����ѧϰCH6-֧��������
1-SVM���
֧��������(support vector machines, SVM):��һ�ֶ�����ģ��,���Ļ���ģ���Ƕ����������ռ��ϵ������������Է�����,������ʹ���б��ڸ�֪��;SVM�������˼���,��ʹ����Ϊʵ���ϵķ����Է�������SVM�ĵ�ѧϰ���Ծ��Ǽ�����,SVM�ĵ�ѧϰ�㷨����������ι滮�����Ż��㷨��
֧��������������һ�����п��ȵ��ߴ����������з��ࡣ
�����SVM:��������,�гͷ�
Ӳ���SVM:��������,
������SVM:����������,ʹ�ú˺�����ά����

2-SVM�㷨ԭ��-Ӳ���SVM
�Ӽ��νǶ���˵:�������Կɷֵ����ݼ�,֧�������������Ҿ�����������������Զ�ij�ƽ��,��ȸ�֪��,�����Ψһ��,�ҷ������ܸ��á�����ͼ��ʾ��

��ģ��ԭ��:�������Կɷֵ����ݼ�X,֧��������ϣ�����X���ڳ�ƽ��ļ��μ��r�ﵽ���ij�ƽ��,Ȼ������sign����ʵ�ַ��ࡣ
y
=
s
i
g
n
(
W
T
X
+
b
)
=
{
1
,
W
T
+
b
>
0
?
1
,
W
T
+
b
<
0
y=sign(W^TX+b)=\left\{\begin{array}{c} 1,W^T+b>0\\ -1,W^T+b<0 \\ \end{array}\right.
y=sign(WTX+b)={1,WT+b>0?1,WT+b<0?
�������֪��һ��,��Ȼ������һ����ƽ�����Ҽ��μ�����ij�ƽ��һ������������������������Զ�ij�ƽ����
1-�����֧������
�������Կɷֵ�ѵ����D={(x1,y1),(x2,y2),��,(xm,ym)},���ֳ�ƽ���ͨ���������Է���������:
W
T
+
b
=
0
W^T+b=0
WT+b=0
�����ռ�����㵽��ƽ�����:
r
=
�O
w
T
+
b
�O
/
�O
�O
w
�O
�O
r=|w^T+b|/||w||
r=�OwT+b�O/�O�Ow�O�O
���賬ƽ���ܽ�ѵ��������ȷ����,�����(xi,yi)��:
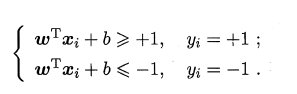
������ʾ,���볬ƽ������ļ���ѵ��������ʹ��ʽ�ĵȺų���,���DZ���Ϊ��֧��������,��������֧����������ƽ��ľ���֮��Ϊ:
r
=
2
/
�O
�O
w
�O
�O
r=2/||w||
r=2/�O�Ow�O�O

����ͼ��ʾ,Ϊʹr���,��w��ȡ��С,��������������:��r�����ֵ�ȼ�������ʽ����Сֵ,ͬʱ������ΪԼ��������
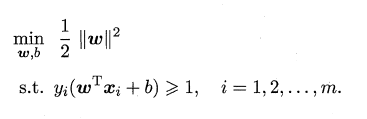
���Ϲ�ʽ����֧��������(Support Vector Machine,���SVM) �Ļ�����,����һ���Ż�����,�ʾֲ���Сֵ����ȫ����Сֵ,һ��ͨ���������շ�����⡣
2-�������ն�ż����
Ϊ�˷������SVM��������,���ǽ�������ת��Ϊ�������ն�ż���⡣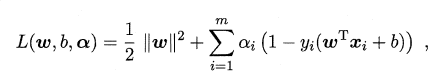
֧���������Ļ����͵Ķ�ż����:
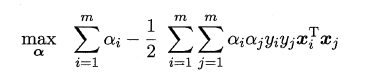
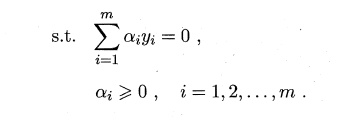
��������������KKT����:
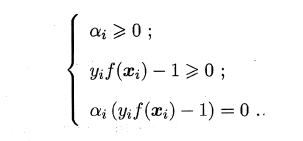
����i=0,�������������f(x)������г���,Ҳ�Ͳ����f(x)���κ�Ӱ��;
����i>0,�����
y
i
f
(
x
i
)
=
1
y_if(x_i)=1
yi?f(xi?)=1,����Ӧ��������λ��������߽���,��һ��֧��������
����ʾ��֧����������һ����Ҫ����:ѵ����ɺ�,�ֵ�ѵ������������Ҫ����,����ģ�ͽ���֧�������й���
������С�Ż�(sequential minimal optimization,SMO):���������Ƕ��ι滮����,������Ҫ���ι滮�㷨�����,������Ĺ�ģ������ѵ��������(��Ϊ��������ά������ѵ��������),�����ʵ����������ɺܴ�Ŀ��������������SMO��
3-����������C�����SVM
�����soft margin:��������ʵ�ʻ�ȡ����ʵ�����������������,ʹ��ѵ�����ݲ����������Կɷֵ�,ͨ������֧����������һЩ�����ϳ���,�Ӷ���������⡣�Դﵽ�������ʹ���֮���ҵ�ƽ�⡣

��������������:
��������ʱ�����Ʋ����������ڵ���1�������ĸ���ʹ֮�����ܵ��١�����һ���ͷ�ϵ��C>0,����ÿ��������(xi,yi)����һ���ɳڱ���(slack variables)�Ρ�0����������µ�Ŀ�꺯��:
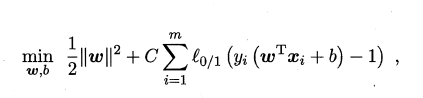
l
0
/
1
l_{0/1}
l0/1?�ǡ�0/1��ʧ������:
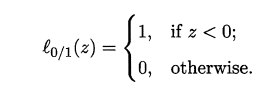
�����ʧ����:
l
0
/
1
l_{0/1}
l0/1? ����������,��ѧ���ʲ�̫��,һ��ѡ�������ʧ������
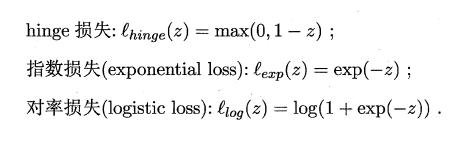 �����֧��������Ŀ�꺯��:
�����֧��������Ŀ�꺯��:
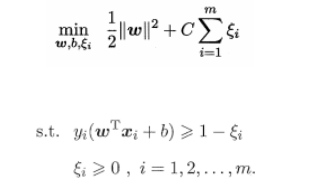
�����֧�����������������պ�����ʽ:
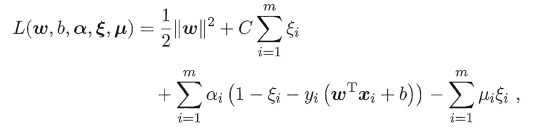
�����֧���������Ķ�ż����:
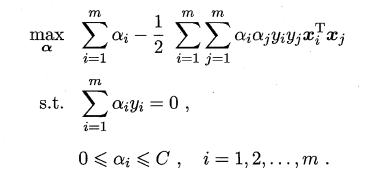
KKT����
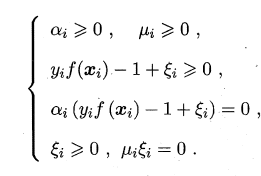
�����֧��������������ģ�ͽ���֧�������й�,��ͨ������hinge ��ʧ�����Ա�����ϡ���ԡ�
����:������Ϊһ��"��������"���Բ�ϣ���õ��Ľ��ʩ�Գͷ�,�Ӷ�ʹ���Ż�����������ϣ��Ŀ�ꡣ
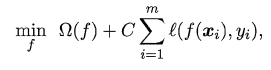
��
(
f
)
\Omega (f)
��(f)��Ϊ���ṹ���ա�,��������ģ��f��ijЩ����;
�ڶ���
��
i
=
1
m
l
(
f
(
x
i
)
,
y
i
)
\sum_{i=1}^{m}l(f(x_{i}),y_{i})
��i=1m?l(f(xi?),yi?)��Ϊ��������ա�,��������ģ����ѵ�����ݵ����ϳ̶�;
C���ڶԶ������С�
����һ���Ƕȿ�,��ʽҲ���Գ�Ϊ�ڡ���������,
��
(
f
)
\Omega (f)
��(f)��������,C����������
������:
L
0
L_0
L0?����
�O
�O
w
�O
�O
2
��
L
1
||w||_2��L_1
�O�Ow�O�O2?��L1?����
�O
�O
w
�O
�O
1
||w||_1
�O�Ow�O�O1?������
w
w
w�ķ�������ϡ��,�������������������
L
2
L_2
L2?����
�O
�O
w
�O
�O
2
||w||_2
�O�Ow�O�O2?������w�ķ���ȡֵ��������,��������������������ܡ�
4-�˼���-������SVM
�˺���:��ԭʼ�ռ�������Բ��ɷֵ����ʱ,��������ԭʼ�ռ�ӳ�䵽һ����ά�������ռ�,ʹ������������ռ������Կɷ�,��ά������ͼ��ʾ��

�����ռ��л��ֳ�ƽ������Ӧ��ģ�Ϳɱ�ʾΪ:
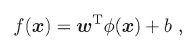
ֱ�Ӽ���Ƚ�����,ֱ�Ӷ���
k
(
?
,
?
)
k(\cdot ,\cdot )
k(?,?).
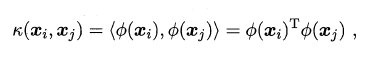
��
x
i
x_{i}
xi?��
x
j
x_{j}
xj?�������ռ���ڻ�����������ԭʼ�����ռ���ͨ������
k
(
?
,
?
)
k(\cdot ,\cdot )
k(?,?)����Ľ��������
k
(
?
,
?
)
k(\cdot ,\cdot )
k(?,?)�����˺�����
�˺�������:
��XΪ����ռ�,
k
(
?
,
?
)
k(\cdot ,\cdot )
k(?,?)�Ƕ�����
X
��
X
X\times X
X��X�ϵĶԳƾ���,��k�Ǻ˺������ҽ���������������
D
=
{
x
1
,
x
2
,
?
?
,
x
m
}
D=\left \{ x_{1},x_{2},\cdots ,x_{m} \right \}
D={x1?,x2?,?,xm?},�˾���K���ǰ�������:
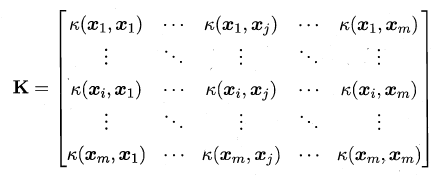
���ֳ����ĺ˺���:��ʹ����˹�˺���,����������ʾ�����

5-֧�������ع�
֧�������ع�(Support Vector Regression,SVR):
��������Իع���һ���������ѵ������,SVR����
f
(
x
)
=
W
T
+
b
f(x)=W^T+b
f(x)=WT+bΪ����,����Ϊ
2
��
2\varepsilon
2���ļ����,�����ѵ��������
- ���ڴ����ϵ�����<==>���Իع������ϵ�Ԥ�����Ϊ0
- ���ڴ����������ľ���Ϊ��ʧ<==>LR �������
- ��С����ʧ��ʹ���Ӵ����ܼ�����,�ﵽ���ѵ����Ŀ�ġ�
SVR������ʽ:
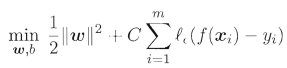
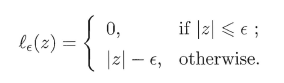
C������,
l
��
l_{\varepsilon }
l��?Ϊ
��
?
\varepsilon -
��?��������ʧ����.
SVRĿ�꺯��:
����
��
i
,
��
j
\xi _{i},\xi _{j}
��i?,��j?���ɳڱ���

SVR���������պ�����ʽ:
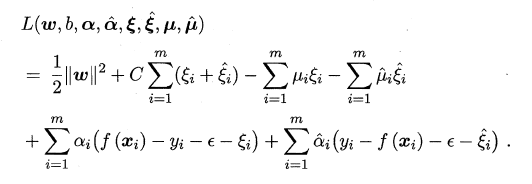
SVR��ż����:

KKT����:
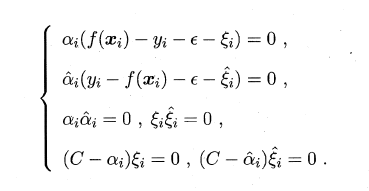
6-����
������ʹ��python����ʵ��SVM,��ʹ��SVM��һЩ�ķ�������