ǿ��ѧϰ(��)���� AlphaGo��Alpha Zero
1. AlphaGo
1.1 ��������
1.2 �������(State)

- ���̴�С:[19,19]�ľ���, ������Ϊ1,��֮Ϊ0��
- Input Shape:[19,19,17]��
- ���嵱ǰ״̬�����ȥ7����״̬:[19,19,1]��[19,19,7]��
- ���嵱ǰ״̬�����ȥ7����״̬:[19,19,1]��[19,19,7]��
- ��ǰ��˭����:[19,19,1] (����ȫΪ1,����ȫΪ0)
1.3 ѵ������������
- ʹ��behavior cloning �Բ���������г���ѵ��;
- �����������绥�����,��ʹ�ò����ݶȶԲ���������и���;
- ʹ�ò�������ȥѵ��״̬��ֵ����;
- ���ڲ�������ͼ�ֵ����,ʹ�����ؿ�����(Monte Carlo Tree Search, MCTS)����������
1.4 ģ��ѧϰ(Behavior Cloning)
ͨ��Behavior Cloning���˵ľ����г�ʼ����������IJ���,��������ĽṹΪ:
�����ʼ�����������,����������ĵ�������������,����ģ��ѧϰ(��������),ʹ�ý�������Ϊ��ʧ�������в�������:
- �۲�õ�״̬: s t s_t st?
- ʹ�ò����������Ԥ�� p t = [ �� ( 1 �O s t ; �� ) , �� ( 2 �O s t ; �� ) , . . . , �� ( 361 �O s t ; �� ) ] p_t=[\pi(1|s_t;\theta),\pi(2|s_t;\theta),...,\pi(361|s_t;\theta)] pt?=[��(1�Ost?;��),��(2�Ost?;��),...,��(361�Ost?;��)]
- ��������Ҳ�ȡ�Ķ���Ϊ a t ? a_t^* at??
- ���������Ԥ�����one-hot�����,��������ҵĶ������н����ؼ���,���������������
ģ��ѧϰ����Ϊ��ѭ�浸����
1.5 �����������ݲ����ݶȽ���ѧϰ

- ��������������ж���ֱ����Ϸ������Player V.S. Opponent,Player ʹ�ò����������µIJ���,Opponent���ѡ�ù�ȥ�����е����������
- �õ����ĵ���������: s 1 , a 1 , s 2 , a 2 , s 3 , a 3 , . . . , s T , a T s_1,a_1,s_2,a_2,s_3,a_3,...,s_T,a_T s1?,a1?,s2?,a2?,s3?,a3?,...,sT?,aT?
- Player��õĻر�Ϊ: u 1 = u 2 = u 3 = u T ( Ӯ �� Ϊ 1 , �� �� Ϊ ? 1 ) u_1=u_2=u_3=u_T(Ӯ��Ϊ1,����Ϊ-1) u1?=u2?=u3?=uT?(Ӯ��Ϊ1,����Ϊ?1)
- ���Ʋ����ݶ�(����) g �� = �� t = 1 T ? l o g ( �� ( ? �O s t ; �� ) ) ? �� ? u t g_\theta=\sum_{t=1}^T \frac{\partial log(\pi(\cdot|s_t;\theta))}{\partial\theta}\cdot u_t g��?=t=1��T??��?log(��(?�Ost?;��))??ut?
- �������� �� �� �� + �� ? g �� \theta\gets\theta+\beta\cdot g_{\theta} ������+��?g��?
1.6 ��ֵ����ѵ��
- ״̬��ֵ����: V �� ( S ) = E ( U t �O S t = s ) U t = 1 ( w i n ) U t = ? 1 ( f a i l ) V_\pi(S)=E(U_t|S_t=s)\\U_t=1(win)\\U_t=-1(fail) V��?(S)=E(Ut?�OSt?=s)Ut?=1(win)Ut?=?1(fail)
- ���������״̬��ֵ����: v ( s ; W ) �� V �� ( s ) v(s;W)\sim V_\pi(s) v(s;W)��V��?(s)
- ѵ������:
- ��������������ж���ֱ����Ϸ���� u 1 = u 2 = u 3 = u T ( Ӯ �� Ϊ 1 , �� �� Ϊ ? 1 ) u_1=u_2=u_3=u_T(Ӯ��Ϊ1,����Ϊ-1) u1?=u2?=u3?=uT?(Ӯ��Ϊ1,����Ϊ?1)
- ��ʧ����: L = �� t = 1 T 1 2 [ v ( s t ; W ) ? u t ] 2 L=\sum_{t=1}^T \frac{1}{2}[v(s_t;W)-u_t]^2 L=t=1��T?21?[v(st?;W)?ut?]2
- ���������: W �� W ? �� ? ? L ? W W\gets W-\alpha\cdot \frac{\partial L}{\partial W} W��W?��??W?L?
1.7 Monte Carlo Tree Search
ÿ�����ؿ�����(MCTS)����������:
- Selection:����Player���ݵ�ǰ״ִ̬��һ�ζ��� s t a t s_t\\a_t st?at?
- Expansion: ���������һ�ζ���,������״̬: s t + 1 s_{t+1} st+1?
- Evaluation: ʹ��״̬��ֵ���������õ���ֵ����: �� = v ( s t + 1 ; W ) \nu=v(s_{t+1};W) ��=v(st+1?;W)�������ֱ������,�õ�����: r r r�����붯�����д��: s c o r e ( a t ) = �� + r 2 score(a_t)=\frac{\nu+r}{2} score(at?)=2��+r?
- Backup:�Զ����ķ������и��¡�
1.7.1 Selection
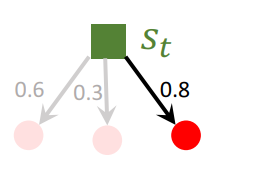
- �۲״̬ s t s_t st?
- �������п�ѡ����,������ѡ�����: s c o r e ( a ) = Q ( a ) + �� ? �� ( a �O s t ; �� ) 1 + N ( a ) {\rm score} (a)=Q(a) + \eta\cdot\frac{\pi(a|s_t;\theta)}{1+N(a)} score(a)=Q(a)+��?1+N(a)��(a�Ost?;��)?Q(a)Ϊͨ��MRTS�õ��Ķ�����ֵ,N(a)Ϊ��tʱ��״̬��������������a�Ĵ�����
- �������ѡ������Ķ�����ѡ�С�
1.7.2 Expansion

����״̬ת�ƺ���δ֪,���ò��Ժ�����Ϊ״̬ת�ƺ���
- ���ݲ��Ժ����Ͷ��ֹ۲��״̬,��������õ����ֵĶ���: a t �� �� �� ( ? �O s t �� ; �� ) a_t^{��}\sim \pi(\cdot|s_t^{'};\theta) at��?����(?�Ost��?;��)
- ���ֵĶ����������µ�״̬����: s t + 1 s_{t+1} st+1?
1.7.3 Evaluation

- �ظ�����ֱ����Ϸ����,Player�Ķ���: a k �� �� ( ? �O s k ; �� ) a_k\sim \pi(\cdot|s_k;\theta) ak?����(?�Osk?;��)Opponents�Ķ���: a k �� �� �� ( ? �O s k �� ; �� ) a_k^{'}\sim \pi(\cdot|s_k^{'};\theta) ak��?����(?�Osk��?;��)
- ��¼�Ծֽ�����Ļر�: w i n : r T = + 1 l o s e : r T = ? 1 win:r_T=+1\\lose:r_T=-1 win:rT?=+1lose:rT?=?1
- ���� t+1ʱ�̵�״̬��ֵ: �� ( s t + 1 ; W ) \nu(s_{t+1};W) ��(st+1?;W)
- t+1ʱ��״̬�ļ�ֵ����: V ( s t + 1 ) = 1 2 �� ( s t + 1 ; W ) + 1 2 r T V(s_{t+1})=\frac{1}{2}\nu(s_{t+1};W)+\frac{1}{2}r_T V(st+1?)=21?��(st+1?;W)+21?rT?
1.7.4 Backup

- ��ѡȡtʱ�̶�����Ĺ����ظ����: a t a_t at?
- tʱ�̶�����ÿ���ӽڵ��Ӧ������ֵ������¼,ȡƽ��ֵ����Qֵ(��Selection���õ�):
Q
(
a
t
)
=
m
e
a
n
(
t
h
e
r
e
c
o
r
d
e
d
V
s
��
)
Q(a_t)=mean(the\quad recorded \quad V^{'}_s)
Q(at?)=mean(therecordedVs��?)

1.8 ʹ��MCTS���о���
- ����a��ѡ�еĴ���Ϊ: N ( a ) N(a) N(a)
- �ڽ���MCTS��,��ѡ�д������Ķ�����Player����������: a t = a r g m a x a N ( a ) a_t=\mathop{argmax}\limits_{a}N(a) at?=aargmax?N(a)
- ִ����ôξ��ߺ�,Qֵ��Nֵ������Ϊ0: Q ( a ) = 0 N ( a ) = 0 Q(a)=0\\N(a)=0 Q(a)=0N(a)=0
2. AlphaGo Zero
2.1 ��������
2.2 ����AlphaGo�ĸĽ�����
- AlphaGo Zeroδʹ��Behavior cloning(δʹ�����ྭ��)
- ���������ѵ��������ʹ��MCTS��
2.2 ���������ѵ��
AlphaGo Zeroʹ��MCTSѵ����������
- �۲״̬: s t s_t st?
- ͨ�������������Ԥ��: p = [ �� ( a = 1 �O s t , �� ) , . . . , �� ( a = 361 �O s t , �� ) ] �� R 361 p=[\pi(a=1|s_t,\theta),...,\pi(a=361|s_t,\theta)]\in R^{361} p=[��(a=1�Ost?,��),...,��(a=361�Ost?,��)]��R361
- ͨ��MCTS����Ԥ��: n = n o r m a l i z e [ N ( a = 1 ) , N ( a = 2 ) , . . . , N ( a = 361 ) ] �� R 361 n=normalize[N(a=1),N(a=2),...,N(a=361)]\in R^{361} n=normalize[N(a=1),N(a=2),...,N(a=361)]��R361
- ������ʧ: L = C r o s s E n t r o p y ( n , p ) L=CrossEntropy(n,p) L=CrossEntropy(n,p)
- ��������������: �� �� ? L ? �� \theta \gets \frac{\partial L}{\partial \theta} ����?��?L?
3. ����ʵ��
3.1 ���������״̬��ֵ����ʵ��
3.1.1 ����
# -*- coding: utf-8 -*-
# @Time : 2022/4/1 13:47
# @Author : CyrusMay WJ
# @FileName: resnet.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/Cyrus_May
import tensorflow as tf
import logging
import sys
import os
os.environ["PATH"] += os.pathsep + 'D:\software_root\Anoconda3\envs\AI\Graphviz\\bin' # ��������ṹ��ͼ
class ResidualNet():
def __init__(self,input_dim,output_dim,net_struct,l2_reg=0,logger=None):
"""
:param input_dim:
:param output_dim:
:param net_struct: a list for residual network, net_struct[0] is the first CNN for inputs,
the rest is single block for residual connect. e.g. net_struct = [
{filters:64,kernel_size:(3,3), {filters:128,kernel_size:(3,3),
{filters:128,kernel_size:(3,3)}
]
:param logger:
"""
self.logger=logger
self.input_dim = input_dim
self.output_dim=output_dim
self.l2_reg = l2_reg
self.__build_model(net_struct)
def conv_layer(self,x,filters,kernel_size):
x = tf.keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
activation="linear",
padding="same",
data_format="channels_last",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg))(x)
x = tf.keras.layers.BatchNormalization(axis=-1)(x)
x = tf.keras.layers.LeakyReLU()(x)
return x
def residual_block(self,inputs,filters,kernel_size):
x = self.conv_layer(inputs,filters,kernel_size)
x = tf.keras.layers.Conv2D(filters=filters,
kernel_size=kernel_size,
activation="linear",
padding="same",
data_format="channels_last",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg))(x)
x = tf.keras.layers.BatchNormalization(axis=-1)(x)
if inputs.shape[-1] == filters:
x = tf.keras.layers.add([inputs,x])
else:
inputs = tf.keras.layers.Conv2D(filters=filters,
kernel_size=(1,1),
activation="linear",
padding="same",
data_format="channels_last",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg))(inputs)
x = tf.keras.layers.add([inputs, x])
x = tf.keras.layers.LeakyReLU()(x)
return x
def policy_head(self,inputs):
x = tf.keras.layers.Conv2D(filters=2,
kernel_size=(1,1),
activation="linear",
padding="same",
data_format="channels_last",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg))(inputs)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(units=self.output_dim,
activation="linear",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg),
name="policy_head"
)(x)
return x
def state_value_head(self,inputs):
x = tf.keras.layers.Conv2D(filters=2,
kernel_size=(1, 1),
activation="linear",
padding="same",
data_format="channels_last",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg))(inputs)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(units=1,
activation="linear",
kernel_regularizer=tf.keras.regularizers.l2(self.l2_reg),
bias_regularizer=tf.keras.regularizers.l2(self.l2_reg),
name="state_value_head"
)(x)
return x
def __build_model(self,net_struct):
input_layer = tf.keras.layers.Input(shape=self.input_dim,name="inputs")
x = self.conv_layer(input_layer,net_struct[0]["filters"],net_struct[0]["kernel_size"])
for i in range(1,len(net_struct)):
x = self.residual_block(x,net_struct[i]["filters"],net_struct[i]["kernel_size"])
v_output = self.state_value_head(x)
p_output = self.policy_head(x)
self.model = tf.keras.models.Model(inputs=input_layer,outputs=[p_output,v_output])
tf.keras.utils.plot_model(self.model, to_file="./AlphZero.png")
self.model.compile(optimizer=tf.optimizers.Adam(),
loss = {"policy_head":tf.nn.softmax_cross_entropy_with_logits,"state_value_head":"mean_squared_error"},
loss_weights={"policy_head":0.5,"state_value_head":0.5})
if __name__ == '__main__':
logger = logging.getLogger(name="ResidualNet")
logger.setLevel(logging.INFO)
screen_handler = logging.StreamHandler(sys.stdout)
screen_handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(module)s.%(funcName)s:%(lineno)d - %(levelname)s - %(message)s')
screen_handler.setFormatter(formatter)
logger.addHandler(screen_handler)
residual_net = ResidualNet(logger=logger,input_dim=[19,19,17],
output_dim=19*19,
net_struct=[
{"filters":64,"kernel_size":(3,3)},
{"filters": 128, "kernel_size": (3, 3)},
{"filters": 128, "kernel_size": (3, 3)},
{"filters": 64, "kernel_size": (3, 3)},
{"filters": 64, "kernel_size": (3, 3)},
])
3.1.2 ���

���IJ�������Ϊ�ο�Bվѧϰ��Ƶ��д�ıʼ�!
by CyrusMay 2022 03 31
����������ɫ �Ƿ�вʺ�
��������ӵ�� �Ƿ������
��������������(�ǿ�)��������