1. ����
�������ѧϰ��NLP����ķ�չ,�����ܶ��������ģ�������������NLP����,�����ڶ������ģ����,���ɶ���ʹ�õ��������ĸ���,��Ͳ��ò��ἰword2vec[1]���������ɹ��ߡ���word2vec���������ߵ������,Ԥѵ���Ĵ����������ڶ�NLP���ģ���е���Ҫ��ɲ��֡�Ȼ����ͳ��word2vec���ɵĴ����������������ص�,�����ɵĴ�����ʽ�̶�,�������������ĵĸı���ı�,���̶ֹ��Ĵ����������һ�ʶ�������⡣���硰bank�������,�ȿ��Ա�ʾ���Ӱ���,Ҳ���Ա�ʾ�����С���Embeddings from Language Models(ELMo)[2]��2018�������һ�ֻ��������ĵ�Ԥѵ��ģ��,�о���Ա��Ϊһ���õ�Ԥѵ������ģ��Ӧ���ܹ������ḻ�ľ䷨��������Ϣ, �����ܹ��Զ���ʽ��н�ģ��
ELMo�ı���˼��ͨ����������ѧϰ��ÿ���ʵ�һ����embedding��ʽ,��ʱ�����������ص�;���ھ����NLP������ʱ,��ʱÿ���ʶ������������ĵĺ���,ͨ�������ĵ���ѧϰ�õĴ�������
2. �㷨ԭ��
2.1. ELMo�Ļ���ԭ��
��ELMo�ı���˼���а��������εĹ���,��һ�������ô���Ԥ��ѵ�������������صĴ������ı���,�������ġ�bank��,��ʱ������֪���������ǡ����С����ǡ��Ӱ���;�ڶ������ھ��������������,��ÿ�����������뵽����������ĵ����Ի�����,��ÿ����������,����Ӧ���������,����ݾ�����������ᄈ,���õ���bank��һ�ʵ�����������ص�������
2.2. ��һ�Ρ���ELMoԤѵ��
2.2.1. ELMoģ�͵Ľṹ
����ELMoģ�͵�����ṹ����ͼ��ʾ:
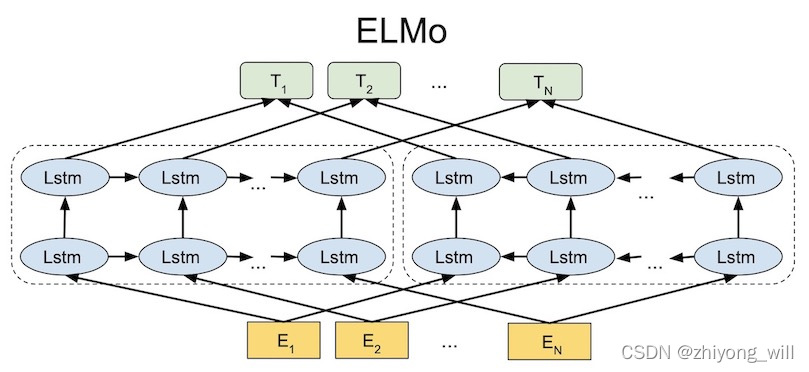
��ELMo�Ľṹͼ�п��Կ���,ELMo��Ҫ��Ϊ��������,��һ,���·��Ļ�ɫ����,�ʵ�Embedding����,���ڽ���ɢ�Ĵ�ӳ��ɳ��ܵ���������;�ڶ�,�м����ɫ����,�ⲿ��������˫���LSTMģ��,���ڶԴʽ�������ѧϰ;����,���Ϸ�����ɫ����,�����������ձ�����������[2]�п�֪,���������ֵ���������������㼶�ĺ���,�ֱ���:
- ��һ���ִ����˴ʷ�����
- �ڶ����ִ����˾䷨����
- �������ִ�������������
����,��ELMo������ṹ��,��������ģ��ѧϰ����˫���˫��LSTM��
2.2.2. ELMoģ�͵�ѵ��
ELMoģ�͵�Ԥѵ�����ڴ���Ԥ����,ͨ���ල�ķ�ʽ,��Ŀ�꺯����������ģ��[3]����������� N N N���ʵ�����Ϊ ( t 1 , t 2 , ? ? , t N ) \left ( t_1,t_2,\cdots ,t_N \right ) (t1?,t2?,?,tN?),�ȿ����������ģ��,��Ŀ��ͨ��������ǰ k ? 1 k-1 k?1���ʵ����� ( t 1 , t 2 , ? ? , t k ? 1 ) \left ( t_1,t_2,\cdots ,t_{k-1} \right ) (t1?,t2?,?,tk?1?)Ԥ��� k k k���� t k t_k tk?�ĸ���:
p ( t 1 , t 2 , ? ? , t N ) = �� k = 1 N p ( t k �O t 1 , t 2 , ? ? , t k ? 1 ) p\left ( t_1,t_2,\cdots ,t_N \right )=\prod_{k=1}^{N}p\left ( t_k\mid t_1,t_2,\cdots ,t_{k-1} \right ) p(t1?,t2?,?,tN?)=k=1��N?p(tk?�Ot1?,t2?,?,tk?1?)
