A Comprehensive Study on Cross-View Gait Based Human Identification with Deep CNNs
������Ϣ:
����:Zifeng Wu, Yongzhen Huang, Liang Wang, Xiaogang Wang, and Tieniu Tan
TPAMI 2017
��Ҳ�ǵ�һƪ�����ѧϰӦ���ڲ�̬ʶ�������,�����Ҳ���˺ܴ�ķ�Ծ��
(�ó��ó�����������ĺó��������һƪ��̬����ϣ������ϸ��һЩ,��þúþá�
ժҪ
���ڲ�̬������ʶ��:ͨ����Ⱦ���������ѧϰ�����ԡ�ͨ��һС���ǹ��Ķ�Ƕ�������·��Ƶ,����ѵ�����������ȥʶ��ͬ�����������IJ�̬ģʽ�ĸı�,�Ӷ�ʶ����˵����ݡ�
���ǵ�һ�ʹ�����ѧϰ���в�̬ʶ��Ĺ���������ʹ�ò�ͬ��Ԥ��������������ṹ���ڲ�ͬ����(cross-view & cross-walking)�ṩ�˴�����ʵ��������
�������������CASIA-B���ݼ���������,���˻���cross-view�IJ�̬ʶ��,��֮ǰ��õķ���ӵ�кܴ���������������������cross-view�ǶȽϴ�(��С��36��)ʱ,ƽ��ʶ���ʿ��Դﵽ94.1%(֮ǰ�Ľ������65%)��
֮����������Ӧ����OU-ISIR����IJ�̬���ݼ���ȥ�����䷺������,OU-ISIR�ǵ�ǰ���������IJ�̬ʶ�����ݼ�,��4007�����塣������ݼ����ض��ӽ��ϵ�ƽ��ȷ�ʳ�����98%��cross-view�����µ�ʶ��ȷ�ʳ�����91%��
����,��USF��̬���ݼ�(���ⳡ���IJ�̬����)��,Ҳչ�ֳ�����õ�Ч����
Intro
��̬ʶ��������ս���ҵ�������ʶ���ص�����:
- ����������ص�����:�����ٶȡ����š�Я����Ʒ
- ���豸��ص�����:֡�ٶȡ�����ֱ���
- ��������:��������������ӽ�
���,cross-view�����Գ�Ϊ����Ƶ�������Ĺؼ�������,���ӽǸı�ʱ,�п��ܻᵼ������֮��IJ��������IJ�𡣶��ڻ��ڲ�̬����ͼ(ͨ��ƽ����̬�����ж�����˵�����)�IJ�̬ʶ��Ҳͬ����ˡ�
����cross-view�IJ�̬ʶ���ſ��Ա���Ϊ����:
��һ�����ؽ������3D�ṹ,�ܹ�ͨ��ͶӰ���������2D�ӽ�,���������ʵ����ǰ���Ľ��,������ͨ����Ҫ��Ƕȵ�����ӽǺ��ܹ���ȫ���ƹ������Ļ���;
�ڶ�����ʹ���ֹ�ѡ��Ķ��ӽ��������ڲ�̬ʶ��,��Щ����ͨ�����ض��������кܺõı���,��ͨ�����Է�������ij�����
��������ѧϰcross-viewͶӰ,�ܹ��Ѳ�̬������һ���ӽDZ�������һ���ӽ�,�����Ϳ��Դ�������Ƶ�жԱȹ�һ���IJ�̬����ȥ�������ƶȡ������ַ����ǵ�cross-view�ĽǶȺ�Сʱ����,���Ƕ�������36������ʱ,���ܾͻἱ���½���
��̬������Ƶ�е�ʱ������,������������������ʶ�����IJ�ͬ���������ǿ���һ�����������:ͨ��cross-view�IJ�̬��Ƶ���н����˵�ʶ��, ��ij���������������˼ӱ�ǩ��cross-view��(�������)�������������һ�ֶ˵��˵ķ�ʽֱ��Ԥ���Ѹ���һ�����������ƶȡ� ���ǵ���̬����cross-view�Ķ�����,��̬ʶ��Ӧ�û�dz��ʺ��ڷ��������ģ�͡�
������:
- ����CNN�IJ�̬ʶ��,��������Զ�ʶ�����̬�������������ֶȵĸı�;
- �ṩ�˷ḻ�������ڶ�������(cross-view & cross-walking-condition)����Ԥ��������������ṹ��ͬʱ;
- ���������������ݼ�(CASIA-B, OU-ISIR and USF)�ϵ�ȷ�ʡ�
Related Work
���ڲ�̬ʶ��Ľ������״�ſ��Ա���Ϊ����:һ���ǽ�ģ����ĵײ�ṹ,��һ����ֱ�Ӵ���Ƶ����ȡ��̬��ʾ����ƪ�����ǻ��ں��ߵ��о���
�����Ŀ���,������Method֮��������ȷʵ�ֶ����ں�����������,����ɾ����hh
Method
Gait Recognition
-
Ŀ��
�������еIJ�̬������ɵ�gallery,Ԥ��probe sample�����ݡ�
��ѧ��ʾ:����һ��probe sample x \mathbf x x �� N g N_g Ng? ͬ����һ��gallery { ( x i , y i = i ) �O i = 1 , �� , N g } \{(\mathbf x_i,y_i=i)|i=1,��,N_g\} {(xi?,yi?=i)�Oi=1,��,Ng?} ,�˵����� y ( x ) y(x) y(x) ��Ҫ��Ԥ�������
-
��ƪ����������ָ��Ѵ��������:
��cross-view(�ӽDz�ͬ);
��cross-walking-condition(��������������ͼ�����д��»�,��Ԥ�������ͼ����������·����) -
��������ͼ�IJ�̬ʶ���pipline:
ʹ��һЩ�������뷨��ԭʼ��Ƶ��������ȡ��������;Ȼ������ʱ�����н�����ͼ���ж����ƽ���Եõ�����ͼ;֮�����һ������ͼ������gallery�е�����ͼ,��������֮������ƶ�(����ֱ��ͨ��ŷ�Ͼ������);���ó���������ͼ������,ͨ��ʹ������ڷ�������

Network Structure
��������ṹ���Ա�����Ϊ���¹�ʽ:
s
i
=
��
(
��
(
?
(
x
)
,
?
(
x
i
)
)
)
s_i=\eta(\psi(\phi(\mathbf x),\phi(\mathbf x_i)))
