����Ŀ¼
ǰ��
?���ĵ�ַ
?��ƪ���������е����,�������Ľ����Դ����������,��Ȼ,����ƪ��ԭ��,���˲�������������㵽�����������������Transformer�C>detr�C>deforable detr�Ĺ���,ǽ���Ƽ������ȿ�����ƪ���˲���,��ΪDeformable detr�ܶ�̳���Detr,��Detr�̳���Transfomer��
?mmdet֮detrԴ����
?nn.Transformerʵ�ּĻ�����������
һ�����Ľ��
1.1. �����
?��ҪΪ�˿˷�1)ѵ��ʱ�䳤(����������ԭ���кü�ƪ�����о�,����DAB-Detr��DN-Detr);2)detr���ڼ��㸴�Ӷȵ�ԭ�����һ������ͼ,û��FPN��СĿ���ⲻ�Ѻá�
?���ľ�����ν��ͼ��㸴�Ӷ�,��ΪMultiHeadAttn����hw����ά�ȵ���������������ܼ�����,���Ա���������α����˼��,��ÿ������������Ҫ�������������ص���м���,����ͨ������ѧϰ��K��������������ע��������,�Ӷ������˸��Ӷȡ�
1.2. ���α�ע����ģ��
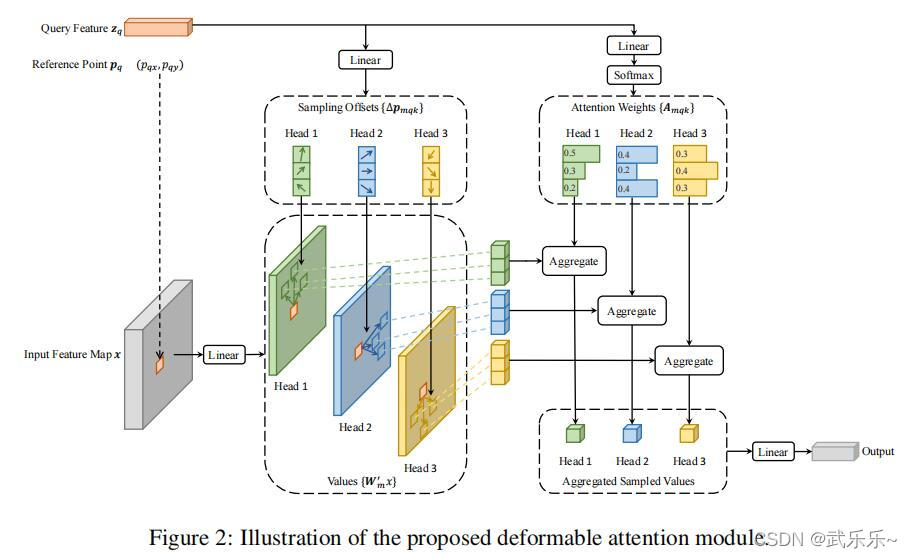
?����������:�ڵõ�����ͼx�ϵIJο���pλ�õ���������zq֮��,���Ⱦ������Բ�任Ԥ��õ�����ƫ����offset,Ȼ������ƫ�������ӵ�λ��p�����õ��������λ��,֮����ֵ��ȡ����Ӧλ�õ�����������Ϊv;ͬʱzq�������Ա任+softmax�õ����ƶȾ���,����v���˷��õ�����output��
1.3. ��չ���������ͼ
?Ϊ����Detr������������ͼ,���߽�����ģ����չ���������ͼ���ٸ�������:��������������ͼf1-f3���������ڼ�������ͼf1�ϲο���p1��ע����,��ô���Ƚ�p1λ�þ�����һ����õ�p1��f2,f3�ϵIJο���λ��p2,p3��ͬʱ��ȡ��p1λ�õ���������zq,Ȼ��zq�ֱ�Ԥ���p1,p2,p3λ�õĶ�ͷƫ����,��ͨ����ֵ�õ���������λ�ú����������v1,v2,v3�����softmax����zq��v��˱��ܵõ��ںϺ����������q��
���� mmdetԴ�뽲��
2.1. ͼ��������ȡ
?�ò���û���õ�FPN,�����õ��˶������ͼ,������������ͼ��ͨ����ͳһ���256���ⲿ�ִ���Ƚϼ�,������ֻ���������ļ�����������ɲο�:mmdet���н��ResNet��
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(1, 2, 3), # �õ�����������ͼ
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='ChannelMapper',
in_channels=[512, 1024, 2048],
kernel_size=1,
out_channels=256, # ����������ͼ��ͨ����Ŀͳһ���256
act_cfg=None,
norm_cfg=dict(type='GN', num_groups=32),
num_outs=4)
2.2. ����mask��λ�ñ���
?�ڵõ����ߴ粻һ����ͼ��,���ȸ�ÿ������ͼ����һ��mask����(������pad����ͼ���ע����),��Ϊ��������ͼ������λ�ñ��롣����λ�ñ��벿�����:mmdet֮detrԴ������
