������Ϣ:Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction
������UC Berkeley��Sergey Levine�Ŷ�(Aviral Kumar)��2019�����,��������NIPS2019������,��һƪ��Scott Fujimoto��BCQ�㷨������,�����辶�������һ�־���Ľ��Offline RL���ۼ���������,�������۷����dz���ʵ,ͬʱ����Ҳȫ��opensource�˴���,�dz��Ƽ��о���
ժҪ:����Լ��(Policy constraint)��Ϊһ�ַdz���Ҫ��Լ�������㷺������ǿ��ѧϰ����,����onlineѧϰ��TRPO��PPO, ACKER��,�Լ�����ǿ��ѧϰ�е�BCQ�㷨��Ȼ��,��offline��,BCQʹ�õ�VAE�������Ŷ�������Ȼ�����extrapolation error,������һЩ��Ȼ������Ϊ���Էֲ���(Out-of- Distributuin, OOD)��״̬-�������ܺõ����,���IJ�����BEAR�㷨��һ���µIJ���Լ������취,��ͨ��һ�ֽ�Support-set matching���������learned policy��behavior policy֮��Ĺ�ϵ,�ﵽ��һ��state of the art��Ч����
����Ŀ¼
1. ǰ��(Լ�������ع�)
������ǿ��ѧϰ(Offline RL)��,����Լ��(Policy Constraint)����ͨ����Ϊ�Ĵ���:
- ��ʽf-ɢ��Լ��(Explict f-divergence constraint)
- ��ʽf-ɢ��Լ��(Implict f-divergence constraint)
- ���ָ��ʶ���Լ��(Integral probability metric, IPM)
- ���Գͷ�(policy penalty)
��ƪ���Ľ����Ȼع�һ��Online��TRPO��PPO��Լ������,�Լ�Offline��BCQ����,Ȼ����Ų��������ڲ���Լ����BEAR(Bootstrapping error accumulation reduction)�㷨��
1.1 TRPOԼ������
TRPO [1]Ϊ����ѧϰ���²���
��
n
e
w
\pi_{new}
��new? �;ɲ���
��
o
l
d
\pi_{old}
��old? ֮�䱣��һ����ȫ����,����ͨ��ʹ��KLɢ��ȥԼ������ѧϰ�ֲ�֮��ľ��������ѧϰ��Ч��,Objective����������ʾ:
maximize
?
��
E
s
��
��
��
old?
,
a
��
q
[
��
��
(
a
�O
s
)
q
(
a
�O
s
)
Q
��
old?
(
s
,
a
)
]
?subject?to?
E
s
��
��
��
old?
[
D
K
L
(
��
��
old?
(
?
�O
s
)
��
��
��
(
?
�O
s
)
)
]
��
��
\begin{aligned} &\underset{\theta}{\operatorname{maximize}} \mathbb{E}_{s \sim \rho_{\theta_{\text {old }}}, a \sim q}\left[\frac{\pi_{\theta}(a \mid s)}{q(a \mid s)} Q_{\theta_{\text {old }}}(s, a)\right] \\ &\text { subject to } \mathbb{E}_{s \sim \rho_{\theta_{\text {old }}}}\left[D_{\mathrm{KL}}\left(\pi_{\theta_{\text {old }}}(\cdot \mid s) \| \pi_{\theta}(\cdot \mid s)\right)\right] \leq \delta \end{aligned}
?��maximize?Es������old???,a��q?[q(a�Os)����?(a�Os)?Q��old???(s,a)]?subject?to?Es������old????[DKL?(����old???(?�Os)������?(?�Os))]����?
ͨ����ʽ�任,������Ҫ�����������
maximize
?
��
E
^
t
[
��
��
(
a
t
�O
s
t
)
��
��
old?
(
a
t
�O
s
t
)
A
^
t
?
��
K
L
[
��
��
old?
(
?
�O
s
t
)
,
��
��
(
?
�O
s
t
)
]
]
\underset{\theta}{\operatorname{maximize}} \hat{\mathbb{E}}_{t}\left[\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(a_{t} \mid s_{t}\right)} \hat{A}_{t}-\beta \mathrm{KL}\left[\pi_{\theta_{\text {old }}}\left(\cdot \mid s_{t}\right), \pi_{\theta}\left(\cdot \mid s_{t}\right)\right]\right]
��maximize?E^t?[����old???(at?�Ost?)����?(at?�Ost?)?A^t??��KL[����old???(?�Ost?),����?(?�Ost?)]]
��ϸ���������: ���ǿ��ѧϰϵ��(15): TRPO�㷨ԭ����Tensorflowʵ��
1.2 PPOԼ������

Ϊ�˽��1.1 TRPO�е�
��
\beta
�� ����ѡ�������,����ֱ�Ӷ�ƽ���ʹ����clip������
L
C
L
I
P
(
��
)
=
E
^
t
[
min
?
(
r
t
(
��
)
A
^
t
,
clip
?
(
r
t
(
��
)
,
1
?
?
,
1
+
?
)
A
^
t
)
]
L^{C L I P}(\theta)=\hat{\mathbb{E}}_{t}\left[\min \left(r_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right]
LCLIP(��)=E^t?[min(rt?(��)A^t?,clip(rt?(��),1??,1+?)A^t?)]

