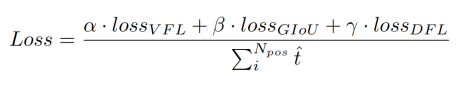原文地址:https://arxiv.org/abs/2203.16250
Github地址:https://github.com/PaddlePaddle/PaddleDetection
??上周刚刚学习绘制了YOLOX结构,这周发现PP-YOLOE新鲜出炉,特此记录。
1.文章摘要
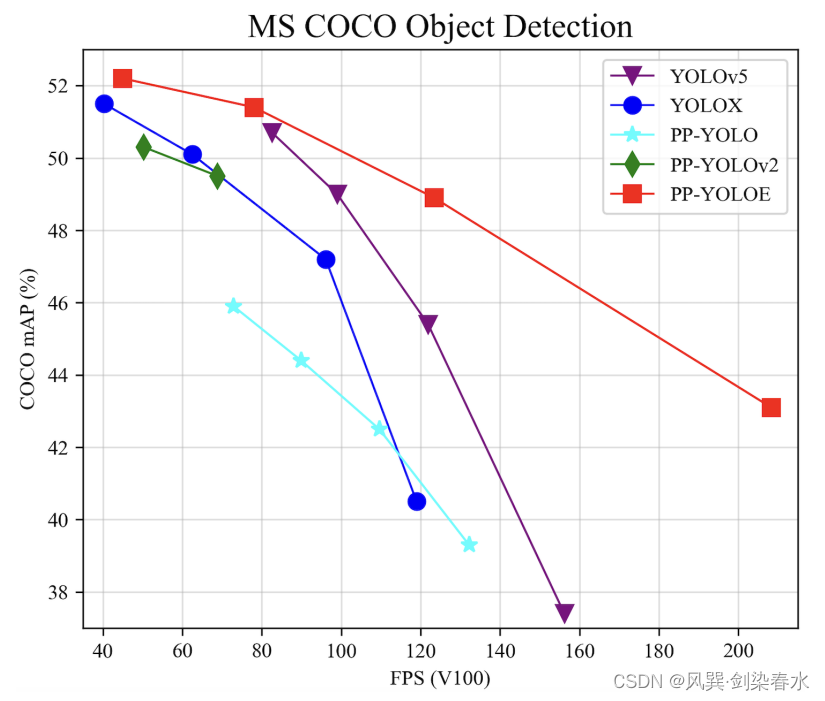
??本报告中,我们介绍了PP-YOLOE,这是一种具有高性能和友好部署的工业级先进目标检测器。我们在之前的PP-YOLOv2的基础上进行了优化,使用anchor-free范式,更强大的backbone和neck,配备了CSPRepResStage、ET-head和动态标签分配算法TAL。我们为不同的实践场景提供了s/m/l/x模型。在COCO testdev上,PP-YOLOE-l的mAP为51.4,使用Tesla V100具有78.1 FPS,与之前最先进的工业模型PP-YOLOv2和YOLOX相比,分别获得了(+1.9 AP,+13.35%提速)和(+1.3 AP,+24.96%提速)的显著提高。此外,在TensorRT和FP16-precision的支持下,PP-YOLOE推理速度达到了149.2 FPS。我们还进行了大量的实验来验证我们设计的有效性。
2.为什么会有PP-YOLOE
??百度在2021年4月提出了PP-YOLOv2(原文链接:https://arxiv.org/abs/2104.10419 ),性能超越同等参数的YOLOv4-CSP和YOLOv5-l,而随后7月份旷视科技的YOLOX一领风骚,这还能忍,必须走在YOLO系列的前端。受到YOLOX的启发,百度团队优化了PP-YOLOv2,顺手提出了PP-YOLOE。