# mlvl_feats�Ǹ�Ԫ��,����Ԫ��������ͼ��ÿ��Ԫ��shape = [b,c,h,w]
batch_size = mlvl_feats[0].size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']
# ����һ��ȫ1�ijߴ�Ϊpad��ͼ���mask����
img_masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
# ����ÿ��ͼ��,��ԭʼͼ������Ϊ0,1��λ�ñ�ʾpad����
for img_id in range(batch_size):
img_h, img_w, _ = img_metas[img_id]['img_shape']
img_masks[img_id, :img_h, :img_w] = 0
# ����ÿ������ͼ�ijߴ�,����ÿ��img_masks���в���
mlvl_masks = []
mlvl_positional_encodings = []
for feat in mlvl_feats:
mlvl_masks.append(
# ���ォimg_masks������һ��ά��:[b,h,w]-->[1,b,h,w],��ʱ��b��Ϊͨ��,����Ҫ��
# ÿ��ͨ���Ͻ����ϲ���,��������Ч�����Ƿֱ�Ϊÿ��mask�����˶�Ӧ�IJ�����
F.interpolate(img_masks[None],size=feat.shape[-2:]).to(torch.bool).squeeze(0))
# Ϊÿ������ͼ�����˶�Ӧ��λ�ñ���,ÿ��λ�ö�Ӧһ��256ά��λ�ñ�����Ϣ:[b,256,h,w]
mlvl_positional_encodings.append(self.positional_encoding(mlvl_masks[-1]))
2.3. ����Transformer
?�ڵõ�����ͼ,λ�ñ���֮��,�������Transformer�����и��������������Ѿ�ע�ͺ��ˡ���������Deformable detr�ĺ��ġ�
# ��ʼ��query:[300,512]
self.query_embedding = nn.Embedding(self.num_query,self.embed_dims * 2)
hs, init_reference, inter_references, \
enc_outputs_class, enc_outputs_coord = self.transformer(
mlvl_feats, # tuple([b,c,h1,w1],[b,c,h2,w2],[b,c,h3,w3])
mlvl_masks, # list([b,h1,w1],[b,h2,w2],[b,h3,w3])
query_embeds, # ��nn.Embedding���ɵ�shape:[300,512]
mlvl_positional_encodings, # list([b,256,h1,w1],[b,256,h2,w2],[b,256,h3,w3])
reg_branches=self.reg_branches if self.with_box_refine else None, # None
cls_branches=self.cls_branches if self.as_two_stage else None # None
)
2.3.1. Transformer��ʼ������
? ����,transformer�ڳ�ʼ�������д�������������:�����:[4��������,256]; �ο�������Բ�:nn.Liear(256,2),�ο��㺬������õ��ڽ���˵���� ע��˴���levle_embedʹ��nn.Parameter()�����˷�װ,�ʲ㼶������Ҫ�ݶȸ��¡�
def init_layers(self):
"""Initialize layers of the DeformableDetrTransformer."""
