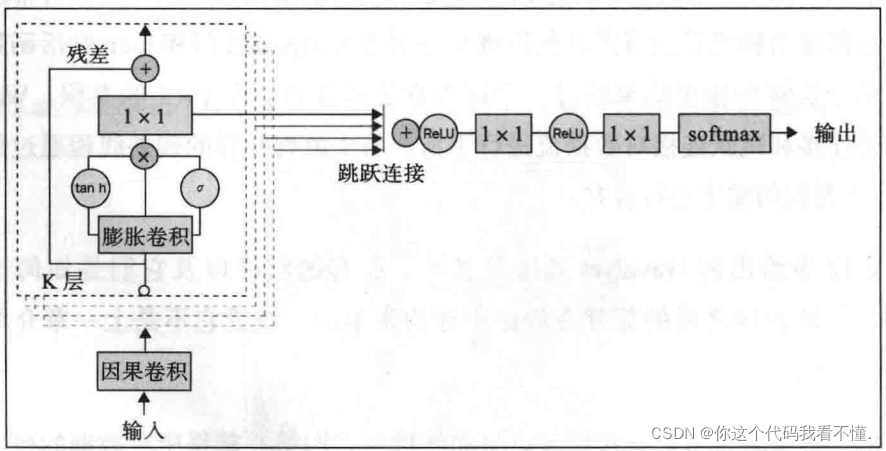
实现代码如下:
simple-generative-model-regressor.py
import os
import sys
import time
import numpy as np
from keras.callbacks import Callback
from scipy.io.wavfile import read, write
from keras.models import Model, Sequential
from keras.layers import Convolution1D, AtrousConvolution1D, Flatten, Dense, \
Input, Lambda, merge, Activation
def wavenetBlock(n_atrous_filters, atrous_filter_size, atrous_rate):
def f(input_):
residual = input_
tanh_out = AtrousConvolution1D(n_atrous_filters, atrous_filter_size,
atrous_rate=atrous_rate,
border_mode='same',
activation='tanh')(input_)
sigmoid_out = AtrousConvolution1D(n_atrous_filters, atrous_filter_size,
atrous_rate=atrous_rate,
border_mode='same',
activation='sigmoid')(input_)
merged = keras.layers.Multiply()([tanh_out, sigmoid_out])
skip_out = Convolution1D(1, 1, activation='relu', border_mode='same')(merged)
out = keras.layers.Add()([skip_out, residual])
return out, skip_out
return f
def get_basic_generative_model(input_size):
input_ = Input(shape=(input_size, 1))
A, B = wavenetBlock(64, 2, 2)(input_)
skip_connections = [B]
for i in range(20):
A, B = wavenetBlock(64, 2, 2**((i+2)%9))(A)
skip_connections.append(B)
net = keras.layers.Add()(skip_connections)
net = Activation('relu')(net)
net = Convolution1D(1, 1, activation='relu')(net)
net = Convolution1D(1, 1)(net)
net = Flatten()(net)
net = Dense(input_size, activation='softmax')(net)
model = Model(input=input_, output=net)
model.compile(loss='categorical_crossentropy', optimizer='sgd',
metrics=['accuracy'])
model.summary()
return model
def get_audio(filename):
sr, audio = read(filename)
audio = audio.astype(float)
audio = audio - audio.min()
audio = audio / (audio.max() - audio.min())
audio = (audio - 0.5) * 2
return sr, audio
def frame_generator(sr, audio, frame_size, frame_shift, minibatch_size=20):
audio_len = len(audio)
X = []
y = []
while 1:
for i in range(0, audio_len - frame_size - 1, frame_shift):
frame = audio[i:i+frame_size]
if len(frame) < frame_size:
break
if i + frame_size >= audio_len:
break
temp = audio[i + frame_size]
target_val = int((np.sign(temp) * (np.log(1 + 256*abs(temp)) / (
np.log(1+256))) + 1)/2.0 * 255)
X.append(frame.reshape(frame_size, 1))
y.append((np.eye(256)[target_val]))
if len(X) == minibatch_size:
yield np.array(X), np.array(y)
X = []
y = []
def get_audio_from_model(model, sr, duration, seed_audio):
print 'Generating audio...'
new_audio = np.zeros((sr * duration))
curr_sample_idx = 0
while curr_sample_idx < new_audio.shape[0]:
distribution = np.array(model.predict(seed_audio.reshape(1,
frame_size, 1)
), dtype=float).reshape(256)
distribution /= distribution.sum().astype(float)
predicted_val = np.random.choice(range(256), p=distribution)
ampl_val_8 = ((((predicted_val) / 255.0) - 0.5) * 2.0)
ampl_val_16 = (np.sign(ampl_val_8) * (1/256.0) * ((1 + 256.0)**abs(
ampl_val_8) - 1)) * 2**15
new_audio[curr_sample_idx] = ampl_val_16
seed_audio[:-1] = seed_audio[1:]
seed_audio[-1] = ampl_val_16
pc_str = str(round(100*curr_sample_idx/float(new_audio.shape[0]), 2))
sys.stdout.write('Percent complete: ' + pc_str + '\r')
sys.stdout.flush()
curr_sample_idx += 1
print 'Audio generated.'
return new_audio.astype(np.int16)
class SaveAudioCallback(Callback):
def __init__(self, ckpt_freq, sr, seed_audio):
super(SaveAudioCallback, self).__init__()
self.ckpt_freq = ckpt_freq
self.sr = sr
self.seed_audio = seed_audio
def on_epoch_end(self, epoch, logs={}):
if (epoch+1)%self.ckpt_freq==0:
ts = str(int(time.time()))
filepath = os.path.join('output/', 'ckpt_'+ts+'.wav')
audio = get_audio_from_model(self.model, self.sr, 0.5, self.seed_audio)
write(filepath, self.sr, audio)
if __name__ == '__main__':
n_epochs = 2000
frame_size = 2048
frame_shift = 128
sr_training, training_audio = get_audio('train.wav')
# training_audio = training_audio[:sr_training*1200]
sr_valid, valid_audio = get_audio('validate.wav')
# valid_audio = valid_audio[:sr_valid*60]
assert sr_training == sr_valid, "Training, validation samplerate mismatch"
n_training_examples = int((len(training_audio)-frame_size-1) / float(
frame_shift))
n_validation_examples = int((len(valid_audio)-frame_size-1) / float(
frame_shift))
model = get_basic_generative_model(frame_size)
print 'Total training examples:', n_training_examples
print 'Total validation examples:', n_validation_examples
audio_context = valid_audio[:frame_size]
save_audio_clbk = SaveAudioCallback(100, sr_training, audio_context)
validation_data_gen = frame_generator(sr_valid, valid_audio, frame_size, frame_shift)
training_data_gen = frame_generator(sr_training, training_audio, frame_size, frame_shift)
model.fit_generator(training_data_gen, samples_per_epoch=3000, nb_epoch=n_epochs, validation_data=validation_data_gen,nb_val_samples=500, verbose=1, callbacks=[save_audio_clbk])
print 'Saving model...'
str_timestamp = str(int(time.time()))
model.save('models/model_'+str_timestamp+'_'+str(n_epochs)+'.h5')
print 'Generating audio...'
new_audio = get_audio_from_model(model, sr_training, 2, audio_context)
outfilepath = 'output/generated_'+str_timestamp+'.wav'
print 'Writing generated audio to:', outfilepath
write(outfilepath, sr_training, new_audio)
print '\nDone!'
在linux下面创建train.wav等数据
cvlc -vvv --sout-keep --sout-all --sout "#gather:transcode{acodec=s16l,channels=1,samplerate=8000}:std{access=file,mux=wav,dst=validate.wav}" `find LibriSpeech/test-clean/ -name "*.flac"` vlc://quit
cvlc -vvv --sout-keep --sout-all --sout "#gather:transcode{acodec=s16l,channels=1,samplerate=8000}:std{access=file,mux=wav,dst=train.wav}" `find LibriSpeech/dev-clean/ -name "*.flac"` vlc://quit