��������:https://arxiv.org/pdf/2111.14556.pdf
��������֤����k��k�Ĵ�ͳ�������Էֽ�Ϊ
k
2
k^2
k2��������1��1������Ȼ��,��selfattentionģ����queries, keys, and values��ͶӰ����Ϊ���1��1����,Ȼ�����ע��Ȩ�غ�values�ľۺϡ����,����ģ��ĵ�һ�ΰ������ƵIJ���������Ҫ����,��ڶ������,��һ�εļ��㸴�Ӷ�ռ������λ(ͨ����С��ƽ��)����һ�۲������Դ�ʹ�����ֿ��ƽ�Ȼ��ͬ�ķ�ʽ���������,��һ�ּ���������ע���������ܾ���(ACmix)�ô��Ļ��ģ��,ͬʱ�봿����������ע������Ӧģ�����,������С�ļ��㿪����
һ�����¸Ľ�
���ǵ���������ע�����IJ�ͬ�ͻ�������,ͨ��������Щģ��,�п��ܴ������ַ�ʽ�л��档���ڽε��о�,����SENet,CBAM,������ע�������ƿ�����Ϊ����ģ�����ǿ�����,��ע����ģ�鱻������Ϊ������ģ�������CNNģ���еĴ�ͳ����,����SAN,BoTNet����һ���о���������ڽ���ע�����;�������ڵ�������,����AA-ResNet,Container,������ϵ�ṹ��Ϊÿ��ģ����ƶ���·�������ܵ����ơ����,���еķ�����Ȼ����ע�����;�����Ϊ��ͬ�IJ���,����֮���DZ�ڹ�ϵ��δ�õ�������á�
����ƪ������,������ͼ������ע�����;���֮������еĹ�ϵ��ͨ���ֽ�������ģ�������,��������������������ͬ��1��1�������㡣������һ�۲�,���߿�����һ����ΪACmix�Ļ��ģ��,������С�ļ��㿪������ע�����;�������ؽ��������������˵,������1��1����ͶӰ��������ӳ��,����÷ḻ���м�������Ȼ��,���ղ�ͬ�ķ�ʽ,���ֱ�����ע�����;����ķ�ʽ,���ú;ۺ��м�������ͨ�����ַ�ʽ,ACmix��������������ģ��ĺô�,����Ч�ر�������ִ�а����ͶӰ������
���ĵĹ�������������:
(1)��ʾ����ע�����;���֮���ǿ��DZ�ڹ�ϵ,Ϊ��������ģ��֮�����ϵ�ṩ���µ��ӽ�,��Ϊ����µ�ѧϰ��ʽ�ṩ����ʾ��
(2) ����ע��;���ģ����������������������������ŵ㡣����֤�ݱ���,���ģ��ʼ�����ڴ���������ע����ģ�͡�
(һ)��Attention enhanced Convolution
�����ǰ�����ͼ��ע����Ʊ���,�����Կ˷���������ľֲ������ơ����,�����о���Ա̽����ʹ��ע����ģ������ø��������Ϣ����ǿ�������繦�ܵĿ����ԡ��ر���,SE��Gather-Excite (GE) Ϊÿ��ͨ�����¸���һ��Ȩ�ء�BAM��CBAM�ֱ��ͨ���Ϳռ�λ�����¼�Ȩ,�Ը��õ�ϸ������ͼ��AA Resnetͨ������������һ����������ע���������ע����ͼ����ǿijЩ�����㡣BoTNet��ģ�͵ĺ��ڽ�����ע����ģ�������������Щ������Ŀ����ͨ���ۼ�����Χ���ص���Ϣ����Ƹ�����������ȡ����
(��)��Attention enhanced Convolution
����Vision Transformer �ij���,�������Transformer�ı��屻���,���ڼ�����Ӿ�������ȡ���������ĸĽ���������һЩ�о��������þ������㲹��Transformerģ��,���������Ĺ���ƫ�á�CvT�� tokenization�������в��þ���,�����ò���������������ע�����ļ��㸴�Ӷȡ����о������ɵ�ViT���������ڽ����Ӿ���,��ʵ�ָ��ȶ���ѵ����CSwinTransformer���û��ھ�����λ�ñ��뼼��,����ʾ��������ĸĽ���Conformer��Transformer��һ��������CNNģ������,���������������ܡ�
��������ϸ��
(һ)��Convolution
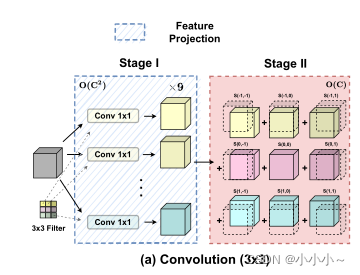
�������ִ�������������IJ���֮һ�����Ȼع˱���������,���Ӳ�ͬ�ĽǶȶ�����������±�������ͼ��ʾ��Ϊ�����,���Ǽ�������IJ���Ϊ1��
һ��������K,
K
��
R
C
o
u
t
��
C
i
n
��
k
��
k
K�� R^{C_{out}��C_{in}��k��k}
K��RCout?��Cin?��k��k,����k���ں˴�С,
C
i
n
,
C
o
u
t
C_{in},C_{out}
Cin?,Cout?����������ͨ����С����������
F
��
R
C
i
n
��
H
��
W
F�� R^{C_{in}��H��W}
F��RCin?��H��W,
G
��
R
C
o
u
t
��
H
��
W
G�� R^{C_{out}��H��W}
G��RCout?��H��W��Ϊ������������ӳ��,����H,W��ʾ�߶ȺͿ���,
f
i
j
��
R
C
i
n
f_{ij} �� R^{C_{in}}
fij?��RCin?,
g
i
j
��
R
C
o
u
t
g_{ij} �� R^{C_{out}}
gij?��RCout?�Ƿֱ��Ӧ��F��G������
(
i
,
j
)
(i,j)
(i,j)���������������������Ա�ʾΪ:

����
K
p
,
q
��
R
C
o
u
t
��
C
i
n
K_{p,q}�� R^{C_{out}��C_{in}}
Kp,q?��RCout?��Cin?,
p
,
q
��
{
0
,
1
,
��
,
k
?
1
}
p,q�� \{0,1,��,k?1\}
p,q��{0,1,��,k?1},��ʾ���λ��
(
p
,
q
)
(p,q)
(p,q)��صĺ�Ȩ�ء�
���Խ���ʽ(1)��дΪ�ں˲�ͬλ�õ�����ӳ����ܺ�:


Ϊ�˽�һ����ʽ,������λ����
f
~
?
S
h
i
f
t
(
f
,
?
x
,
?
y
)
\tilde{f} ? Shift(f, ?x, ?y)
f~??Shift(f,?x,?y):

?
x
��
?
y
?x��?y
?x��?y��Ӧ��ˮƽ�ʹ�ֱλ�ơ�Ȼ��,��ʽ(3)���Ը�дΪ:

�����������ܽ�Ϊ������:

�ڵ�һ��,��������ӳ��������ͶӰ����Ȩ������λ��,��(p,q)���������1��1������ͬ�����ڵڶ���,ͶӰ������ӳ�������ں�λ�ý����ƶ�,�����վۺ���һ�𡣿��Ժ����ع۲쵽,���������ɱ�����1��1������ִ�е�,���������λ�;ۺ����������ġ�
(��)��Self-Attention
ע��������Ӿ�������Ҳ���㷺���á��봫ͳ�ľ������,ע��������ģ���ڸ���Χ�ڹ�ע��Ҫ�������¡�

һ������n��ͷ���ı���ע����ģ�顣
F
��
R
C
i
n
��
H
��
W
F�� R^{C_{in}��H��W}
F��RCin?��H��W,
G
��
R
C
o
u
t
��
H
��
W
G�� R^{C_{out}��H��W}
G��RCout?��H��W��ʾ�����������ԡ�
f
i
j
��
R
C
i
n
,
g
i
j
��
R
C
o
u
t
f_{ij}�� R^{C_{in}},g_{ij}�� R^{C_{out}}
fij?��RCin?,gij?��RCout?��ʾ����
(
i
,
j
)
(i,j)
(i,j)����Ӧ������Ȼ��,ע����ģ����������Ϊ:

�O
�O
| |
�O�O��N��ע��ͷ����Ĵ���,
W
l
(
q
)
��
W
l
(
k
)
��
W
l
(
v
)
W_{l}^{(q)}��W_{l}^{(k)}��W_{l}^{(v)}
Wl(q)?��Wl(k)?��Wl(v)?��queries, keys ,values��ͶӰ����
N
k
(
i
,
j
)
N_k(i,j)
Nk?(i,j)��ʾ���صľֲ�����,��ռ䷶Χk��(i,j)Ϊ����,����
A
(
W
l
(
q
)
f
i
j
��
W
l
(
k
)
f
a
b
)
A(W_{l}^{(q)}f_{ij}��W_{l}^{(k)}f_{ab})
A(Wl(q)?fij?��Wl(k)?fab?)�ǹ���
N
k
(
i
,
j
)
N_k(i,j)
Nk?(i,j)�ڵ���������Ӧע��Ȩ�ء�
�㷺���õ�����ע��ģ��,ע��Ȩ�ؼ�������:

����d��
W
q
(
l
)
f
i
j
W^{(l)}_qf_{ij}
Wq(l)?fij?�������ߴ硣
����,��ͷ����ע����Էֽ�Ϊ������,�����±���Ϊ:

�����ڴ�ͳ��������һ�����Ƚ���1��1����,����������ͶӰΪ��ѯ������ֵ���ڶ��ΰ���ע����Ȩ�صļ���ͼ�ֵ����ľۺ�,���ռ��ֲ����������һ�����,��Ӧ�ļ���ɱ�Ҳ��֤���ǽ�С��,��ѭ�������ͬ��ģʽ��
(��)��Computational Cost
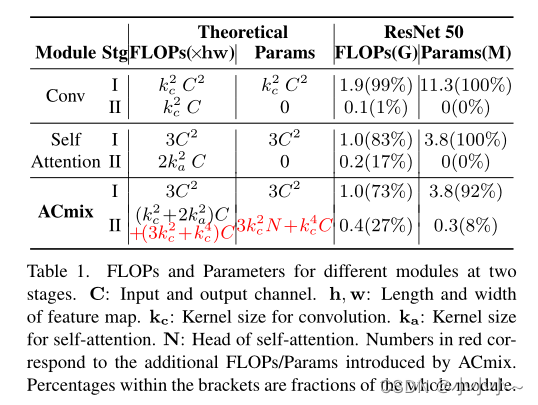
Ϊ�˳���˽��������ע����ģ��ļ���ƿ��,���ķ�����ÿ���εĸ�������(FLOPs)�Ͳ�������,�����±��н������ܽᡣ
1.�о�����,������һ�ε�����FLOPs �Ͳ�������ͨ����СC���ж��θ�����,���ڶ��εļ���ɱ���C�����Թ�ϵ,����Ҫ�����ѵ��������
����ע����ģ����Ҳ��ͬ�������,�������е�ѵ�������������ڽ�I���������۵õ�FLOPs,�������������,��ReNETģ����,����
K
a
=
7
K_a=7
Ka?=7,���ڲ�ͬ�IJ������C=64, 128, 256,512���������,��
3
C
2
>
2
k
a
2
C
3C^2>2k^2_aC
3C2>2ka2?Cʱ,��һ�����ĵIJ�������,��������ͨ����С������,��������ԡ�
(��)��Relating Self-Attention with Convolution
��ע�����;���ģ���������ε����÷dz����ơ���һ��������ѧϰģ��,���ַ���ͨ��ִ��1��1������������ͬ�IJ���,�Ӷ�������ͶӰ������Ŀռ䡣��һ����,�ڶ��ζ�Ӧ�������ۺϵĹ���,�������ǵ�ѧϰ��ʽ��ͬ��
�Ӽ���Ƕ�����,�ھ���ģ�����ע����ģ��ĵ�һ�ν��е�1��1������Ҫ���۵�FLOPs�͵IJ�����ͨ����СC�йصġ����֮��,�ڵڶ���,����ģ�鶼���������Ļ�û�м��㡣
��������,������������:
(1)��������ע������ͨ��1��1����ͶӰ��������ͼʱʵ���Ϲ�����ͬ�IJ���,��Ҳ������ģ��ļ��㿪����
(2) ��Ȼ���ڲ�����������������Ҫ,���ڶ��εľۺϲ�������������,���Ҳ����ö����ѧϰ������
(��)��Integration of Self-Attention and Convolution
�����۲�����Ȼ���γɾ�������ע������������ϡ���������ģ�鹲����ͬ��1��1��������,ֻ��ִ��һ��ͶӰ,������Щ�м�����ӳ��ֱ����ڲ�ͬ�ľۺϲ�������������Ļ��ģ��ACmix��ʾ��ͼ������ʾ��

ACmix���������Ρ��ڵ�һ��,��������ͨ������1��1����ͶӰ,���ֱ�reshapeΪN��Ƭ�Ρ����,�����һ�����3��N����ӳ��ķḻ�м�������
�ڵڶ���,���ǰ��ղ�ͬ�ķ�ʽ��ʹ�á�������ע����·��,���м���������ΪN��,ÿ�������������,ÿ��1��1����һ������Ӧ����������ͼ��Ϊ��ѯ������ֵ,��ѭ��ͳ�Ķ�ͷ����ע��ģ�顣���ں˴�СΪk�ľ���·��,����ȫ���Ӳ㲢����
k
2
k^2
k2����ӳ�䡣���,ͨ���ƶ��;ۺ����ɵ�����,�Ծ����ķ�ʽ������������,����ͳ�������Ӿֲ�����Ұ�ռ���Ϣ��
���,����·����������,ǿ����������ѧϰ�ı�������:

(��)��Improved Shift and Summation
����·���е��м�������ѭ��ͳ����ģ����ִ�е���λ����Ͳ������������������Ϻ���,����ͬ�����ƶ�����ʵ���ϻ��ƻ����ݵľֲ���,����ʵ��ʸ����ʵ�֡�����ܻἫ�����ģ��������ʱ��ʵ��Ч�ʡ�
��Ϊ���ȴ�ʩ,���ù̶��˵���Ⱦ����������Ч��������λ,������ʾ��ȡֵΪ(f,?1.?1) ��λ�����ļ��㹫ʽΪ:

����c�����������Ե�ÿ��ͨ����
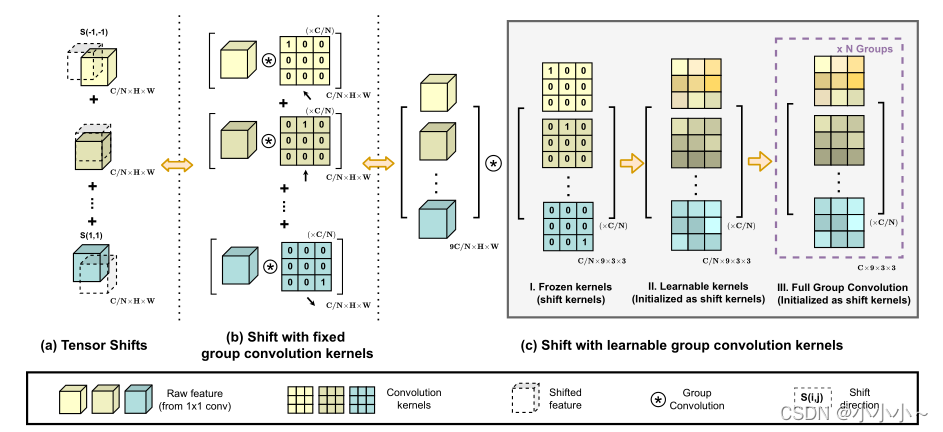
��һ����,������ǽ�������(�˴�Сk=3)��ʾΪ:

��Ӧ��������Ա�ʾΪ:

���,ͨ������ض���λ��������Ƶĺ�Ȩ��,��������൱�ڼ�������λ��Ϊ�˽�һ��������Բ�ͬ���������֮��,���������������;����˷ֱ���������,������λ�����ʾΪ�������,����ͼ��ʾ��������ʹģ����и��ߵļ���Ч�ʡ�
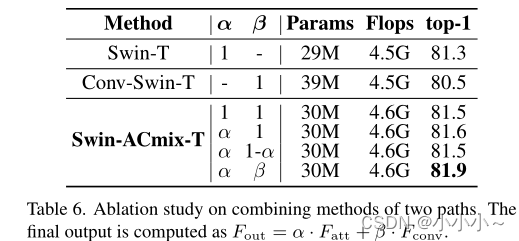
�ڴ˻�����,����������һЩ����,����ǿģ�������ԡ�����ͼ(c.II)��ʾ,����������Ϊ��ѧϰ��Ȩ���ͷ�,������λ����Ϊ��ʼ�����������ģ������,ͬʱ������ԭʼ��������������������ʹ�ö����������ƥ���������ע����·�������ͨ��ά��,����ͼ(c.III)��ʾ��
(��)��Generalization to Other Attention Modes
������ע�������Ƶķ�չ,�����о���������̽��ע�������ӵı仯,�Խ�һ�����ģ�͵����ܡ���Swin Transformer���õĴ���ע������ͬһ���ֲ������б���tokens����ͬ������,�Խ�ʡ����ɱ���ʵ�ֿ���������VIT��DEIT,�����ڵ������ڱ��ֳ�����������ȫ��ע��������Щ�����ض���ģ�ͼܹ��±�֤������Ч�ġ�
�����������,ֵ��ע�����,���������ACmix����������ע��������,���ҿ��Ժ����������������塣�������,ע����Ȩ�ؿ����ܽ�Ϊ:

[
?
]
[��]
[?]��ʾ��������,
?
(
?
)
?(��)
?(?)��ʾ���������м�����Լ����������ͶӰ��,
W
k
(
i
,
j
)
W_k(i,j)
Wk?(i,j)��ʾÿ����ѯ��ǵ�ר�ý�����,W��ʾ��������ͼ��Ȼ��,�������ע����Ȩ�ؿ�Ӧ���ڵ�ʽ(12),������һ�㹫ʽ��
����ʵ����֤