self.level_embeds = nn.Parameter(
torch.Tensor(self.num_feature_levels, self.embed_dims)) # level_embedding:[4,256]
else:
self.reference_points = nn.Linear(self.embed_dims, 2) # [256,2]
?Ȼ��forward����,Ҳ���ǽ����������Ͻ��е�forward������
2.3.2. Transformer��forward����
? ��forward�����ڲ�,���Ƚ��������ͼmlvl_feats���������ͼ��Ч����mlvl_masks���������ͼ��λ��Ƕ��mlvl_positional_encodings����list��������ƽ��ƴ�Ӳ�����
feat_flatten = torch.cat(feat_flatten, 1) # [b,sum(hw),256]
mask_flatten = torch.cat(mask_flatten, 1) # [b,sum(hw)]
# [b,sum(hw),256]��ʱ�Ѿ����ӹ��㼶����,��û�����д���
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
# ÿ������ͼ�ijߴ�[[h1,w1],[h2,w2],[h3,w3],[h4,w4]]
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=feat_flatten.device)
# �ҳ�ÿ������ͼ��ʼ�ĵ�λ��[0,9680,12120,12740]
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
# �õ�ÿ������ͼ����Ч���߱���: [b,4,2]--> ÿ������ͼ����Ч����
valid_ratios = torch.stack(
[self.get_valid_ratio(m) for m in mlvl_masks], 1)
'''
valid_ratios =
tensor([[[1.0000, 1.0000],
[1.0000, 1.0000],
[1.0000, 1.0000],
[1.0000, 1.0000]],
[[0.7638, 1.0000],
[0.7656, 1.0000],
[0.7812, 1.0000],
[0.8125, 1.0000]]], device='cuda:0')
'''
? ����Ϊֹ��û�н���,����Ҫ��ȡ��������ͼ�ϲο����λ��,������ͼ��ÿ�����ص��λ�á� ��ȡ����ͼ���������ص��λ��ͨ�����º���:
def get_reference_points(spatial_shapes, valid_ratios, device):
"""Get the reference points used in decoder.
Args:
spatial_shapes (Tensor): The shape of all
feature maps, has shape (num_level, 2).
valid_ratios (Tensor): The radios of valid
points on the feature map, has shape
(bs, num_levels, 2)
device (obj:`device`): The device where
reference_points should be.
Returns:
Tensor: reference points used in decoder, has \
shape (bs, num_keys, num_levels, 2).
"""
reference_points_list = []
for lvl, (H, W) in enumerate(spatial_shapes):
# ��ȡÿ���ο������ĺ�������
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, H - 0.5, H, dtype=torch.float32, device=device),
torch.linspace(
0.5, W - 0.5, W, dtype=torch.float32, device=device))
# ������������й�һ��
ref_y = ref_y.reshape(-1)[None] / (
valid_ratios[:, None, lvl, 1] * H)
ref_x = ref_x.reshape(-1)[None] / (
valid_ratios[:, None, lvl, 0] * W)
# ref: [1,12,2]
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
reference_points = torch.cat(reference_points_list, 1) # [1,60,2]
# ���ο����λ��ӳ�䵽��Ч����
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
return reference_points
2.3.3. Transformer��encoder����
? ����������������������,��������������Transformer,���Ⱦ���encoder����:
# ����encoder
memory = self.encoder(
query=feat_flatten, # [sum(hw), b, 256]
key=None,
value=None,
query_pos=lvl_pos_embed_flatten, # [sum(hw), b ,256]
