数据预处理
1.文本分类任务数据预处理方法
- 分词:将句子分割成独立的语义单元组成的序列过程
- 去停用词:识别并删除对分类意义不大且出现频率较高的词
- 词性标注:在分词后判断词性来添加特征
2.中文文本分词的方法
- 基于字符串匹配的分词方法
- 基于统计语言模型的分词方法
- 基于统计机器学习的分词方法(统计序列标准模型的代表,生成式模型的代表--隐马尔可夫模型(HMM),判别式模型的代表--线性链条件随机场(CRF))
3.基于字符串匹配的分词方法
基于词典进行贪心匹配,该种简单的算法即为前向最大匹配法(FMM)
由于中文句子本身具有重要信息后置的特点,因此有反向进行的“后向最大匹配法(BMM)”
双向最大匹配算法是指对待切分句子分别使用FMM和RMM进行分词,然后对切分结果不重合的歧义句进行进一步的处理。通常可对两种方法得到的词汇数目进行比较,根据数目的相同与否采取相应的措施,以此来降低歧义句的分词错误率。
基于字符串匹配的分词算法的不足在于其无法应对歧义与单词表外的单词。
4.统计语言模型用于分词, N-gram最大概率分词
假定一个句子S可能有很多种分词方法,那么最好的一种分词方法应该保证分完词后这个句子出现的概率最大。因此,只需利用统计语言模型计算出每种分词后句子出现的概率,并找出其中概率最大的,就能找到最好的分词方法。
从计算上来说,m一旦变大,也就是句子一旦变长,乘法后面的几项将会难以计算。因此我们使用马尔可夫假设:任意词的出现概率只与它前面的词
有关。
如果穷举所有可能的分词方法,并计算出每种可能性下句子的概率,那么计算量是相当大的。因此可以把该问题看作一个动态规划问题,并利用维特比(Viterbi)算法快速找到最佳分词。
5.基于序列标注的分词方法
将分词问题转换为给每个位置的字进行分类的问题,即序列标注问题。其中,类别有4个,一般用{B:begin, M:middle, E:end, S:single}这4个类别来描述一个分词样本中每个字所属的类别。它们代表的是该字在词语中的位置。其中,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
6.基于Bi-LSTM的词性标注方法
字的上下文信息对于排解切分歧义来说非常重要,能考虑的上下文越长,自然排解歧义的能力就越强。而前面的n-gram语言模型也只能做到考虑一定距离的上下文,那么有没有在理论上能考虑无限长上下文距离的分词模型呢?答案就是基于LSTM来做。当然啦,LSTM是有方向的,为了让每个位置的字分类时既能考虑全部历史信息(左边的所有的字),又能考虑全部未来信息(右边所有的字),我们可以使用双向LSTM(Bi-LSTM)来充当序列标注的骨架模型
LSTM完成对每个位置的上下文信息的编码后,最终通过softmax分类层完成对每个位置的分类,从而跟HMM和CRF一样完成了基于序列标注的中文分词。
7.词干提取和词形还原
词形还原(Lemmatization),是把一个任何形式的语言词汇还原为一般形式(能表达完整语义),而词干提取(Stemming)是抽取词的词干或词根形式(不一定能够表达完整语义)。词形还原和词干提取是词形规范化的两类重要方式,都能够达到有效归并词形的目的,二者既有联系也有区别。
特征提取
词袋模型
n-gram模型
主题建模
- tf-idf
- LDA
文本相似度
衡量文本之间的距离,与相似性计算是同一回事的两个方面,距离可以理解成“不相似性”。
如果我们比较相似度的计算对象是分词后的词汇序列、词性序列、命名实体序列等,那么常用的计算距离的方法有:Jaccard距离、Dice系数、汉明距离、编辑距离等等。
如果我们使用词嵌入向量作为相似度的比较对象,那么文本距离问题就简化成向量相似度计算方法了。常用的向量距离计算方法有余弦距离等。
分本分类模型
文本分类(TextRNN/TextCNN/TextRCNN/FastText/HAN)
1.FastText模型
字符级别的n-gram:为克服因单词内部形态信息不同而表达成不同词向量, fastText使用字符级别n-grams来表示一个单词。可以使用多个trigram的向量叠加来表达一个单词的向量。
- 对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
- 对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
fastText原理及实践 - 知乎 (zhihu.com)
2.TextCNN模型
卷积神经网络核心思想捕获局部特征。对于文本而言,局部特征就是由若干单词组成的滑动窗口, 类似于N-gram。

TextCNN的局限性
TextCNN是很适合中短文本场景的强baseline,但不适合长文本。因为卷积核尺寸通常不会设置很大,无法捕获长距离特征。同时max-pooling也存在局限,会丢掉一些有用的特征。TextCNN和传统的n-gram词袋模型本质相同,其好效果很大程度来自于词向量的引入。
3.TextRNN模型
TextRNN使用LSTM/GRU作为特征提取器, 利用RNN输出的logit进行concat来进行答案的预测。
TextRNN仅仅是将Word Embedding输入到双向LSTM中,然后对最后一位的输出输入到全连接层中,对其进行softmax分类。
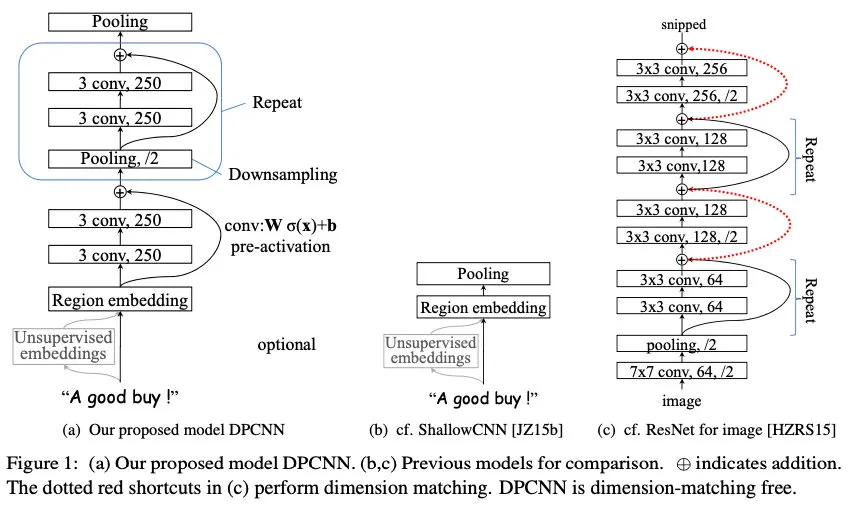
4.DPCNN模型
如何解决长文本分类任务?
可以使用改进的CNN,如DPCNN
可以使用RNN结构的分类器,也可以使用基于Attention机制的分类器
从经典文本分类模型TextCNN到深度模型DPCNN - 知乎 (zhihu.com)
DPCNN的特点:
- 区域嵌入:将TextCNN包含多尺寸卷积滤波器卷积层的卷积结果称为区域嵌入, 对一个文本区域/文本片段进行一组卷积操作后生成的embedding。DPCNN,采用一种不保留词序的做法,即首先对3-gram中的3个词的词向量取均值得到一个大小为 1 * D 的向量,然后设置一组大小为 1 * D 的一维卷积核对该3-gram进行卷积操作。
- 等长卷积:使用等长卷积,来提高词位embedding表示的丰富性。等长卷积的意义是:输出的词是由该位置输入的词以及其左右词的上下文信息提取得到的,也就是说,这个词包含被上下文信息修饰过的更高级别的语义。
- 下采样(1/2池化):本文使用一个 size=3,stride=2(大小为3,步长为2)的池化层进行最大池化,在此称为1/2池化层。每经过一个1/2池化层,序列的长度就被压缩成了原来的一半。因此,经过1/2池化后,同样一个size为3的卷积核,其能够感知到的文本片段就比之前长了一倍。
- 残差连接:减缓梯度弥散问题
5.TextRCNN模型
TextRCNN实际上将RNN与CNN进行结合,先使用双向RNN获取输入文本上的语义和语法信息,接着使用最大池化自动地筛选出最重要地特征,然后接一个全连接层用于分类。
使用RNN处理输入序列时,是对输入序列的词按照次序进行处理,它通过隐藏层储存了之前的序列信息,能更好地获取上下文信息。然而RNN是有偏模型,后面输入的词的重要性要高于之前的词,而实际上一个文本中后面的词并不一定是最重要的词,最重要的词可能出现在文本的任何地方。而CNN则是无偏模型,通过最大池化来自动地筛选文本中重要的词,能够解决RNN有偏的问题。然而CNN是通过使用一定尺寸的窗口来提取特征(卷积操作),窗口的尺寸实际很难确定,尺寸太小则会丢失重要的信息,尺寸过大导致参数过多且难以训练。
最后再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野,这里词的表示也可以只用双向RNN输出。
6.RNN + Attention模型
CNN和RNN用在文本分类任务中尽管效果显著,但都有一个不足的地方就是不够直观,可解释性不好,特别是在分析badcase时候感受尤其深刻。而注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献。
加入Attention之后最大的好处自然是能够直观的解释各个句子和词对分类类别的重要性。attention层做最后的特征融合。这个加attention的套路用到CNN编码器之后代替pooling也是可以的。
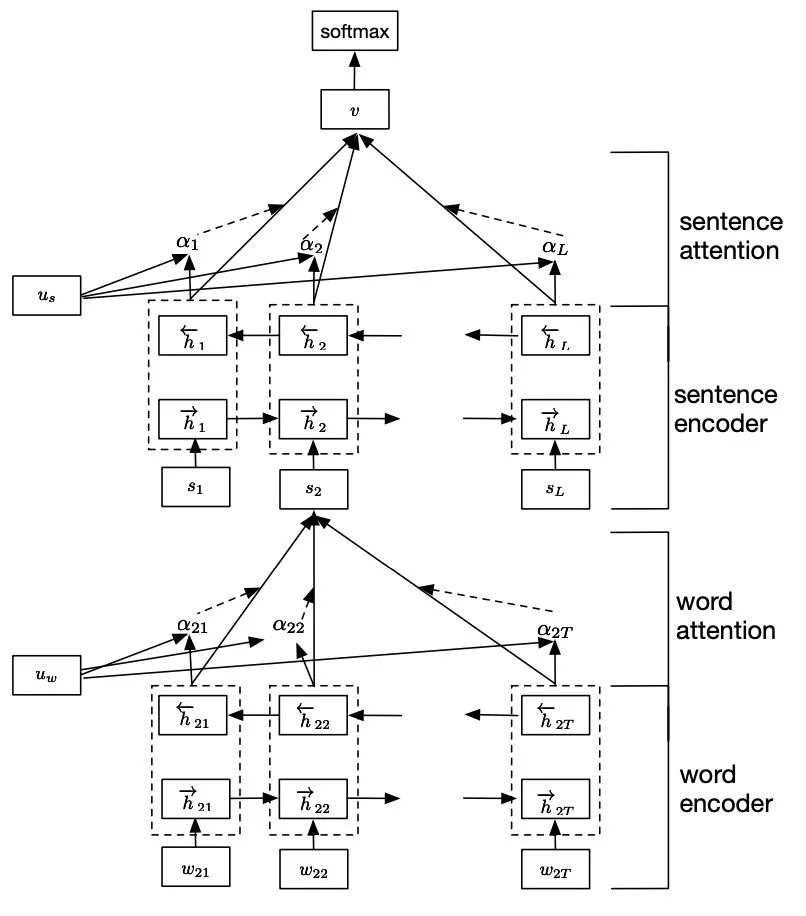
7.HAN模型
HAN是attention机制用于文本分类的典型工作,通过将
(1)文本组织成层次结构(词,句子)
(2)分别在词级别和句子级别使用注意力机制,保证最终文本表示由不同层次上重要的信息构成
先对每个句子用 BiGRU+Att 编码得到句向量,再对句向量用 BiGRU+Att 得到doc级别的表示进行分类。?
?8.GNN图神经网络
自然语言可以当作树结构和图结构来解析。文本中同时包含图结构,如句法分析和语法树往往以树形结构表示。
9.预训练模型
Transformer
自回归语言模型:ELMo、GPT、XLNet等
自编码语言模型:BERT、RoBERTa等
损失函数
激活函数sigmoid
二分类中,可以使用sigmoid函数将输入映射到(0,1)区间中, 从而得到属于某个类别的概率。
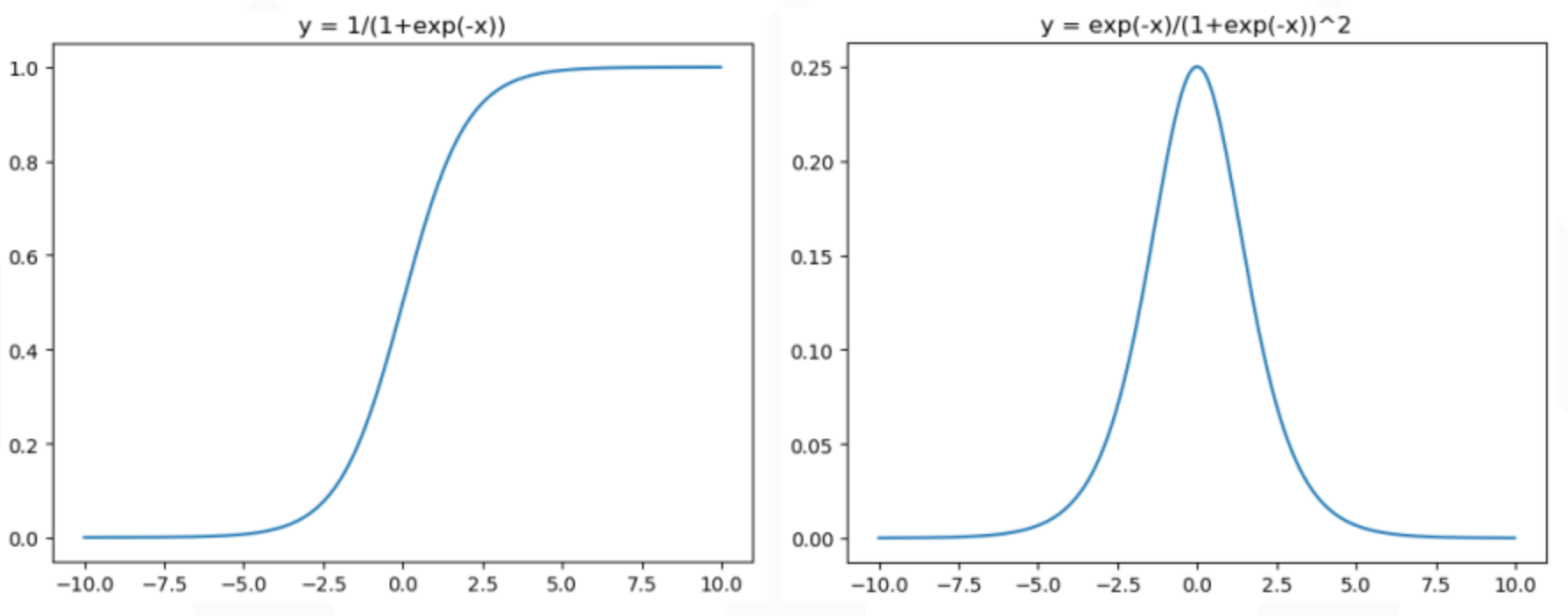
缺点:
- 输出范围在0 - 1之间,不是关于原点对称。需要做数据偏移
- 当x很大或者很小时,存在导数很小的情况,神经网络训练方法是BP算法, BP算法的基础是导数的链式法则,即多个导数的乘积。随着神经网络层数的加深,梯度向后传播到浅层网络时,基本无法引起参数的扰动,即没有将loss信息传递到浅层网络,导致梯度消失
- 计算exp较为耗时?
负对数似然损失函数(neg log-likelihood loss)
log对数损失函数的标准形式如下:
- log对数损失函数能很好地表征概率分布,尤其对于多分类任务,如果需要知道结果属于每个类别地置信度,则非常适合。
- 健壮性不强,相比于hinge loss对噪声更为敏感
- 逻辑回归地损失函数就是log对数损失函数
交叉熵损失函数(cross entropy loss)
指数损失函数(exponential loss)
指数损失函数的标准形式如下:
特点:对离群点、噪声非常敏感,经常用在AdaBoost算法中
均方误差损失函数(mean square error loss)
softmax
对于多分类任务,可以使用softmax函数,对输出的值归一化为概率值
损失函数(MSE、MAE、SmoothL1_loss...)
常见的损失函数(loss function)总结 - 知乎 (zhihu.com)
模型评估
文本分类任务使用的评估算法和指标有:
准确率、精确率、召回率、ROC曲线、AUC值、F1-score、混淆矩阵、kappa
【机器学习笔记】:准确率,精准率,召回率,真正率,假正率,ROC/AUC - 知乎 (zhihu.com)
混淆矩阵 和 kappa系数
混淆矩阵是具有两行两列的表,该表报告假阳性、假阴性、真阳性、真阴性的数量。所有正确的预测都位于表格的对角线上,因此很容易从视觉上检查表格中的预测错误。
kappa系数用于一致性检验,也可以用于衡量分类精度,kappa系数的计算是基于混淆矩阵的。
kappa系数介绍如百度百科所示