??PP-YOLOv2的总体情况包括:
??(1)backbone:具有可变形卷积的ResNet50-vd;
??(2)neck:具有SPP层的PAN,DropBlock;
??(3)head:轻量级的IoU感知;
??(4)激活函数:在backbone中使用ReLU激活,neck中使用Mish激活;
??(5)标签分配:为每个ground truth目标分配一个anchor box;
??(6)损失:分类损失、回归损失、目标损失,IoU损失和IoU感知损失;
??COCO性能对比:
????PP-YOLOv2:49.1 mAP,68.9 FPS(Tesla V100)
????YOLOX:50.1 mAP,68.9 FPS(Tesla V100)
????PP-YOLOE-l:51.4mAP,78.1 FPS(Tesla V100)
3.PP-YOLOE的改进
(1)Anchor-free
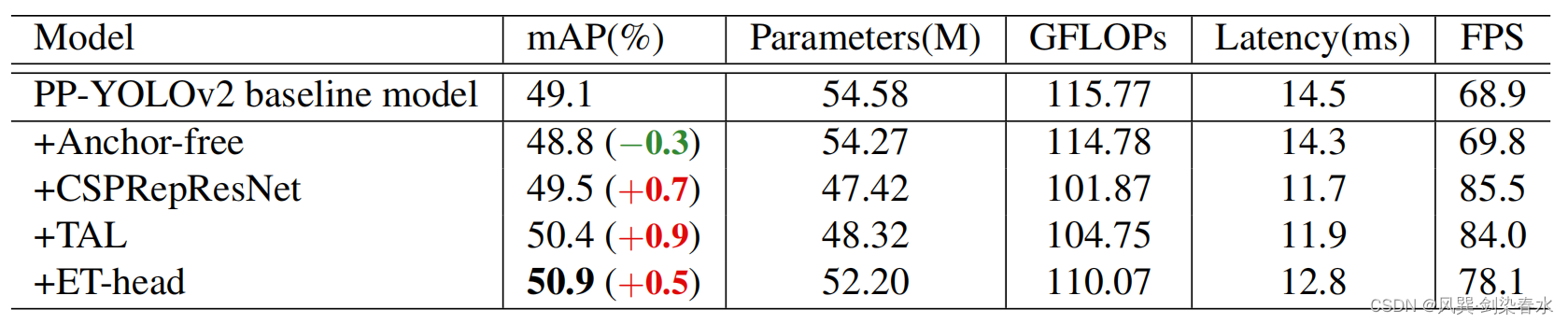
??Anchor-free方式最先在YOLOv1中出现,由于直接预测位置不准确,在后面的 YOLOv2、v3、v4和v5中均采用了Anchor方式。YOLOX中认为按聚类方式确定最优Anchor尺寸局限于特定领域,难以推广,此外还增加了head的复杂度与每张图像的预测数量,故采用了Anchor-free方式。
??同样,PP-YOLOE中亦采用Anchor-free方式。作者实验说采用Anchor-free方式加快了模型速度,但是精度相比于基线PP-YOLOv2降低了0.3mAP。
(2)RepResBlock
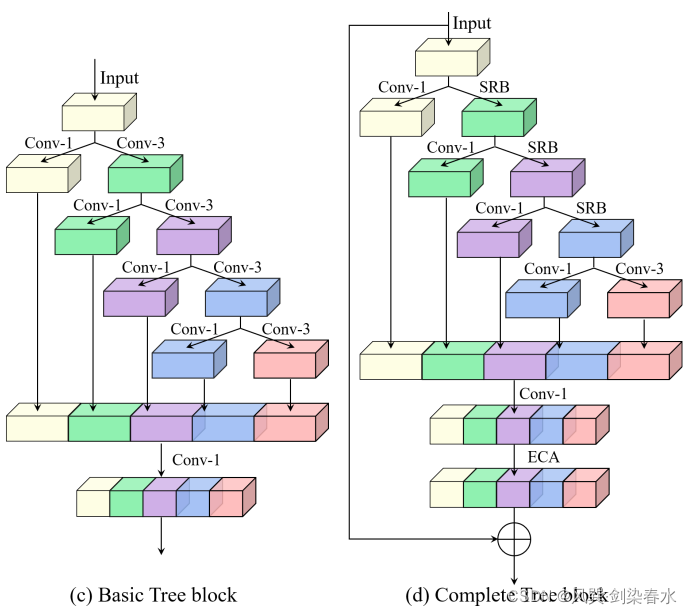