query_key_padding_mask=mask_flatten, # [b, sum(hw)]
spatial_shapes=spatial_shapes,
reference_points=reference_points, # [b,sum(hw),4,2]
level_start_index=level_start_index, # [4]
valid_ratios=valid_ratios, # [b,4,2]
**kwargs)
?�����encoderlayer���ڲ���������:�ڲ����ʵ��õ��ǿ��α�ע�����IJ���,�����α�ע������������ĺ���,�����ַ:mmcv/ops/multi_scale_deform_attn.py,���ȿ��¿��α�ע����ģ��ij�ʼ������:
self.embed_dims = embed_dims
self.num_levels = num_levels
self.num_heads = num_heads
self.num_points = num_points # �����е�K,������ĸ���
# num_heads * num_level * num_points * 2
self.sampling_offsets = nn.Linear(
embed_dims, num_heads * num_levels * num_points * 2)
self.attention_weights = nn.Linear(embed_dims,
num_heads * num_levels * num_points)
self.value_proj = nn.Linear(embed_dims, embed_dims)
self.output_proj = nn.Linear(embed_dims, embed_dims)
?������Ҫ��������⼸��nn.Linear����,�ں���forward���ֻ��õ���
?�ڿ��¿��α�ע������forward����:
value = self.value_proj(value) # ��value����һ������ӳ��
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
# value����ά�ȱ任: [b, sum(hw), 8, 256/8]
value = value.view(bs, num_value, self.num_heads, -1)
# ����һ�����Բ�ӳ��õ�ÿ��query��ƫ����:[b,sum(hw),8,4,2,2]
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
# ����һ�����Բ�ӳ��+softmax�õ�ÿ��query��ע����Ȩ��
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1)
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points)
# ��Ԥ��õ���ƫ���������ο��� �����й�һ��
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :]
# ����cuda�����cuda����
if torch.cuda.is_available() and value.is_cuda:
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
# û�������cpu�汾
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
output = self.output_proj(output) # ������������Ա任
?�����ڿ���cpu�汾�Ŀ��α�ע����,��������Ҫ��ά�ȱ任�Ƚ��ơ���ҿ�������������(������):
def multi_scale_deformable_attn_pytorch(value, value_spatial_shapes,
sampling_locations, attention_weights):
"""CPU version of multi-scale deformable attention.
Args:
value (torch.Tensor): The value has shape
(bs, num_keys, mum_heads, embed_dims//num_heads)
value_spatial_shapes (torch.Tensor): Spatial shape of
each feature map, has shape (num_levels, 2),
last dimension 2 represent (h, w)
sampling_locations (torch.Tensor): The location of sampling points,
has shape
(bs ,num_queries, num_heads, num_levels, num_points, 2),
the last dimension 2 represent (x, y).
attention_weights (torch.Tensor): The weight of sampling points used
when calculate the attention, has shape
(bs ,num_queries, num_heads, num_levels, num_points),
Returns:
torch.Tensor: has shape (bs, num_queries, embed_dims)
"""
bs, _, num_heads, embed_dims = value.shape