�ٿ����������ģ��,��Ŀ����ͨ���� k k k���� t k t_k tk?����Ĵʵ����� ( t k �O t k + 1 , t k + 2 , ? ? , t N ) \left ( t_k\mid t_{k+1},t_{k+2},\cdots ,t_{N} \right ) (tk?�Otk+1?,tk+2?,?,tN?)��Ԥ�� t k t_k tk?�ĸ���:
p ( t 1 , t 2 , ? ? , t N ) = �� k = 1 N p ( t k �O t k + 1 , t k + 2 , ? ? , t N ) p\left ( t_1,t_2,\cdots ,t_N \right )=\prod_{k=1}^{N}p\left ( t_k\mid t_{k+1},t_{k+2},\cdots ,t_{N} \right ) p(t1?,t2?,?,tN?)=k=1��N?p(tk?�Otk+1?,tk+2?,?,tN?)
����˫���LSTMģ��,ͨ������ģ�͵õ�˫��LSTM��Ŀ�꺯��Ϊ:
�� k = 1 N ( l o g ?? p ( t k �O t 1 , ? ? , t k ? 1 ; �� x , �� �� L S T M , �� s ) + l o g ?? p ( t k �O t k + 1 , ? ? , t N ; �� x , �� �� L S T M , �� s ) ) \sum_{k=1}^{N}\left ( log\; p\left ( t_k\mid t_1,\cdots ,t_k-1;\Theta _x,\overrightarrow{\Theta }_{LSTM},\Theta _s \right )+log\; p\left ( t_k\mid t_{k+1},\cdots ,t_N;\Theta _x,\overleftarrow{\Theta }_{LSTM},\Theta _s \right ) \right ) k=1��N?(logp(tk?�Ot1?,?,tk??1;��x?,��LSTM?,��s?)+logp(tk?�Otk+1?,?,tN?;��x?,��LSTM?,��s?))
��ʱ��Ҫ�������Ŀ�꺯�������ֵ,���� �� x \Theta _x ��x?��ʾ���Ǵʵ�������������, �� �� L S T M \overrightarrow{\Theta }_{LSTM} ��LSTM?�� �� �� L S T M \overleftarrow{\Theta }_{LSTM} ��LSTM?�ֱ�Ϊ����ͷ����LSTMģ�͵IJ���, �� s \Theta _s ��s?Ϊsoftmax��IJ�����
ͨ������ģ�͵�ѵ��,���յõ��˶������,���Ա�ʾΪ:
R k = { x k L M , h �� k , j L M , h �� k , j L M �O j = 1 , ? ? , L } = { h k , j L M �O j = 1 , ? ? , L } R_k=\left \{ \mathbf{x}_k^{LM},\overrightarrow{\mathbf{h}}_{k,j}^{LM},\overleftarrow{\mathbf{h}}_{k,j}^{LM}\mid j=1,\cdots ,L \right \}=\left \{ \mathbf{h}_{k,j}^{LM}\mid j=1,\cdots ,L \right \} Rk?={xkLM?,hk,jLM?,hk,jLM?�Oj=1,?,L}={hk,jLM?�Oj=1,?,L}
����, h k , 0 L M \mathbf{h}_{k,0}^{LM} hk,0LM?��ʾ������ͼ�еĻ�ɫ����,��ʾ�������������صĴʵ�����, h k , j L M = [ h �� k , j L M ; h �� k , j L M ] \mathbf{h}_{k,j}^{LM}=\left [ \overrightarrow{\mathbf{h}}_{k,j}^{LM};\overleftarrow{\mathbf{h}}_{k,j}^{LM} \right ] hk,jLM?=[hk,jLM?;hk,jLM?]��ʾ����ÿһ���LSTM�������ͨ�������������ϲ���һ��������õ����յ�������ʾ:
E L M o k = E ( R k ; �� e ) \mathbf{ELMo}_k=E\left ( R_k;\mathbf{\Theta }_e \right ) ELMok?=E(Rk?;��e?)
2.3. �ڶ��Ρ�������������
ͨ��ELMo��Ԥѵ���õ�������һϵ�е����� E L M o k \mathbf{ELMo}_k ELMok?,�������εIJ�ͬ����,ѡ��ͬ������,��Ŀ���ǽ����ɵ��������뵽��������,���������������ڲ�ͬ������,��Ҫѡ���������ͬ,���ڲο�����[2]���ἰֻʹ���������,�� E ( R k ) = h k , j L M E\left ( R_k \right )=\mathbf{h}_{k,j}^{LM} E(Rk?)=hk,jLM?����Ϊһ���,��������ʽ��ʾ:
E L M o k t a s k = E ( R k ; �� t a s k ) = �� t a s k �� j = 0 L s j t a s k h k , j L M \mathbf{ELMo}_k^{task}=E\left ( R_k;\Theta ^{task} \right )=\gamma ^{task}\sum_{j=0}^{L}s_j^{task}\mathbf{h}_{k,j}^{LM} ELMoktask?=E(Rk?;��task)=��taskj=0��L?sjtask?hk,jLM?
����,���� s t a s k \mathbf{s}^{task} stask���ڶ�������һ��, �� t a s k \gamma ^{task} ��task���ڶԾ��������е��������š�
3. �ܽ�
ELMoͨ����������ѵ�������������ص�һϵ��������ʾ,��ͬ�㼶���������в�ͬ������,�����˴ʷ���Ϣ,�䷨��Ϣ�Լ�������Ϣ,ͨ����ͬ�����,���ھ���������Ļ��������õ����������ĵĴ�������ʾ,���ܹ�Ӧ�õ���������������С�
�����
[1] Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
[2] Peters M , Neumann M , Iyyer M , et al. Deep Contextualized Word Representations[J]. 2018.
[3] Y Bengio?, Ducharme R , Vincent P . A Neural Probabilistic Language Model. 2001.