??启发于TreeBlock(原文链接:https://arxiv.org/abs/2109.12342 ),提出了一种新颖的RepResBlock,将残差连接和密集连接结合起来,用于backbone和neck中。RepResBlock可提升精度0.7mAP。
??原TreeBlock如下,唔…有点复杂,不过RepResBlock对其进行了简化。
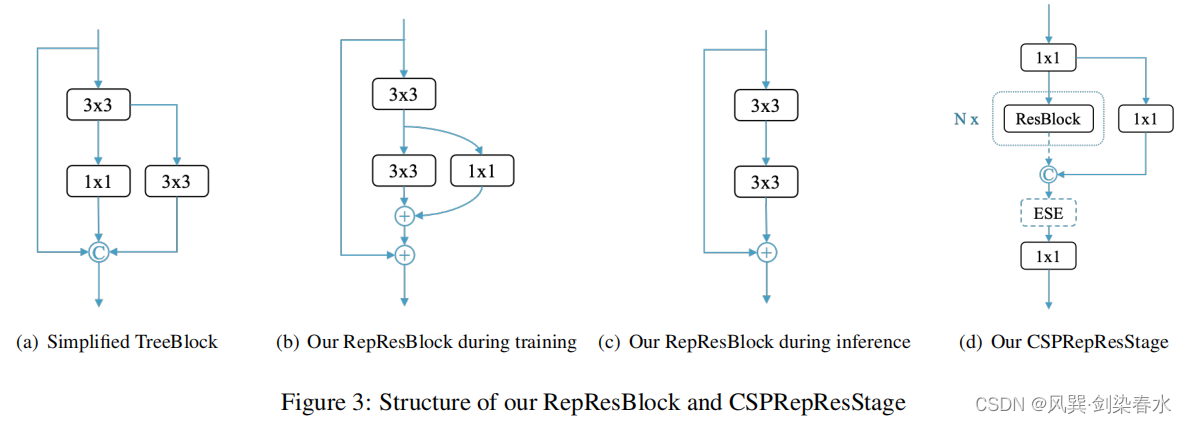
(3)Task Alignment Learning (TAL)
??标签分配策略是目标检测中的一个重要过程,YOLOX采用SimOTA分配策略。TAL由动态标签分配与任务对齐损失组成。动态标签分配意味着预测感知,根据预测,为每个ground truth目标分配动态的正样本。通过显式对齐两个任务,TAL可以同时获得最高的分类准确率和最精确的边界框。TAL可提升精度0.9mAP。
(4)Efficient Task-aligned Head (ET-head)
??为了解决分类任务与定位任务冲突的问题,YOLOX中采用了Decoupled head结构。但作者认为Decoupled head结构会使分类和定位任务分离独立,缺乏任务特异性学习,故提出了ET-head,ET-head可提升精度0.5mAP。
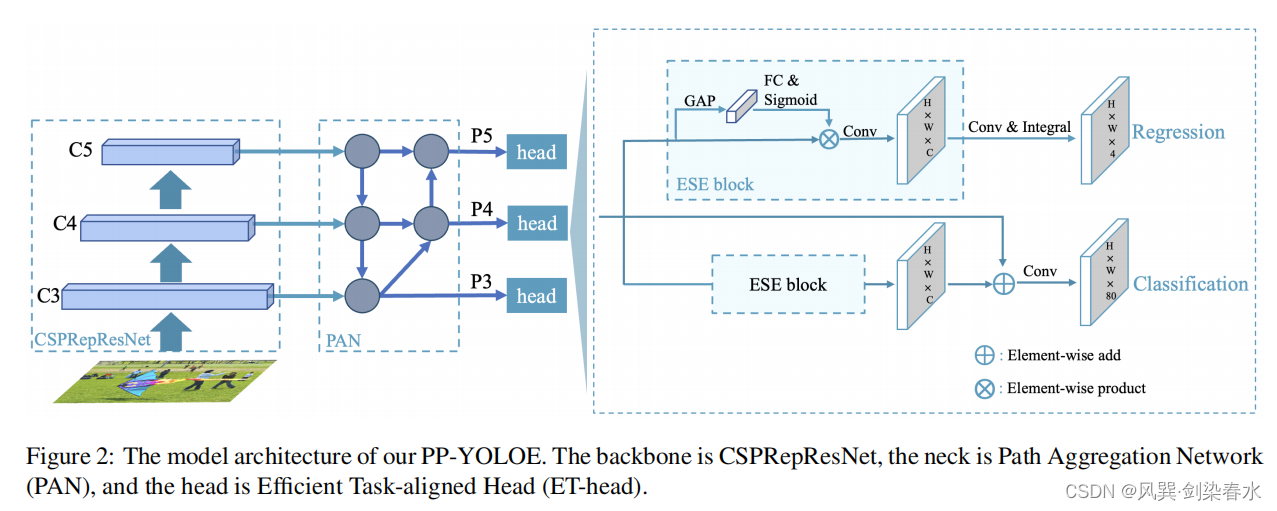
??对于分类和定位任务的学习,作者分别选择了变焦损失(VFL)和分布焦损失(DFL)。VFL使用target score对阳性样本的损失进行加权,使得具有高IoU的阳性样本对损失的贡献相对更大,也使得模型在训练时更加关注高质量的样本而不是低质量的样本。DFL是为了解决边界框表示不灵活的问题,提出了利用常规分布预测边界框的方法。
??模型损失函数为: