Improving Distantly-Supervised Relation Extraction with Joint Label Embedding
领域:
远程监督关系抽取
创新点:
1)引入实体描述信息的去噪(一是只选择第一段,二是attention机制去噪)
2)引入实体label embedding,辅助得到bag中最正确的instance,做关系分类
出发点:
包的关系识别,因此如何对包去噪,是关键问题。
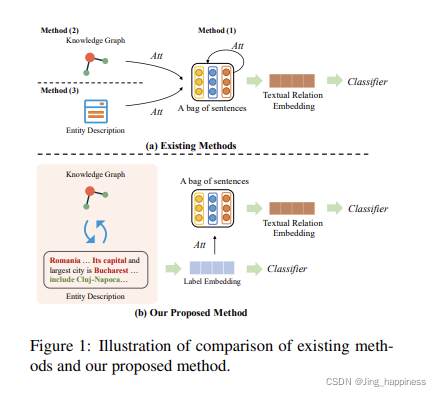
在已有的研究中,最早是融入知识图谱中的实体关系结构信息,后来,实体描述信息被作为外部信息来源之一。
核心思想:
在添加知识图谱结构和实体描述信息的基础上,如何对实体描述信息去噪?其次,考虑到关系信息对于bag的类别标签识别具有帮助作用,因此,将label embedding作为外部信息之一,但不同于直接将relation做embedding(比如,‘出生于’,通过bert预训练直接得到关系的向量表示)的方式,这篇文章是建立在KG和实体信息的基础上。
前人研究:
attention的类别:
分为三类:(1)没有外部信息的典型注意力模型(Lin et al., 2016; Du et al., 2018),(2)使用KGs的attention model (Han et al., 2018a), (3) 使用实体描述等辅助信息的注意力模型
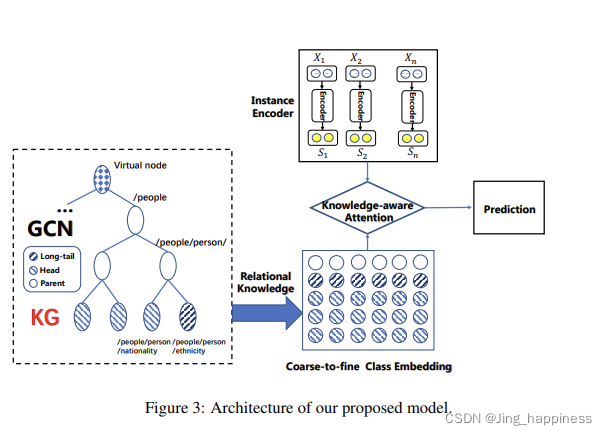
核心流程:
整个模型分为两个部分,一是嵌入向量的获取,二是分类器的训练。
(1)向量表示。
句子的向量表示
在句子初始向量获取时,是通过预训练模型得到初始词向量,另外加上cat上,相对于两实体的位置向量。在通过CNN作为bag中instance的向量表示s。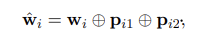
实体的向量表示
实体向量表示是考虑知识图谱中的实体关系结构信息和实体描述信息,分别得到对应的向量表示,在通过attention机制,得到实体表示向量de
label embedding
对de 和知识图谱的r通过门控机制得到关系label的向量表示r’
句子的attention_1
将句子的向量表示s和得到的de向量做cat,,然后以r’作为注意力向量,为句子中的instance分配不同的注意力权重,得到bag的向量表示
(2)关系分类
针对label embedding(L1)和对应的bag的embedding(L2)分别做关系分类任务
(3)损失函数
cross entropy

Long-tail Relation Extraction via Knowledge Graph Embeddings and Graph Convolution Networks
领域:
远程监督关系抽取
出发点:
根据关系表示找到最相关的instance,做bag级别的关系分类。
核心:
针对远程监督数据集中的长尾关系(即关系实例数量较少的关系类别),提出通过关系层级结构,基于注意力机制建模bag中的intsance的表示向量,选择相关的实例作为判断包标签的依据,在建模其向量表示(对每一层的关系表示做注意力加权,因为,不同的关系具有不同的层级结构,如果其上层关系只有一个节点,说明这两个关系级别之间联系紧密,该上层关系对于预测下层关系具有较大的帮助)
流程:
涉及到关系的建模以及不同层级间关系向量表示的融合。