_, num_queries, num_heads, num_levels, num_points, _ =\
sampling_locations.shape
# �ڵ�һ��ά���Ͻ��в�ֳ�list:����ÿ��Ԫ��shape:[b,hw, num_heads, embed_dims//num_heads]
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes],
dim=1)
# �����õ���F.grid_sample������Ҫ������Ϊ[-1,1],����Ҫ��һ��ӳ��
sampling_grids = 2 * sampling_locations - 1
# �����洢�����������
sampling_value_list = []
for level, (H_, W_) in enumerate(value_spatial_shapes):
# bs, H_*W_, num_heads, embed_dims ->
# bs, H_*W_, num_heads*embed_dims ->
# bs, num_heads*embed_dims, H_*W_ ->
# bs*num_heads, embed_dims, H_, W_
value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(
bs * num_heads, embed_dims, H_, W_)
# bs, num_queries, num_heads, num_points, 2 ->
# bs, num_heads, num_queries, num_points, 2 ->
# bs*num_heads, num_queries, num_points, 2
sampling_grid_l_ = sampling_grids[:, :, :,
level].transpose(1, 2).flatten(0, 1)
# �ú���value��grid����4D,�Ҷ��ߵ�һ��ά�ȱ������,
# ���ղ����������ͼ��һ��ά��һ��,�ڶ���ά�ȸ�valueһ��,
# �����ĸ�ά�ȸ��������ά��һ��
# sampling_value_l_ = [bs*num_heads, embed_dims, num_queries, num_points]
sampling_value_l_ = F.grid_sample(
value_l_, # [bs*num_heads, embed_dims, H_, W_]
sampling_grid_l_, # [bs*num_heads, num_queries, num_points, 2]
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (bs, num_queries, num_heads, num_levels, num_points) ->
# (bs, num_heads, num_queries, num_levels, num_points) ->
# (bs, num_heads, 1, num_queries, num_levels*num_points)
attention_weights = attention_weights.transpose(1, 2).reshape(
bs * num_heads, 1, num_queries, num_levels * num_points)
#��list���ĸ�Ԫ�ؽ����˶ѵ�,����ӦԪ����˲������һ��ά���Ͻ������
# [bs*num_heads, embed_dims, num_queries, num_levels*num_points] *
# (bs*num_heads, 1, num_queries, num_levels*num_points)
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) *
attention_weights).sum(-1).view(bs, num_heads * embed_dims,
num_queries)
return output.transpose(1, 2).contiguous()
?���������output��shapeΪ:[batch, num_queries, embed_dims]��
2.3.4. Transformer��decoder����
?�ڵõ�memory��,������decoder���֡����ȿ���������:
# encoder�����memory
memory = memory.permute(1, 0, 2) # [b, num_querie,256]
bs, _, c = memory.shape
# һ�β���
else:
# ��ѧϰ��nn.Embedding:[300,512],��decoder�еĿ�ѧϰλ�ñ���
query_pos, query = torch.split(query_embed, c, dim=1)# [300,256]
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1)#[b,300,256]
query = query.unsqueeze(0).expand(bs, -1, -1) # [b,300,256]
# ��query_pos����һ�����Ա任+sigmoid��������Ϊ��ʼ�ο�������
reference_points = self.reference_points(query_pos).sigmoid()
init_reference_out = reference_points
# decoder
query = query.permute(1, 0, 2)
memory = memory.permute(1, 0, 2)
query_pos = query_pos.permute(1, 0, 2)
# inter_states: [6,300,bs,256],6��ʾ������6��layer
# inter_references:[6,bs,300,2]
inter_states, inter_references = self.decoder(
query=query,
key=None,
value=memory,
query_pos=query_pos,
key_padding_mask=mask_flatten,
reference_points=reference_points,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
reg_branches=reg_branches,
**kwargs)
inter_references_out = inter_references
return inter_states, init_reference_out, \
inter_references_out, None, None
?�����������decoder����,��encoderһ��,ֻ�Ƕ����ÿ��layer���м�״̬:
output = query
intermediate = [] # �洢ÿ��decoder layer��query
intermediate_reference_points = [] # �����洢ÿ��decoder layer�IJο���
for lid, layer in enumerate(self.layers):
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * \
valid_ratios[:, None]
output = layer( # �˴���encoder������,������
output, # Ψһ����������key��memory
*args,
reference_points=reference_points_input,
**kwargs)
output = output.permute(1, 0, 2)
if self.return_intermediate:
intermediate.append(output)
intermediate_reference_points.append(reference_points)
if self.return_intermediate:
return torch.stack(intermediate), torch.stack(
intermediate_reference_points)
return output, reference_points
?���decoder�����������:inter_states, init_reference_out, ��
inter_references_out:�ֱ��ʾÿ��layer��query,��ʼԤ��IJο���,�Լ�ÿ��layer��Ԥ������м�ο��㡣��������ά�������ⵥ���ڼ���:
'''
inter_states: [num_dec_layers, bs, num_query, embed_dims]
init_reference_out: (bs, num_queries, 4)
inter_references_out: (num_dec_layers, bs,num_query, embed_dims)
'''
2.4. Ԥ��bbox��
?�����������һ��,���Ԥ��bbox�Ĺ��̾ͱȽϼ�,����ʼ����Ϊ�ο���,��ÿ��layer���м�״̬��������ʼ��6�μ��ɡ�
'''
hs: [num_dec_layers, bs, num_query, embed_dims]
init_reference_out: (bs, num_queries, 4)
inter_references_out: (num_dec_layers, bs,num_query, embed_dims)
'''
hs = hs.permute(0, 2, 1, 3)
outputs_classes = []
outputs_coords = []
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference # ��Ϊ��ʼ��
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference) # ����sigmoid
outputs_class = self.cls_branches[lvl](hs[lvl])
tmp = self.reg_branches[lvl](hs[lvl])
if reference.shape[-1] == 4:
tmp += reference
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference # �������ο�������λ�ü���
outputs_coord = tmp.sigmoid()
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
outputs_classes = torch.stack(outputs_classes)
outputs_coords = torch.stack(outputs_coords)
if self.as_two_stage:
return outputs_classes, outputs_coords, \
enc_outputs_class, \
enc_outputs_coord.sigmoid()
else:
return outputs_classes, outputs_coords, \
None, None
�ܽ�
?������Ļ����Žṹͼ����������:
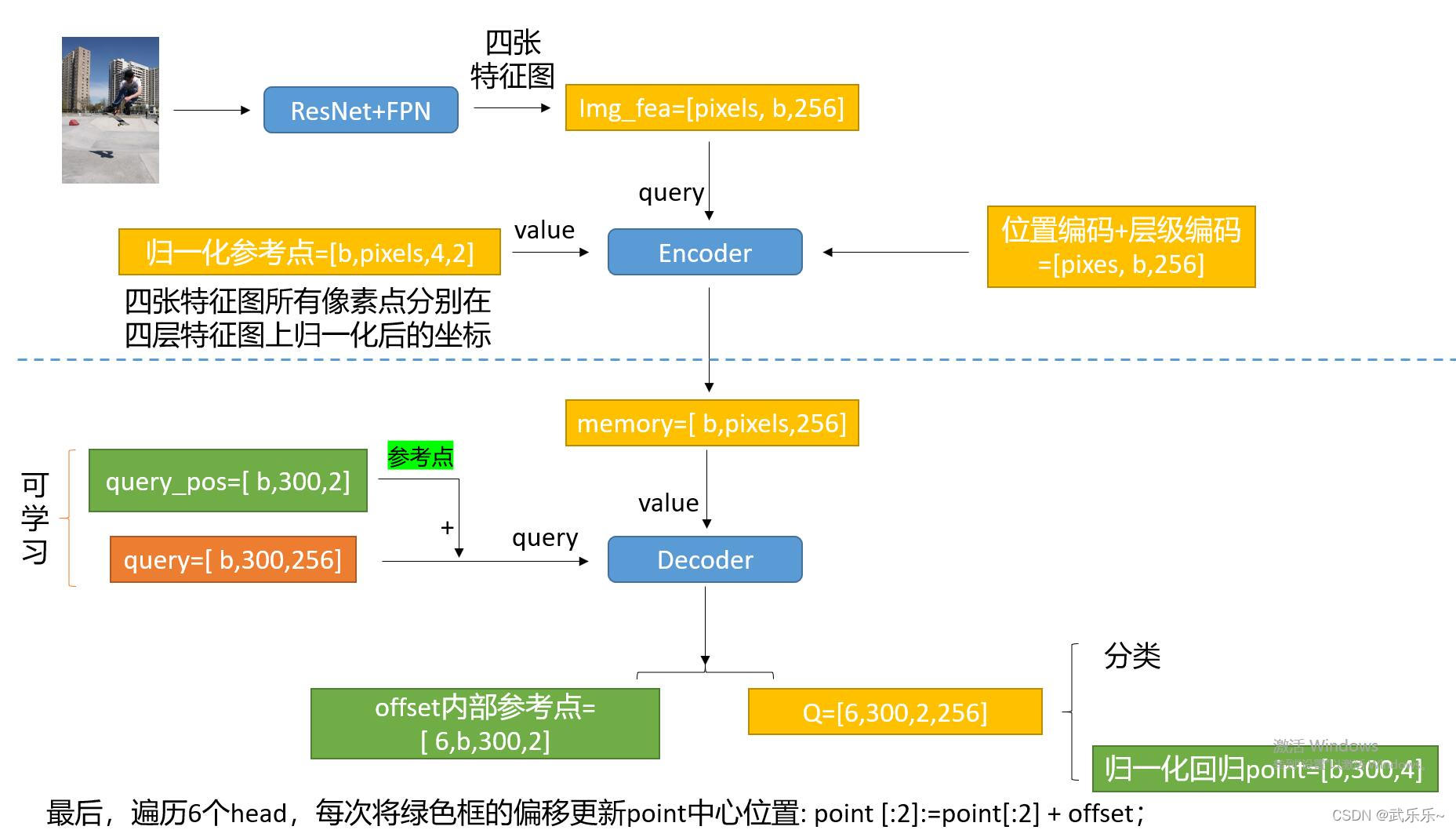
?��ƪ���»��кö�ϸ��û������,�����ӭ��ʱ���۽�����