张量(tensor)比Numpy的ndarray多一些重要功能。张量表示一个数组组成的数组。
- (1)GPU很好地支持加速计算,而Numpy仅支持CPU计算。
- (2)张量类支持自动微分。
1. 数据操作的实现
首先需要导入torch:
import torch
1.1 创建张量
有四种方式可以创建张量。
- 创建随机张量:rand(), randn(), empty()
- 创建指定类型张量:zeros(), ones(), arange()+reshape()
- 利用列表创建张量:torch.tensor([ ])
- 基于已知tensor创建tensor:torch.randn_like()
(1)创建随机张量
- randn
利用torch.randn(x,y)创建随机张量。
torch.randn(2,3)
tensor([[ 0.0422, 0.8539, 0.6049],
[ 0.1894, -0.2011, 0.9607]])
- rand
利用torch.rand(x,y)创建随机张量。
torch.rand(5,3)
tensor([[0.3854, 0.9028, 0.6086],
[0.5852, 0.8518, 0.0370],
[0.0108, 0.4854, 0.4645],
[0.1960, 0.2920, 0.4442],
[0.3127, 0.3314, 0.8453]])
- empty
torch.empty(5,3
tensor([[9.0919e-39, 8.4490e-39, 9.6429e-39],
[8.4490e-39, 9.6429e-39, 9.2755e-39],
[1.0286e-38, 9.0919e-39, 8.9082e-39],
[9.2755e-39, 8.4490e-39, 1.0194e-38],
[9.0919e-39, 8.4490e-39, 9.9184e-39]])
(2)创建指定类型张量
- arange + reshape
利用torch.arrange(n)创建大小为n的从0到N-1的一维张量。在使用reshape()函数改变张量结构。
x = torch.arange(12)
print(x)
X = x.reshape(3,4)
print(X)
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
- zeros(), ones()
创建指定结构的全为0或者全为1的张量。
torch.zeros((2,3,4))
torch.ones((2,3,4))
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
(3)利用列表创建张量
torch.tensor([[1,2,3],[3,2,1]])
tensor([[1, 2, 3],
[3, 2, 1]])
(4)利用已知张量创建新的张量
torch.randn_like(tensor_x)
创建一个与张量x结构一样的新随机张量。
x = torch.randn_like(x)
x
tensor([[-1.7494, -0.3668, 0.4855],
[ 0.2274, -1.2627, 1.3266],
[-1.6725, 0.0836, -0.9513],
[ 1.0386, 0.5378, -0.4176],
[-0.0559, 0.3609, -0.4307]])
1.2 张量的属性
- shape:返回张量的形状。
- numel():返回张量内部元素的总数。
(1)tensor.shape
利用shape访问张量的形状。tensor.shape会返回形状列表。可以通过[0],[1]对列表的访问得到行列的大小。
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
X.shape
X.shape[0]
torch.Size([3, 4])
3
(2)tensor.numel()
numel()函数可以获得张量内部的元素总数。
X.numel()
12
1.3 张量的操作
- 改变形状:reshape(), view()
- 张量的拼接:cat()
- 张量求和:sum()
- 转变为numpy:numpy(),from_numpy()
(1)改变形状
- view():返回的新的tensor和源tensor共享内存。
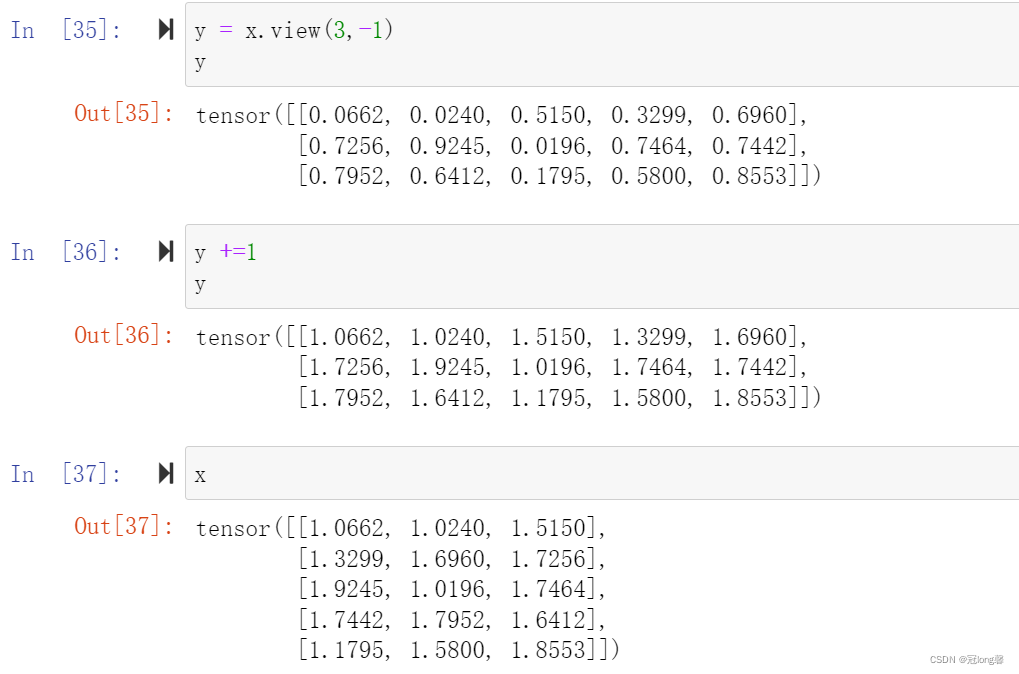
- reshape():返回的新的tensor是原tensor的副本。
(2)张量的拼接
torch.cat((X,Y), dim = 0/1)。
- 当 d i m = 0 dim = 0 dim=0时,XY可以按行拼接,此时XY的列数需要有相同的列数。
- 当 d i m = 1 dim=1 dim=1时,XY可以按列拼接,此时XY需要有相同的行数。
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
print(X)
Y = torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
print(Y)
torch.cat((X,Y), dim=0)
torch.cat((X,Y), dim=1)
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[2., 1., 4., 3.],
[1., 2., 3., 4.],
[4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]])
(3)张量求和
利用.sum(dim = 0/1)‘计算张量的和。
- 不考虑dim值时,返回张量中的所有元素求和。
- 当 d i m = 0 dim=0 dim=0时,是将每列元素求和,返回行向量。
- 当 d i m = 1 dim=1 dim=1时,是将每行元素求和,返回列向量。
X.sum(0)
X.sum(1)
tensor([12., 15., 18., 21.])
tensor([ 6., 22., 38.])
(4)转换为numpy
使用numpy()将tensor转换为Numpy,使用torch.from_numpy()将numpy转换为tensor。
A = B.numpy()
1.4 节省内存
运行一些操作可能会导致为新结果分配内存。当我们用Y = X + Y时,我们取消引用Y指向的张量,而是指向新分配的内存处的张量。为了节省内存,我们希望操作原地执行这些更新。因此可以使用切片法表示先前分配的数组。
Y = X + Y # 新分配内存
Y[:] = X + Y # 先前分配的数组
2. 数据预处理
(1)缺失值处理
- 数值型:fillna()、删除。
- 非数值型:删除、get_dummies(dummy_na=True)。
参考资料
[1]跟着李沐学AI:https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
[2]课程资料:https://zh-v2.d2l.ai/chapter_preliminaries/ndarray.html