1.3 BCQԼ������


�����������: ����ǿ��ѧϰ(Offline RL)ϵ��3: (�㷨ƪ)BCQ�㷨ԭ����ʵ�����
����������һƪ����BCQ�㷨�����ϵĹ���,BCQ�㷨Ϊ�˽��extrapolation error��Ҫ����һ����,��ͨ��VAE�������Ŷ�����������ѵ������(����),ʹ����ӽ���Ϊ����(����ô��ģ��ѧϰ�Ļ���),��������ȫ����������Ϊ���Բ�һ����,���һ��trajectory����ǰ��δ�������,���ܾͻ�û��ѧϰ��
2. Offline RL������Դ
2.1 �ֲ�ƫ��(distribution shift)
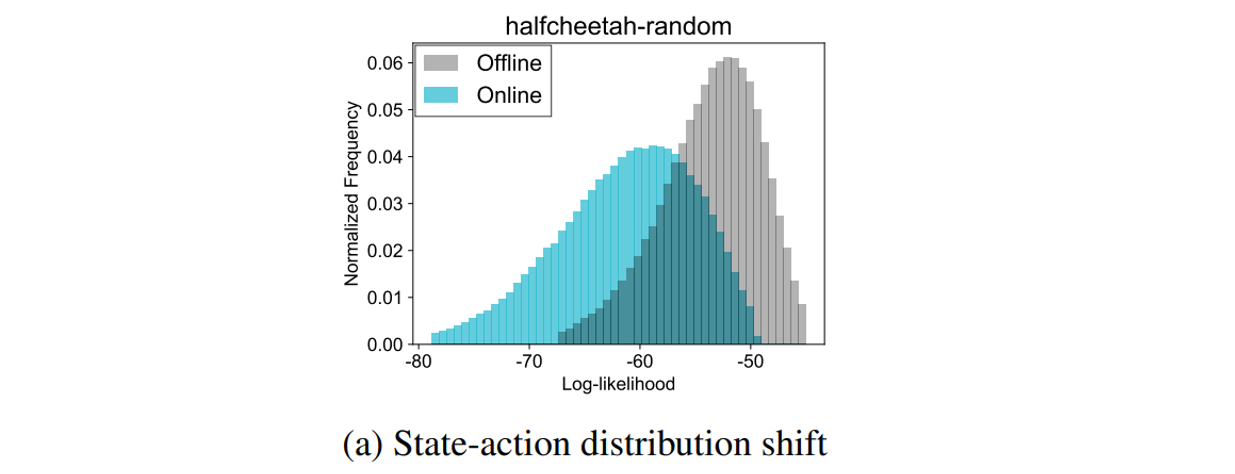
�ֲ�ƫ������Ҫ��ԭ����learned policy �� behavior policy֮���ƫ��(��ͼ�����ǿ��������Ŀ�������֮�������),��Ҳ��offlineRL�����Online RL�ڲ��ܽ���ѧϰ���������ɵġ�
2.2 OOD(out-of-distribution) action����
OOD������Offline RL�зdz�����,�Ŀ�������Ϊ״̬-�����Կ��ܲ������ǵ�offline Dataset��,��Ӧ�ķֲ�Ҳһ��,��ѧϰ�ֲ�Զ��(far outside)ѵ��(training distribution)�ֲ�֮�⡣
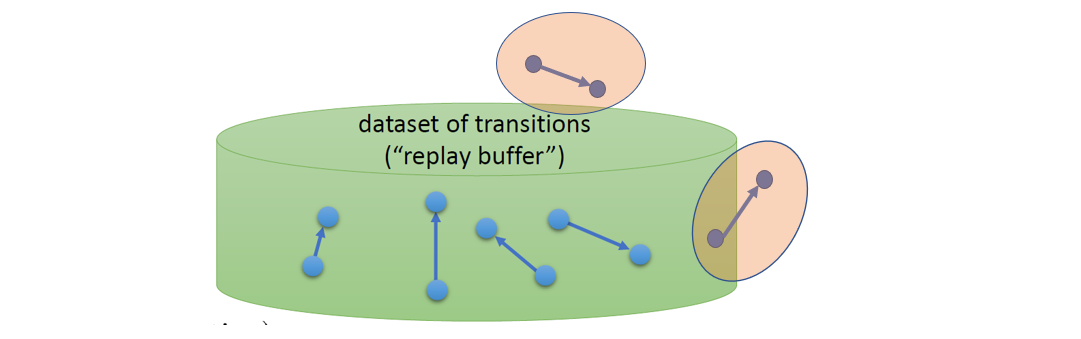
��ôѵ�����Ż���������:
�����ͼ,��ʵ��������������,��һֱ�۵��뷨�����������ݼ�������,�����ݼ������ܰ���ѵ���ֲ�,����ѧϰ�ֲ��������ܻ��ڷ�Χ��,Ȼ���������������Ч:

������ʵ����ʹ���˴�С��һ��������ʵ��,���������ʹ����train samples, �㷨�����ܲ�û�еõ���Ч����,ͬʱҲ��������һ���ۼ��������:

����Qֵ���Ӹ߲���,��ʲôԭ����ɵ�?
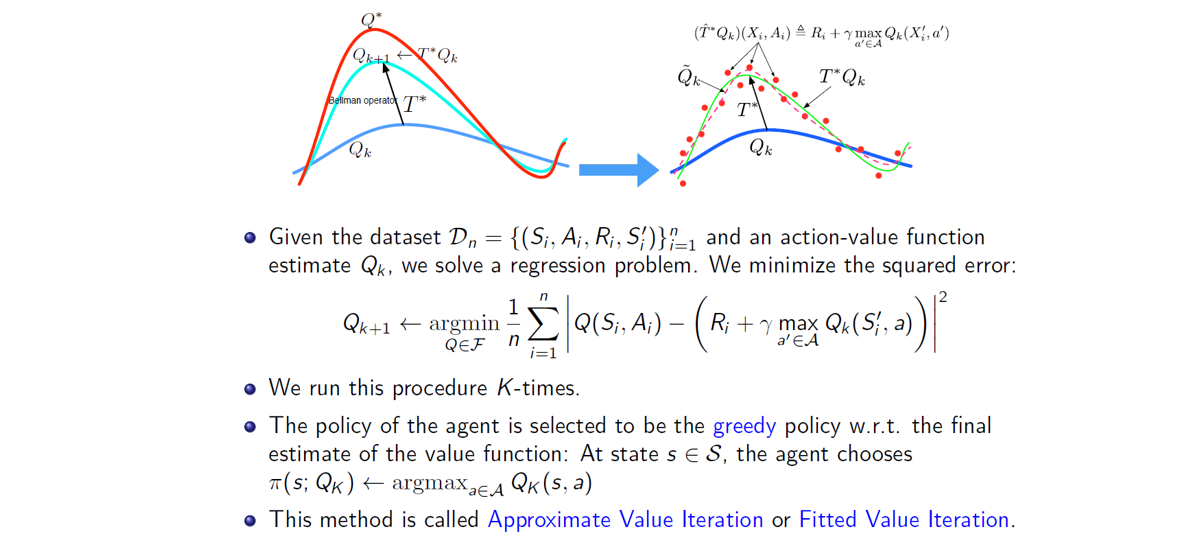
2.3 ���������(Bellman error)
����DZ��ĵĺ���������,���ǿ��ѧϰ�ж�̬��滮(MC,TD)����ĵľ���Q����,����֪����Q-learning��ѧϰ��ʱ��,Ŀ�꺯��Q�ļ���ͨ���������Ծ�(bootstrapping)�ķ�ʽ,��ѵ�����ֲ���ȥ���������,������OOD֮�������,����������̵�error�����ۻ�,���յ�������ƫ��ѧϰ���ԡ�
������Online RL��֪��,����
Q
Q
Q ����
Q
?
Q^{*}
Q? ��ѭ���ű���������,������ʾ:
Q
?
=
T
?
Q
?
;
(
T
?
Q
^
)
(
s
,
a
)
:
=
R
(
s
,
a
)
+
��
E
T
(
s
��
�O
s
,
a
)
[
max
?
a
��
Q
^
(
s
��
,
a
��
)
]
Q^{*}=\mathcal{T}^{*} Q^{*} \quad ; \quad\left(\mathcal{T}^{*} \hat{Q}\right)(s, a):=R(s, a)+\gamma \mathbb{E}_{T\left(s^{\prime} \mid s, a\right)}\left[\max _{a^{\prime}} \hat{Q}\left(s^{\prime}, a^{\prime}\right)\right]
Q?=T?Q?;(T?Q^?)(s,a):=R(s,a)+��ET(s���Os,a)?[a��max?Q^?(s��,a��)]
Ȼ��,ǿ��ѧϰ��Ӧ����С���õ�ʽ�����Ҳ�֮���ƽ����,Ҳ��Ϊ������������� (MSBE),�õ�:
Q : = arg ? min ? Q ^ E s �� D , a �� �� ( a �O s ) [ ( Q ^ ( s , a ) ? ( T ? Q ^ ) ( s , a ) ) 2 ] Q:=\arg \min _{\hat{Q}} \mathbb{E}_{s \sim \mathcal{D}, a \sim \beta(a \mid s)}\left[\left(\hat{Q}(s, a)-\left(\mathcal{T}^{*} \hat{Q}\right)(s, a)\right)^{2}\right] Q:=argQ^?min?Es��D,a����(a�Os)?[(Q^?(s,a)?(T?Q^?)(s,a))2]
MSBE ����������
��
(
a
�O
s
)
\beta(a|s)
��(a�Os) ���ɵ����ݼ�
D
D
D �е�ת����������С���� ������С�� MSBE ��Ӧ���мල�Ļع�����,���ûع��Ŀ�걾���Ǵӵ�ǰ
Q
Q
Q ���������еó��ġ����Ƕ��ڵ���
k
k
k �ε�Q-learning��˵,�����(error) ���Զ���Ϊ:
��
k
(
s
,
a
)
=
�O
Q
k
(
s
,
a
)
?
Q
?
(
s
,
a
)
�O
\zeta_{k}(s, a)=\left|Q_{k}(s, a)-Q^{*}(s, a)\right|
��k?(s,a)=�OQk?(s,a)?Q?(s,a)�O
���е�ǰ�ı��������(Bellman error)Ϊ:
��
k
(
s
,
a
)
=
�O
Q
k
(
s
,
a
)
?
T
Q
k
?
1
(
s
,
a
)
�O
\delta_{k}(s, a)=\left|Q_{k}(s, a)-\mathcal{T} Q_{k-1}(s, a)\right|
��k?(s,a)=�OQk?(s,a)?TQk?1?(s,a)�O
��ô���ǾͿ��Եó����½���:
��
k
(
s
,
a
)
��
��
k
(
s
,
a
)
+
��
max
?
a
��
E
s
��
[
��
k
?
1
(
s
��
,
a
��
)
]
\zeta_{k}(s, a) \leq \delta_{k}(s, a)+\gamma \max _{a^{\prime}} \mathbb{E}_{s^{\prime}}\left[\zeta_{k-1}\left(s^{\prime}, a^{\prime}\right)\right]
��k?(s,a)����k?(s,a)+��a��max?Es��?[��k?1?(s��,a��)]
����˵,��һ��״̬-�����ֲ�����OOD֮��ʱ,������ʵ��ϣ�� �� k ( s , a ) \delta_{k}(s, a) ��k?(s,a) �ܸ�,��Ϊ���ǵ��Ż�Ŀ���Dz��Ͻ����ڷֲ�֮��IJ��Էֲ���ѵ���ֲ�������С����Ϊ�˻����������,���������һ���������������ѧϰ��������Ķ�������ѵ���ֲ���֧�ż�(Support-set)����
��ν��Support-set, ��ʵ����"ѧϰ���� �� ( a �O s ) \pi(a \mid s) ��(a�Os) ֻ������Ϊ���� �� ( a �O s ) \beta(a \mid s) ��(a�Os) ���ܶȴ�����ֵ ? a , �� ( a �O s ) �� �� ? �� ( a �O s ) = 0 \forall a, \beta(a \mid s) \leq \varepsilon \Longrightarrow \pi(a \mid s)=0 ?a,��(a�Os)����?��(a�Os)=0,�����Ƕ��ܶ� �� ( a �O s ) \pi(a \mid s) ��(a�Os) �� �� ( a �O s ) \beta(a \mid s) ��(a�Os) ��ֵ�Ľӽ�Լ����"
ԭ��:

�������ǽ�����ӽ���һ�� �ֲ�ƥ��(Distribution-matching �� ֧�ż�ƥ��(Support-set matching) ������,�Լ�ԭ����
3. ��һ������ԭ�������ʼ
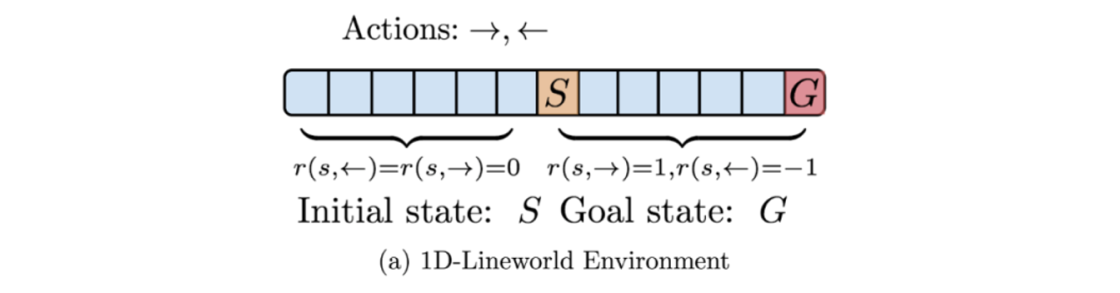
����һά��Lineworld Environment����,���Ǵ� S S S ��������� G G G ��,��������Ϊ�����͡����ҡ�����,��Ӧ�Ľ�������ͼ���б�ǡ�
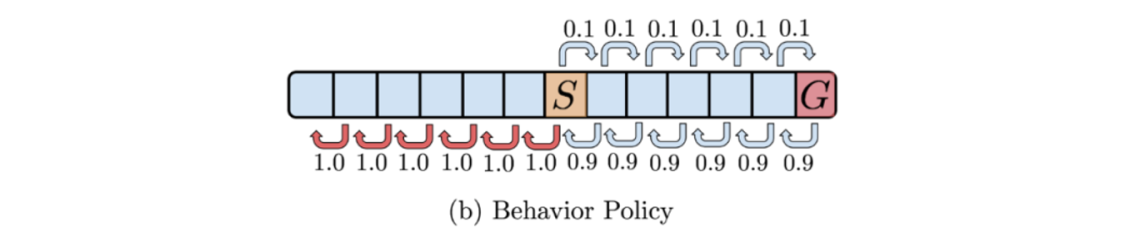
��ô,��Ϊ������
S
S
S ��
G
G
G ֮���״̬��ִ�д��Ŷ���,������Ϊ 0.9,���Ƕ���
��
\leftarrow
�� ��
��
\rightarrow
�� ��״̬���ڷֲ���(in-distribution)��
��������ԭ��

3.1 Distribution-matching

����ͼ,�ֲ�ƥ��Լ��(distribution matching constraint)��ѧϰ���Կ�����������ŵ�,��ʵ��,ͨ���Ƴ��ò��ԴﵽĿ�� G �ĸ��ʷdz�С,�������Ż����Ľ��������� 0 �ϴ�
3.2 Support-constraint

Ȼ��,��support-constraint��,���߱���֧��Լ�����Իָ�����Ϊ 1 �����Ų���(��ʵԭ��ܼ�,������ֵ
?
a
,
��
(
a
�O
s
)
��
��
?
��
(
a
�O
s
)
=
0
\forall a, \beta(a \mid s) \leq \varepsilon \Longrightarrow \pi(a \mid s)=0
?a,��(a�Os)����?��(a�Os)=0 ��ԭ��, ֻҪ������ѵ����Ϊ���Էֲ���֧�ּ��ھͿ���)��
��ôΪʲôDistribution-matching�������ʧ��?
- ����ͷ����ϸ�ִ��,��ô�����彫������ S S S �� G G G ֮���״̬����Ҫִ�д���Ķ��� �� \leftarrow ��,���´�����Ϊ��
- ����ͷ�û���ϸ�ִ��,Ϊ��ʵ�ֱ���Ϊ���Ը��õIJ���,�����彫ʹ�� OOD֮���action �� \rightarrow ���� S S S ����״ִ̬��backups,��Щbackups ���ջ�Ӱ�� ״̬S�µ�Qֵ�����������²���ȷ�� Q ����,�Ӷ����´���IJ��ԡ��������Ǵ� S ��ʼ�����ƶ��������� G �ƶ��IJ���,��Ϊ OOD ����backups��߹�ƫ������Q-learning ���ܻ�ʹ״̬ S �Ķ��� �� \leftarrow �� ����������ȡ������ͼ��ʾ,һЩ״̬��Ҫǿ�ͷ�/Լ��(�Է�ֹ OOD backups),������״̬��Ҫ���ͷ�/Լ��(��ʵ��������)����ʹ�ֲ�ƥ��������,����,����ͨ����ͳ�ķֲ�ƥ����ʵ�ַ�����
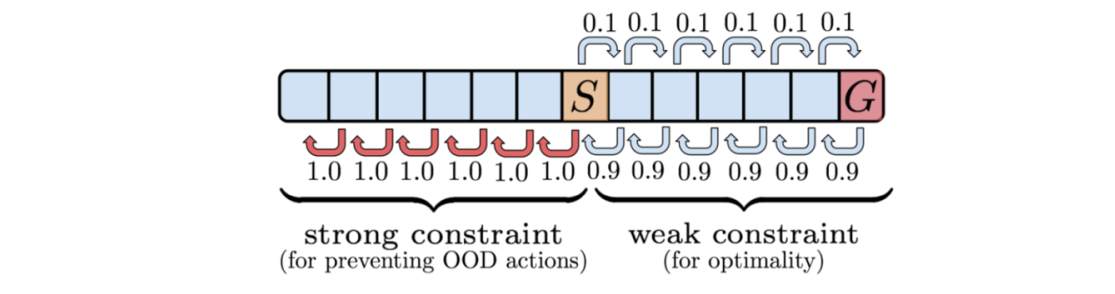
ͨ����������,���ǵó�һ������:����ϣ��������ѧϰ���Ժ���Ϊ����Խ��Խ��,����ѧϰ�����ܹ�����Ϊ���Ե�֧�ż��ķ�Χ��ȥ�����Ż�, ���ѧϰ���Ժ���Ϊ�������ӽ��Dz�����Behavior clone��,��offline������ȥ�ƽ�online,����������Ȼ���ڡ�
��ͼ���ǹ���Distribution-matching ��support constraintѡ����������

��ͼ�����ǿ��Կ���:�Ժ�ɫ����Ϊ���� �� \beta �� Ϊ��,��distribution-matching���������ɫ��ѧϰ�������,����support-matching�л�ɫ�Ķ��ǿ���ƥ���learned policy, ���Ը�ͨ�á�
��ôsupport-set matching��ͨ��,��������ômatching����?�������Ǵ����ĵ����۲��ֿ�ʼ������
4. ������Ƽ�����(����:�����Ķ�)
4.1 Support-set Matching(֧�ż�ƥ�䷽��)
4.1.1 ֧�ż�ƥ��ԭ��
��һ��: ������Լ����弰����,����Distribution-constraint operators����,������ʾ:
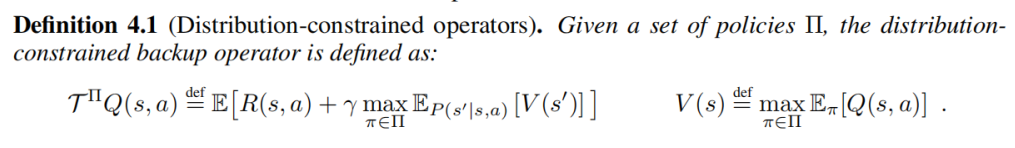

��������ؼ��������¼����ط�:
- ������һ�����Լ� �� \prod �� ,�Ҷ����ռ� A �� �� A \in \prod A����,�����Ƕ������
- ����ԭʼ��MDP�������¶�����һ���µ�MDP" ����,ԭ����bellman operatorһ��,ͬ�������˲�����ȥ֤�������ԡ�
Ϊ�˷����ڽ��������ִ��backup������(suboptimality) ����,���������������:
- ����ƫ��(suboptimality bias), Ҳ�������ŵ�ѧϰ�����������Ϊ����֧�ż�֮��Ļ�,��Ȼ�ܹ��ҵ����Ų��ԡ�
- ���ų���(suboptimality constant),�ֲ�ƫ�ơ�OOD֮��Ĵ�������,���ų����൱������һ����(which measures how far �� ? \pi^{*} ��? is from �� \prod ��), �� �� ( �� ) \alpha(\Pi) ��(��) ԽС,policy set �� \prod �� ����optimal policy �� ? \pi^{*} ��? �ľ���ԽС����
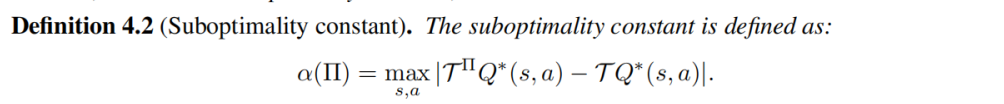

���ﶨ����һ��Concentrability,�� C ( �� ) C(\Pi) C(��)ԽС,��˵��policy set �� \prod �� �е�policy �� behavior policy �� \beta �� Խ���ơ�
�ڶ���:������߸�����һ���߽�(bound)


֤����������:

�����[Error Bounds for Approximate Value Iteration] �����
�� ? : = { �� �O �� ( a �O s ) = 0 ?whenever? �� ( a �O s ) �� ? } \Pi_{\epsilon}:=\{\pi \mid \pi(a \mid s)=0 \text { whenever } \beta(a \mid s) \leq \epsilon\} ��??:={���O��(a�Os)=0?whenever?��(a�Os)��?}
We choose policies only lying in high support regions of the behaviour policy.
Allows for a tradeoff between: Keeping close to the data (minimizing amount of propagated error) Having freedom to find the optimal policy

�������߲��Ƕ����в���ִ�����,���ǶԼ��� Pi_eps ִ���������ֵ,Ϊ��ʵ��ִ�д˲���,ʹ��ִ��֧��ƥ���Լ����
��������ԭ����:
We change the policy improvement step, where instead of performing a maximization over all policies, we perform the restricted max over the set �� e p s \pi_{eps} ��eps? and in order to do this practically, we use a constrained formulation, where we use a constraint that performs support matching. We constrain the maximum mean discrepancy distance between the dataset and the actor to a maximal limit, using samples.
4.1.2 ΪʲôҪ�� �� ? \Pi_{\epsilon} ��?? ѡȡ����?