si?=��(��(?(x),?(xi?)))
x
\mathbf x
x �Ǹ�����������ͼ,
x
i
\mathbf x_i
xi? ������������ͼ����,
?
\phi
? ��
x
\mathbf x
x ��
x
i
\mathbf x_i
xi? ͶӰ�������ռ���,
��
\psi
�� ����������,������һ�����������ȫ���Ӳ�,
��
\eta
�� ΪԤ����,Ϊ������,����һ��ȫ���Ӳ��softmax��,������ʵ��Ҳ���Զѵ�����ľ��������ȫ���Ӳ㡣
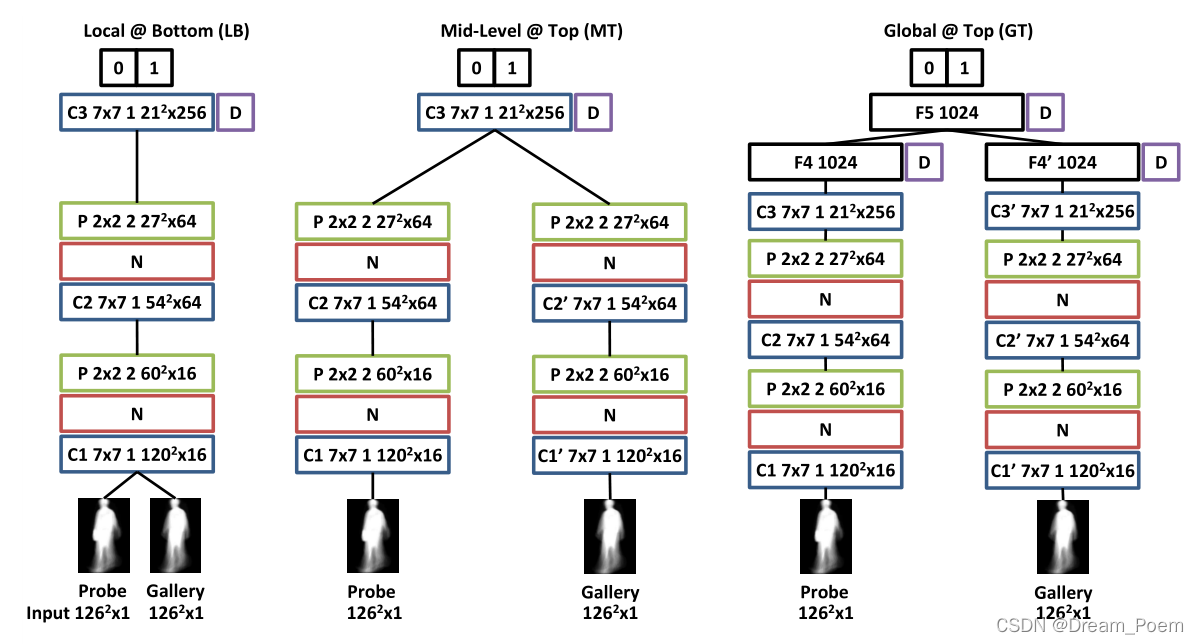
��ͼ��ʾ���������о�����������ṹ,�ؼ����������ڴ����↑ʼƥ������ͼ�Ե�����,�ڵײ㻹�Ƕ���,�Ǿֲ���������ȫ��������
������������,���еľ����˶���7*7��С,����Ϊ1;���еĿռ�ػ�����2*2��С,����Ϊ2;���е���Ԫ��ʹ��ReLU�������һ����softmax��
-
Matching Local Features at the Bottom Layer (LB)
�ڼ�������ͼ�ԵIJ��֮ǰֻ�������Բ�,������ײ��16��������ʵ�ֵġ�������������,���ȶ���������ľֲ�����������¼�Ȩ,�ٶԼ�Ȩ��Ľ����͡�
Ŀ���ǻ���cross-view�IJ�̬ʶ��ģ�����Թ�һ��,�����ȼ���intro�������ĵ������,������������matching֮��������������,��Ϊ�˴�����ͼ����ѧϰ�����ӵ�ģʽ��

-
Matching Mid-Level Features at the Top Layer (MT)
�ڼ�����֮ǰ����������������ͨ���������������ķ�������������ͼ�Բ��ȡ����LB��dz������Բ�������C3�㲢�����ϸ������ϵ�ȫ������,�����м����������ӡ�
LB��MT������:LB���ڵײ��оֲ�����ʱֱ�Ӽ���Ȩ�ز��,Ȼ�������������ں�������������ѧϰģʽ;��MT����ѧϰ�м�������,�ټ���������������ĸ��Ӷȼ�������ͬ��,ֻ��˳��ͬ��
-
Matching Global Features at the Top Layer (GT)
����ͼ��ͨ��ѧϰ����ȫ�������������������MT��������ȫ���Ӳ㡣F4��F4�������˲�����������Ϊȫ���Ӳ�Ĺ�ϵ,GT����ĸ��Ӷ�Ҫ��ǰ���ָߺܶ�,���п��ܻ���Ϊ�������Ӷ����¹���ϡ����ŵ�������ܽ���,���������Ч�ʡ�
����LB��MT,ÿ�μ��㶼���һ��probe��N��galleryͨ����������,������GT������ǰ�洢����gallery��F4��������(Ϊɶ����ܱ�����,�ҵ�������,�������ھ�����ѧ����ģʽ�Ǿֲ�����,��ȫ���Ӳ���ȫ������,�ֲ�������ѧϰ����ģʽ���ܶ���gallery��ÿһ������ͼ�Զ�������ͬ,�����ܹ������ֻ����ȫ������)
-
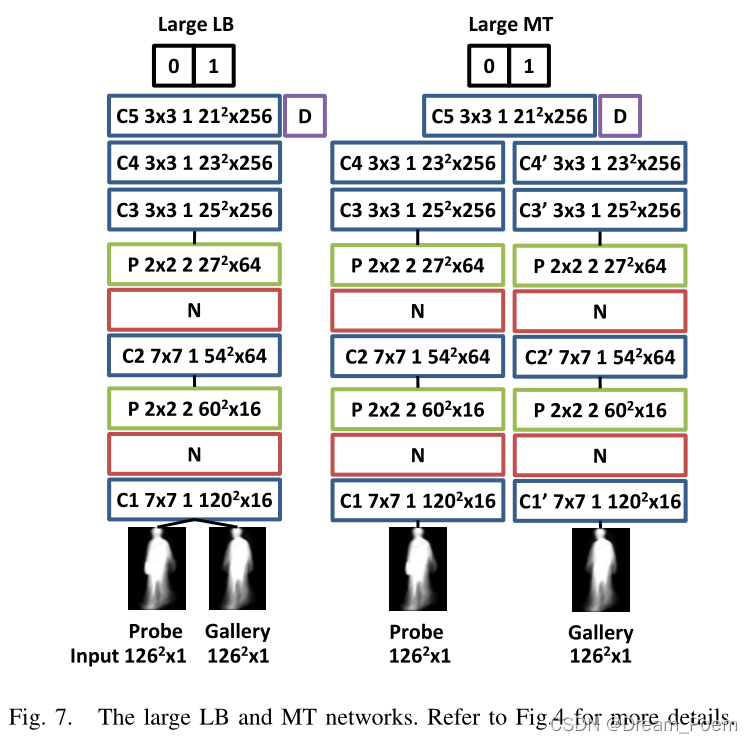
�����һЩ��dz�������(�����ֲ�������)��һЩ����������(�����Ӹ�ȫ�ֵ�����):

Temporal Information
-
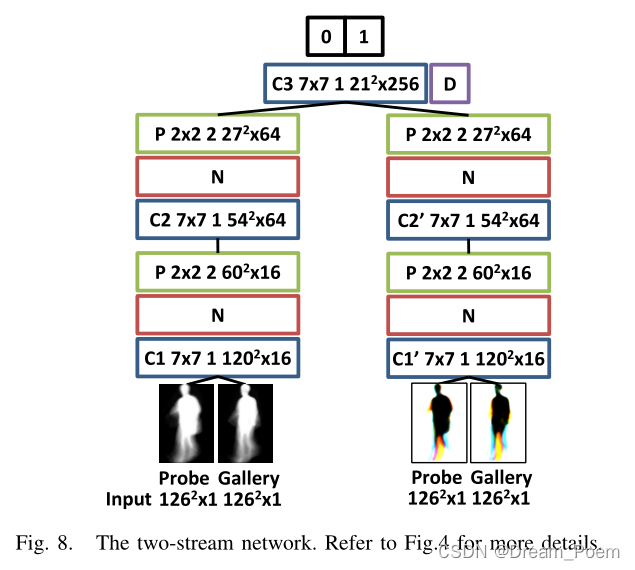
ѵ����һ��������˫�����硰�Ķ���:����Ǻ������к�LB��ͬ�Ľṹ������;���Ҳ�������ʱ��̬ͼ��(CGI,ͨ����ɫӳ��ķ�ʽЯ��ʱ����Ϣ),�Ǵ����Ӿ�����Ӧ�IJ��֡�
-
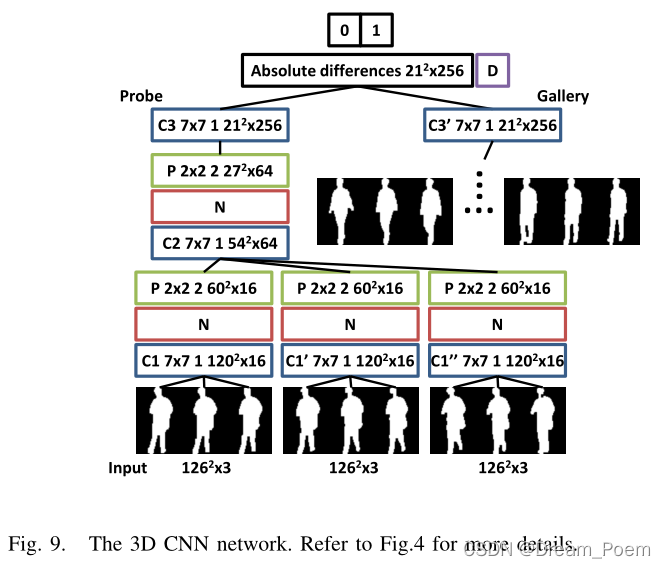
����Ƶ�ĸ���֡��Ϊ����,�����������ƽ��,��ͼ�е�����Ϊ9��֡,�ڵ�һ��͵ڶ���ѵ����ά��������,��C3��C3����Լ����������������ƽ����
ʵ��
(����һ������˵ ���ε������澡ͷ,���ټ���hh,����Խ��ǵ�Խ��ʵ����ܿ�����Խ�걸��
A. ���ݼ�:CASIA-B��OU-ISIR��USF
B. ѵ��ϸ��:û��ϸ��,�����һЩGEI��Mixed-GEI��ȡ����,logistic�ع�,ѵ��������������,�����ȡ�
C. ����ṹ��Ӱ��:
- ʵ�������GT����Ͻ�Ϊ����(�����ᵽԭ����������ݹ�С)���������������ڱ������֮��ǿ��ļ���Ч��,����һ��Compact Mid-Level & Top (CMT),�ھ�������ʹ���˸���IJ�����
- һЩʵ������
D. ����ϡ��̶ȵ�Ӱ��:ϡ����Ը���MT��������,������ͨ�����ƹ����ʵ�ֵġ�
E. ������ȵ�Ӱ��:���������߱�dz�����ܸ������ܡ�
F. ��������ͼ��С��Ӱ��:�����²�����ʵ��,�������һЩ,��������ô�ı�Ч������baseline�á����������Ҫ��һ��ļ���Ч��,�������²�����
G. �����������ģ�͵�Ӱ��:Ϊ�������������ͼ�������Ҫ��,�ڻ��֮ǰ�ƶ���һЩ����,����CNN�Դ��кܺõ�³���ԡ�
H. ������ǿ:��û�о���������ǿ���������,�������ˡ�
I. ʱ����Ϣ��Ӱ��:��˫�����硱��Ч��Ҫ����һЩ������3D������������˵,��3D�������0���ӵ�2ʱ,Ч�������Ե����,����3֡������Ч�����á�
֮�����������ݼ��ϵĶԱ�Ч����
Discussion
- ������Ҫһ��������ϵIJ�̬ʶ�����ݼ���
- ���ǿ����и��õ�Ԥ����,�������ؼ���ǡ����˼��ȵȡ