0. 往期内容
[二]深度学习Pytorch-张量的操作:拼接、切分、索引和变换
[七]深度学习Pytorch-DataLoader与Dataset(含人民币二分类实战)
[八]深度学习Pytorch-图像预处理transforms
[九]深度学习Pytorch-transforms图像增强(剪裁、翻转、旋转)
[十]深度学习Pytorch-transforms图像操作及自定义方法
[十一]深度学习Pytorch-模型创建与nn.Module
[十二]深度学习Pytorch-模型容器与AlexNet构建
[十三]深度学习Pytorch-卷积层(1D/2D/3D卷积、卷积nn.Conv2d、转置卷积nn.ConvTranspose)
深度学习Pytorch-卷积层
1. 1D/2D/3D卷积


 一个卷积核在一个信号上是几维它是几维卷积。
一个卷积核在一个信号上是几维它是几维卷积。
2. nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’)
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
(1)功能:对多个二维信号进行二维卷积;
(2)参数:
in_channels: 输入通道数;
out_channels: 输出通道数,等于卷积核的个数;
kernel_size: 卷积核的尺寸;
stride: 步长,stride步长是滑动时滑动几个像素;
padding: 填充个数,保证输入和输出图像在尺寸上是匹配的;
 左边:未加padding,输入44,输出22;
左边:未加padding,输入44,输出22;
右边:加了padding,输入55,输出55.
dilation: 空洞卷积的大小;
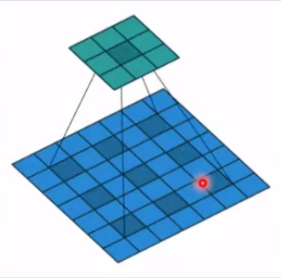
空洞卷积常用于分割任务,主要用于提升感受野,即输出图像一个像素能够看到输入图像更大的区域。
groups: 分组卷积设置;
groups用于设置分组卷积的组数,常用于模型的轻量化。
Alexnet也是分组卷积,原因是受制于硬件,因为它用了两个GPU进行训练。
bias: 偏置;

(3)代码示例:
set_seed(3) # 设置随机种子
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255 RGB
# convert to tensor 张量
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
# C*H*W to B*C*H*W 扩展成四维,增加batchsize维度
img_tensor.unsqueeze_(dim=0)
# ================================= create convolution layer ==================================
# ================ 2d
flag = 1
# flag = 0
if flag:
#图像是RGB具有三个通道,因此in_channels=3,设置一个卷积核来观察out_channels=1,卷积核为3*3
conv_layer = nn.Conv2d(3, 1, 3) # (in_channels, out_channels, 卷积核size)
#初始化
#weights:[1,3,3,3]=(out_channels, in_channels , h, w) h,w是二维卷积核的尺寸
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================================= visualization ==================================
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray')
plt.subplot(121).imshow(img_raw)
plt.show()

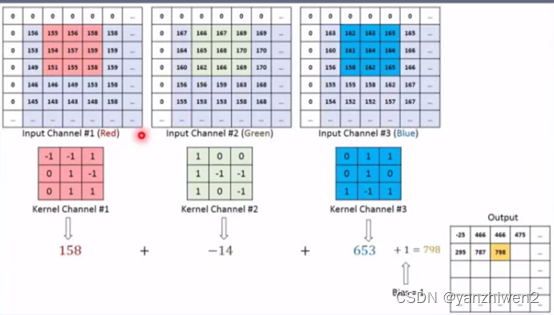
虽然是三维卷积核(3个通道33),但是每一个卷积核在一个信号中是二维滑动,因此是二维卷积。
3. 转置卷积
3.1 转置卷积定义
 转置卷积通常用于图像分割。
转置卷积通常用于图像分割。
 首先,将输入图像
首先,将输入图像4*4拉成16*1的向量,其中16是4*4所有的像素;1是1张图片。
然后,卷积核3*3会变成4*16的矩阵,其中16是3*3=9个权值通过补0得到16个数;,4是根据图像尺寸、padding、stride、dilation等计算得到的输出图像中像素的总个数(右图中绿色一共四个)。
最后,卷积核矩阵乘以图像矩阵得到4*1,然后再reshape为2*2的输出特征图。

首先,将输入图像2*2拉成4*1的向量,其中4是2*2=4得到的输入图像中所有像素的个数,1是1张图片。
然后,卷积核3*3会变成16*4的矩阵,其中4是3*3=9中剔除多余的剩下的4个,16是根据图像尺寸、padding、stride、dilation等计算得到的输出图像中像素的总个数(右上图中绿色一共4*4=16个)。
最后,卷积核矩阵乘以图像矩阵得到16*1,然后再reshape为4*4的输出特征图。
3.2 nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode=‘zeros’)
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros', device=None, dtype=None)
(1)功能:转置卷积实现上采样;
(2)参数:同上;

(3)代码示例:
set_seed(3) # 设置随机种子
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255 RGB
# convert to tensor 张量
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
# C*H*W to B*C*H*W 扩展成四维,增加batchsize维度
img_tensor.unsqueeze_(dim=0)
# ================================= create convolution layer ==================================
# ================ ConvTranspose2d
flag = 1
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) #(in_channels, out_channels, 卷积核size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================================= visualization ==================================
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray')
plt.subplot(121).imshow(img_raw)
plt.show()

转置卷积后图像变得像棋盘一样,叫棋盘效应。

(512-1)*2+3=1025
4. 完整代码
nn_layers_convolution.py:
# -*- coding: utf-8 -*-
"""
# @file name : nn_layers_convolution.py
# @brief : 学习卷积层
"""
import os
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
from tools.common_tools import transform_invert, set_seed
set_seed(3) # 设置随机种子
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255 RGB
# convert to tensor 张量
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
# C*H*W to B*C*H*W 扩展成四维,增加batchsize维度
img_tensor.unsqueeze_(dim=0)
# ================================= create convolution layer ==================================
# ================ 2d
flag = 1
# flag = 0
if flag:
#图像是RGB具有三个通道,因此in_channels=3,设置一个卷积核来观察out_channels=1,卷积核为3*3
conv_layer = nn.Conv2d(3, 1, 3) # (in_channels, out_channels, 卷积核size)
#初始化
#weights:[1,3,3,3]=(out_channels, in_channels , h, w) h,w是二维卷积核的尺寸
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================ transposed
# flag = 1
flag = 0
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) #(in_channels, out_channels, 卷积核size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================================= visualization ==================================
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray')
plt.subplot(121).imshow(img_raw)
plt.show()