ͨ�����ϵķ���,�������ջ���Ϊһ�������������:
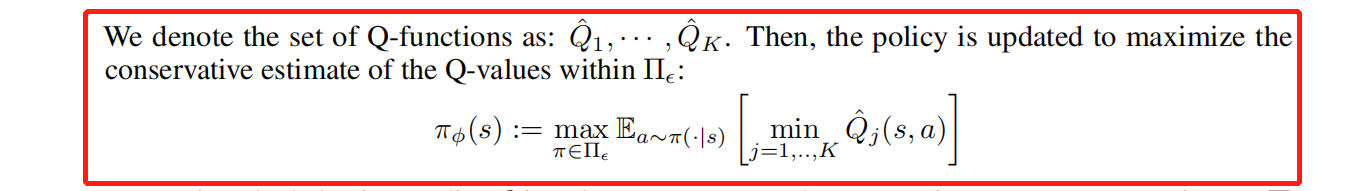
4.2 Maximum Mean Discrepancy (MMD)
4.2.1 MMDԭ��
MMD [A Kernel Two-Sample Test] ������һ��ͳ�Ʋ�����ȷ�����������Ƿ����Բ�ͬ�ķֲ�,����ͳ���������� kernel Hilbertspace (RKHS) �ĵ�λ���к���������������졣

4.2.2 MMD�������
def gaussian_kernel(x, y, sigma=0.1):
return exp(-(x - y).pow(2).sum() / (2 * sigma.pow(2)))
def compute_mmd(x, y):
k_x_x = gaussian_kernel(x, x)
k_x_y = gaussian_kernel(x, y)
k_y_y = gaussian_kernel(y, y)
return sqrt(k_x_x.mean() + k_y_y.mean() - 2*k_x_y.mean())
4.2.3 ��KL divergence������
4.3 ˫�ݶ��½�(Dual Gradient Descent)(������)
4.3.1 DGDԭ����ͼ��[Dual Gradient Descent]
˫�ݶ��½���һ����Լ���������Ż�Ŀ������з����� ��ǿ��ѧϰ��,�������������������õľ��ߡ�
5. BEAR�㷨ִ�й���

��ע���ﻹ������һ���汾

6. ���ֽ������
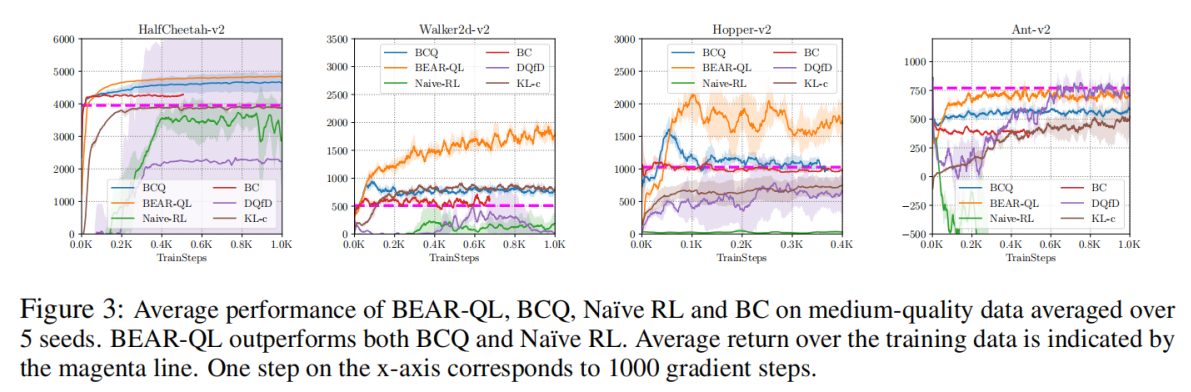
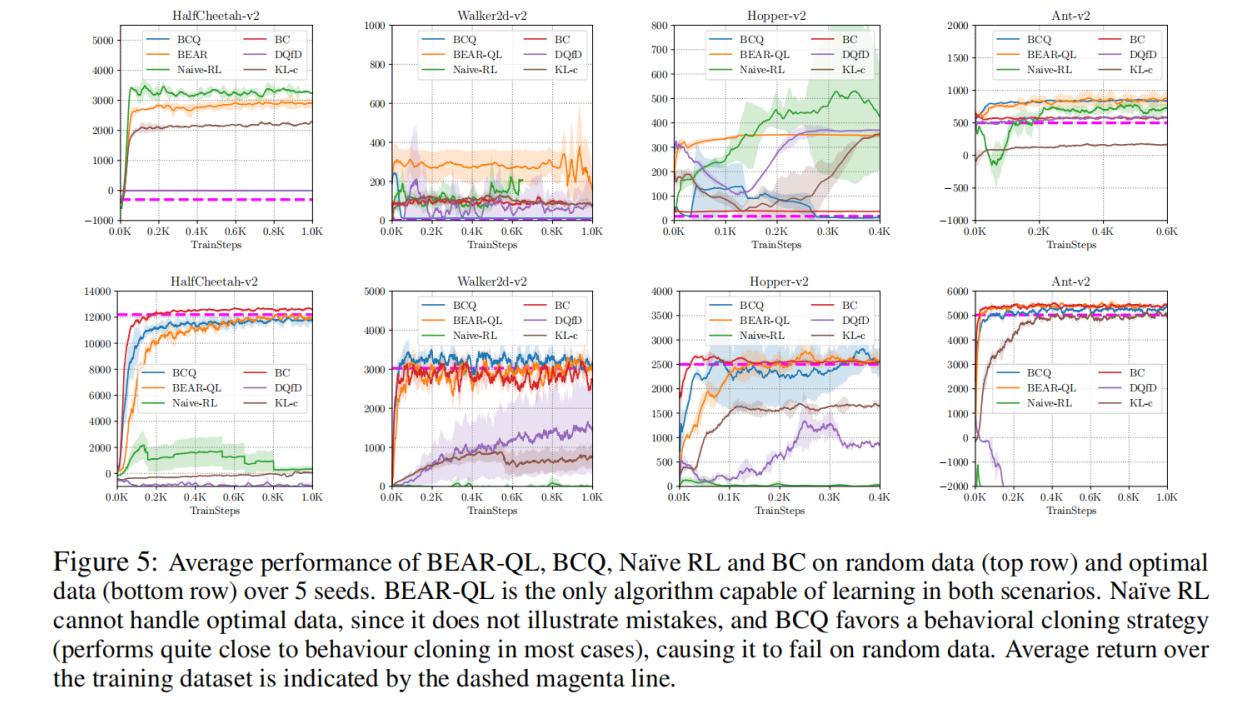
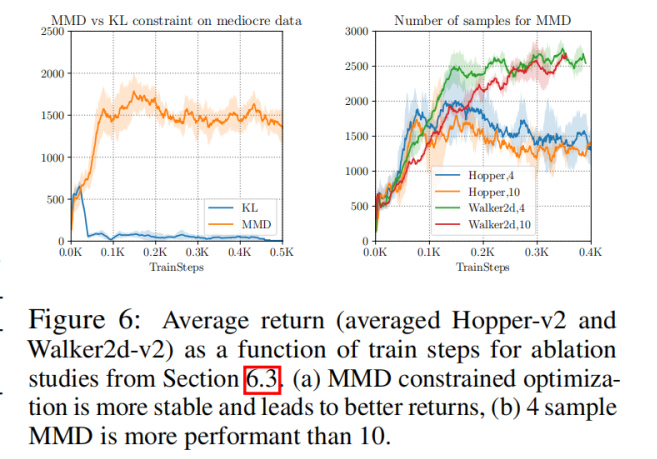
7. Pytorch����ʵ�ֲ���dz��
��������ԭ���߿�Դ [Github]
7.1 Installing & running
python main.py --buffer_name=buffer_walker_300_curr_action.pkl --eval_freq=1000 --algo_name=BEAR
--env_name=Walker2d-v2 --log_dir=data_walker_BEAR/ --lagrange_thresh=10.0
--distance_type=MMD --mode=auto --num_samples_match=5 --lamda=0.0 --version=0
--mmd_sigma=20.0 --kernel_type=gaussian --use_ensemble_variance="False"
7.2 MMD&KL loss
def mmd_loss_laplacian(self, samples1, samples2, sigma=0.2):
"""MMD constraint with Laplacian kernel for support matching"""
# sigma is set to 10.0 for hopper, cheetah and 20 for walker/ant
diff_x_x = samples1.unsqueeze(2) - samples1.unsqueeze(1) # B x N x N x d
diff_x_x = torch.mean((-(diff_x_x.abs()).sum(-1)/(2.0 * sigma)).exp(), dim=(1,2))
diff_x_y = samples1.unsqueeze(2) - samples2.unsqueeze(1)
diff_x_y = torch.mean((-(diff_x_y.abs()).sum(-1)/(2.0 * sigma)).exp(), dim=(1, 2))
diff_y_y = samples2.unsqueeze(2) - samples2.unsqueeze(1) # B x N x N x d
diff_y_y = torch.mean((-(diff_y_y.abs()).sum(-1)/(2.0 * sigma)).exp(), dim=(1,2))
overall_loss = (diff_x_x + diff_y_y - 2.0 * diff_x_y + 1e-6).sqrt()
return overall_loss
def mmd_loss_gaussian(self, samples1, samples2, sigma=0.2):
"""MMD constraint with Gaussian Kernel support matching"""
# sigma is set to 10.0 for hopper, cheetah and 20 for walker/ant
diff_x_x = samples1.unsqueeze(2) - samples1.unsqueeze(1) # B x N x N x d
diff_x_x = torch.mean((-(diff_x_x.pow(2)).sum(-1)/(2.0 * sigma)).exp(), dim=(1,2))
diff_x_y = samples1.unsqueeze(2) - samples2.unsqueeze(1)
diff_x_y = torch.mean((-(diff_x_y.pow(2)).sum(-1)/(2.0 * sigma)).exp(), dim=(1, 2))
diff_y_y = samples2.unsqueeze(2) - samples2.unsqueeze(1) # B x N x N x d
diff_y_y = torch.mean((-(diff_y_y.pow(2)).sum(-1)/(2.0 * sigma)).exp(), dim=(1,2))
overall_loss = (diff_x_x + diff_y_y - 2.0 * diff_x_y + 1e-6).sqrt()
return overall_loss
def kl_loss(self, samples1, state, sigma=0.2):
"""We just do likelihood, we make sure that the policy is close to the
data in terms of the KL."""
state_rep = state.unsqueeze(1).repeat(1, samples1.size(1), 1).view(-1, state.size(-1))
samples1_reshape = samples1.view(-1, samples1.size(-1))
samples1_log_pis = self.actor.log_pis(state=state_rep, raw_action=samples1_reshape)
samples1_log_prob = samples1_log_pis.view(state.size(0), samples1.size(1))
return (-samples1_log_prob).mean(1)
7.3 BEAR train
def train(self, replay_buffer, iterations, batch_size=100, discount=0.99, tau=0.005):
for it in range(iterations):
state_np, next_state_np, action, reward, done, mask = replay_buffer.sample(batch_size)
state = torch.FloatTensor(state_np).to(device)
action = torch.FloatTensor(action).to(device)
next_state = torch.FloatTensor(next_state_np).to(device)
reward = torch.FloatTensor(reward).to(device)
done = torch.FloatTensor(1 - done).to(device)
mask = torch.FloatTensor(mask).to(device)
# Train the Behaviour cloning policy to be able to take more than 1 sample for MMD
recon, mean, std = self.vae(state, action)
recon_loss = F.mse_loss(recon, action)
KL_loss = -0.5 * (1 + torch.log(std.pow(2)) - mean.pow(2) - std.pow(2)).mean()
vae_loss = recon_loss + 0.5 * KL_loss
self.vae_optimizer.zero_grad()
vae_loss.backward()
self.vae_optimizer.step()
# Critic Training: In this step, we explicitly compute the actions
with torch.no_grad():
# Duplicate state 10 times (10 is a hyperparameter chosen by BCQ)
state_rep = torch.FloatTensor(np.repeat(next_state_np, 10, axis=0)).to(device)
# Compute value of perturbed actions sampled from the VAE
target_Qs = self.critic_target(state_rep, self.actor_target(state_rep))
# Soft Clipped Double Q-learning
target_Q = 0.75 * target_Qs.min(0)[0] + 0.25 * target_Qs.max(0)[0]
target_Q = target_Q.view(batch_size, -1).max(1)[0].view(-1, 1)
target_Q = reward + done * discount * target_Q
current_Qs = self.critic(state, action, with_var=False)
if self.use_bootstrap:
critic_loss = (F.mse_loss(current_Qs[0], target_Q, reduction='none') * mask[:, 0:1]).mean() +\
(F.mse_loss(current_Qs[1], target_Q, reduction='none') * mask[:, 1:2]).mean()
# (F.mse_loss(current_Qs[2], target_Q, reduction='none') * mask[:, 2:3]).mean() +\
# (F.mse_loss(current_Qs[3], target_Q, reduction='none') * mask[:, 3:4]).mean()
else:
critic_loss = F.mse_loss(current_Qs[0], target_Q) + F.mse_loss(current_Qs[1], target_Q) #+ F.mse_loss(current_Qs[2], target_Q) + F.mse_loss(current_Qs[3], target_Q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Action Training
# If you take less samples (but not too less, else it becomes statistically inefficient), it is closer to a uniform support set matching
num_samples = self.num_samples_match
sampled_actions, raw_sampled_actions = self.vae.decode_multiple(state, num_decode=num_samples) # B x N x d
actor_actions, raw_actor_actions = self.actor.sample_multiple(state, num_samples)# num)
# MMD done on raw actions (before tanh), to prevent gradient dying out due to saturation
if self.use_kl:
mmd_loss = self.kl_loss(raw_sampled_actions, state)
else:
if self.kernel_type == 'gaussian':
mmd_loss = self.mmd_loss_gaussian(raw_sampled_actions, raw_actor_actions, sigma=self.mmd_sigma)
else:
mmd_loss = self.mmd_loss_laplacian(raw_sampled_actions, raw_actor_actions, sigma=self.mmd_sigma)
action_divergence = ((sampled_actions - actor_actions)**2).sum(-1)
raw_action_divergence = ((raw_sampled_actions - raw_actor_actions)**2).sum(-1)
# Update through TD3 style
critic_qs, std_q = self.critic.q_all(state, actor_actions[:, 0, :], with_var=True)
critic_qs = self.critic.q_all(state.unsqueeze(0).repeat(num_samples, 1, 1).view(num_samples*state.size(0), state.size(1)), actor_actions.permute(1, 0, 2).contiguous().view(num_samples*actor_actions.size(0), actor_actions.size(2)))
critic_qs = critic_qs.view(self.num_qs, num_samples, actor_actions.size(0), 1)
critic_qs = critic_qs.mean(1)
std_q = torch.std(critic_qs, dim=0, keepdim=False, unbiased=False)
if not self.use_ensemble:
std_q = torch.zeros_like(std_q).to(device)
if self.version == '0':
critic_qs = critic_qs.min(0)[0]
elif self.version == '1':
critic_qs = critic_qs.max(0)[0]
elif self.version == '2':
critic_qs = critic_qs.mean(0)
# We do support matching with a warmstart which happens to be reasonable around epoch 20 during training
if self.epoch >= 20:
if self.mode == 'auto':
actor_loss = (-critic_qs +\
self._lambda * (np.sqrt((1 - self.delta_conf)/self.delta_conf)) * std_q +\
self.log_lagrange2.exp() * mmd_loss).mean()
else:
actor_loss = (-critic_qs +\
self._lambda * (np.sqrt((1 - self.delta_conf)/self.delta_conf)) * std_q +\
100.0*mmd_loss).mean() # This coefficient is hardcoded, and is different for different tasks. I would suggest using auto, as that is the one used in the paper and works better.
else:
if self.mode == 'auto':
actor_loss = (self.log_lagrange2.exp() * mmd_loss).mean()
else:
actor_loss = 100.0*mmd_loss.mean()
std_loss = self._lambda*(np.sqrt((1 - self.delta_conf)/self.delta_conf)) * std_q.detach()
self.actor_optimizer.zero_grad()
if self.mode =='auto':
actor_loss.backward(retain_graph=True)
else:
actor_loss.backward()
# torch.nn.utils.clip_grad_norm(self.actor.parameters(), 10.0)
self.actor_optimizer.step()
# Threshold for the lagrange multiplier
thresh = 0.05
if self.use_kl:
thresh = -2.0
if self.mode == 'auto':
lagrange_loss = (-critic_qs +\
self._lambda * (np.sqrt((1 - self.delta_conf)/self.delta_conf)) * (std_q) +\
self.log_lagrange2.exp() * (mmd_loss - thresh)).mean()
self.lagrange2_opt.zero_grad()
(-lagrange_loss).backward()
# self.lagrange1_opt.step()
self.lagrange2_opt.step()
self.log_lagrange2.data.clamp_(min=-5.0, max=self.lagrange_thresh)
# Update Target Networks
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
�����
[1]. Aviral Kumar, Justin Fu, George Tucker, Sergey Levine: ��Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction��, 2019; arXiv:1906.00949.
[2]. Aviral Kumar: Data-Driven Deep Reinforcement Learning, [EB/OL]Blog, Dec 5, 2019.