前言
论文地址:arxiv
代码地址:github
代码为第三方复现的,仅供参考,可能会有diff建议阅读原文…
动机
做ctr预测的时候,观察数据集可以很明显的发现每个用户都会有短时兴趣和长时兴趣,我认为长时兴趣可以表征一个用户丰富的个性化特征,短时兴趣可以更加准确的反应用户当前关注的领域。也确实有论文依据这个想法设计的模型,见:Arxiv-SIM。本文作者主要关注在如何使用短时的兴趣来更好的预测用户的点击。
网络结构
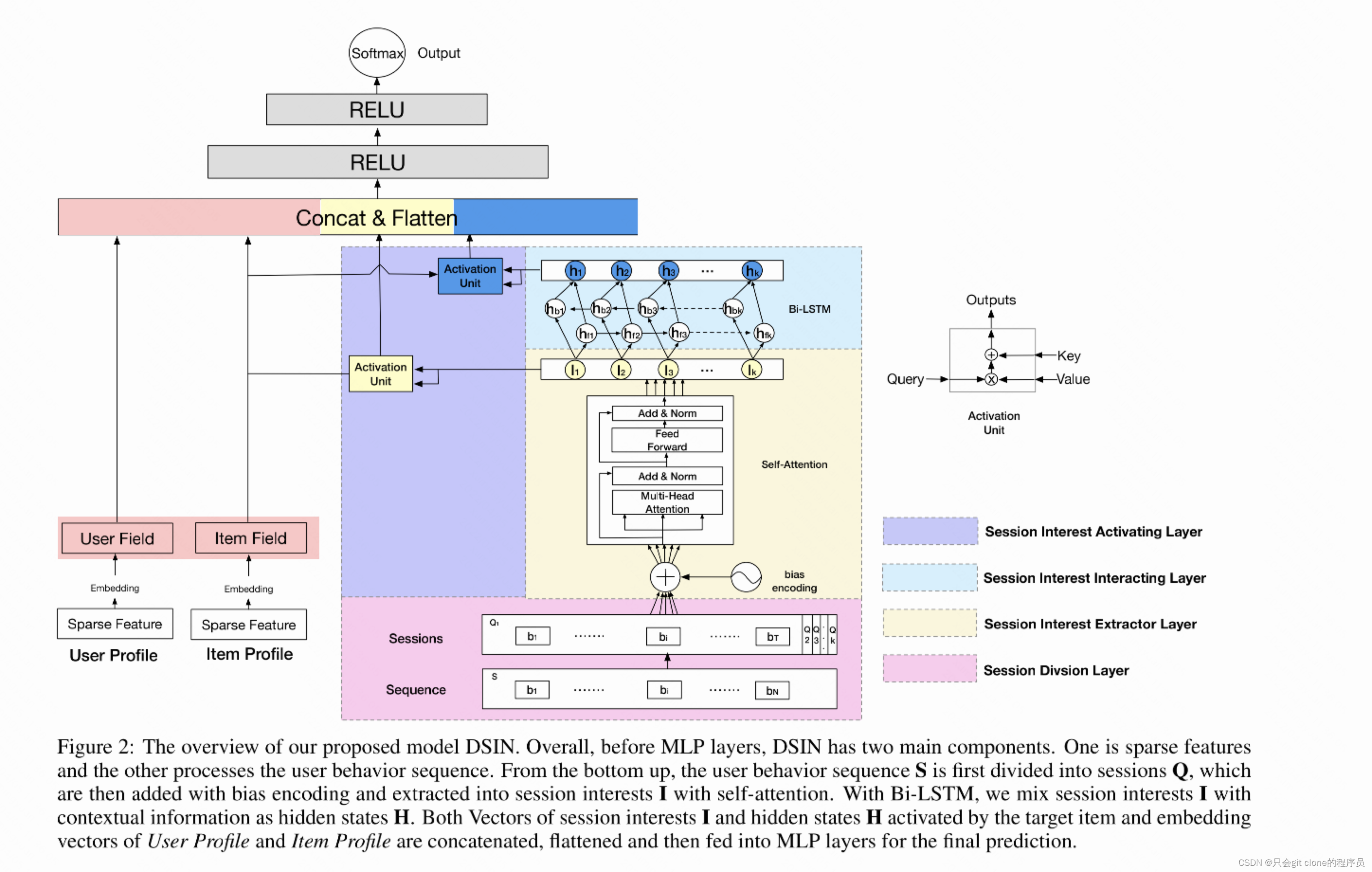
完整的结果如上图所示,可以说基本上参考DIN和DIEN,不了解这两篇论文的可以跳转:DIEN、DIN。多了什么结构呢,接下来一一拆解。

上图的话输入的Sequence特征,转成了Sessions特征,这就是之前说的短时间兴趣的建模,实现其实很简单,作者就是利用Sequence特征的时间将N个Sequence分了T个类,根据作者论文的描述,分类的时间间隔是每半个小时划分为一类。
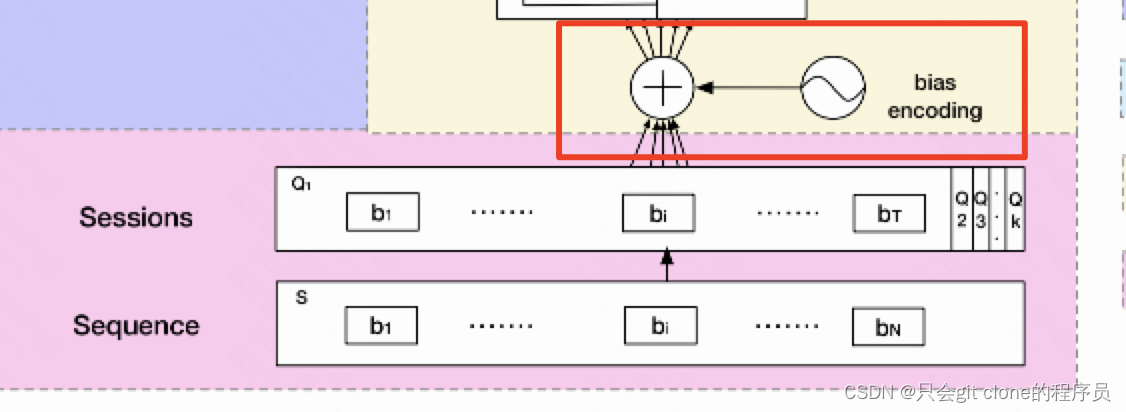
分类之后,作者给Q里面的特征加上位置编码,这个位置编码我感觉论文的公式有问题吧。。。先看原文:

作者写的BE等于三个w相加。然后这三个w的纬度分别是K,T,C,这怎么加???属实不是很理解作者的意思…参考ViT的话我估计这个BE是一个可学习的参数,一般用torch.Parameter实现,形状是(K,T,d),然后直接和输入相加即可。也就是Q = Q + BE。
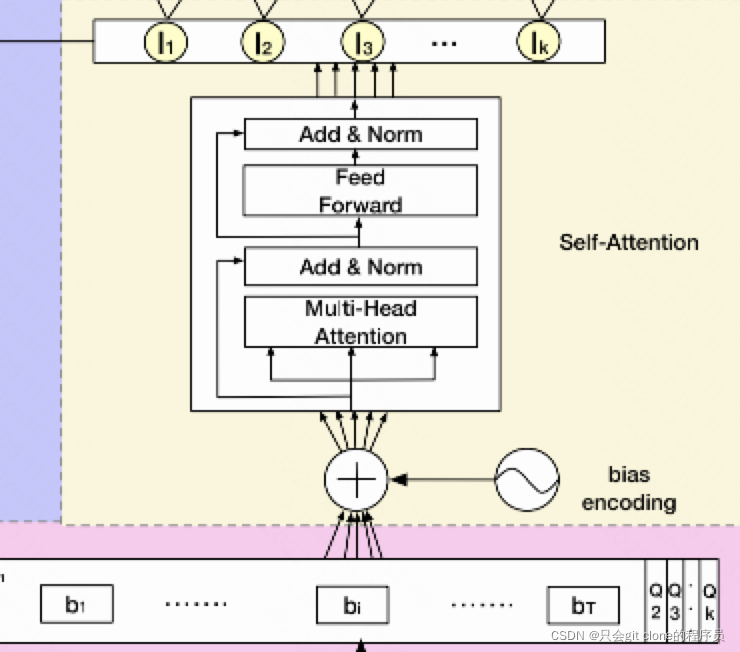
加上之后呢,送入Self Attention模块,这个是attention的经典结构了,不了解的可以参考我之前记录的transformer的论文看看:vision transformer这样就可以得到b1对应的I1,和b2对应的I2了…
然后注意一下,Ik里面因为时间划分会有不定长个特征,因为半个小时时间划分,0点到0:30可能有5个特征,0:30到1:00可能有8个特征,所以需要做一个avg pooling就可以得到最终的Ik了。这个Ik就表示了用户在时间区间k里面的兴趣。
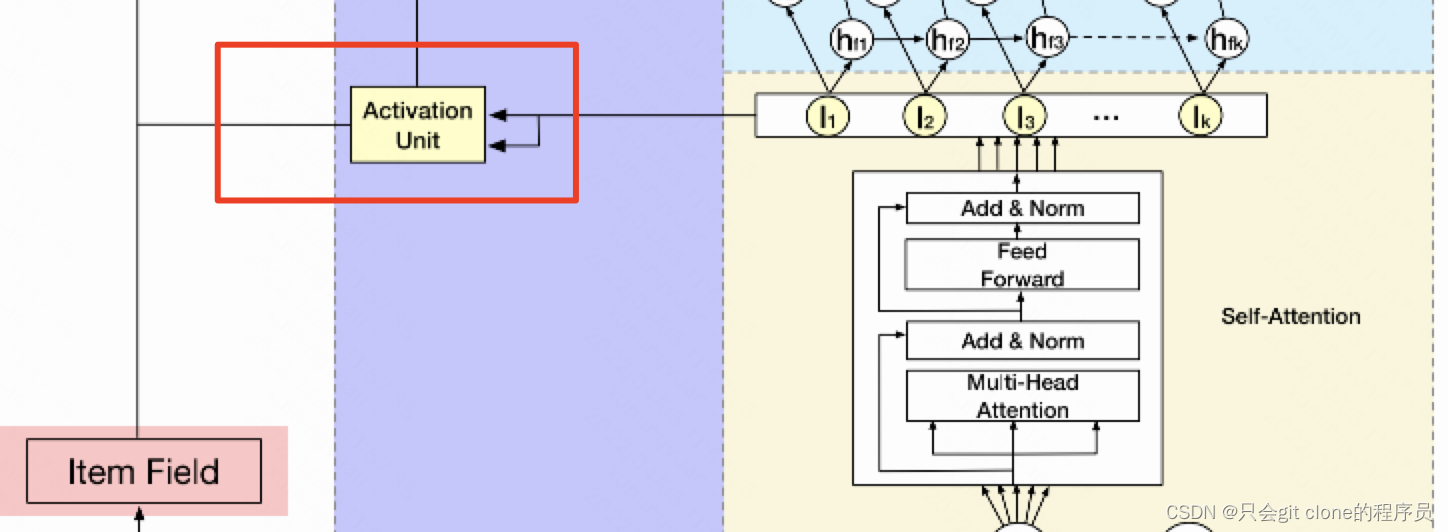
然后上图就是用k时间区间的特征和item特征计算attention,这个attention就是DIN里面一样的结构,可以参考我之前的解读:DIN,相当于计算某个时刻的兴趣对item的重要程度然后对k个时刻的兴趣做加权求和。

上图的话就是用Bi-LSTM建模多个时刻兴趣的演变过程,接着计算某个时刻的兴趣对item的重要程度然后对k个时刻的兴趣做加权求和。
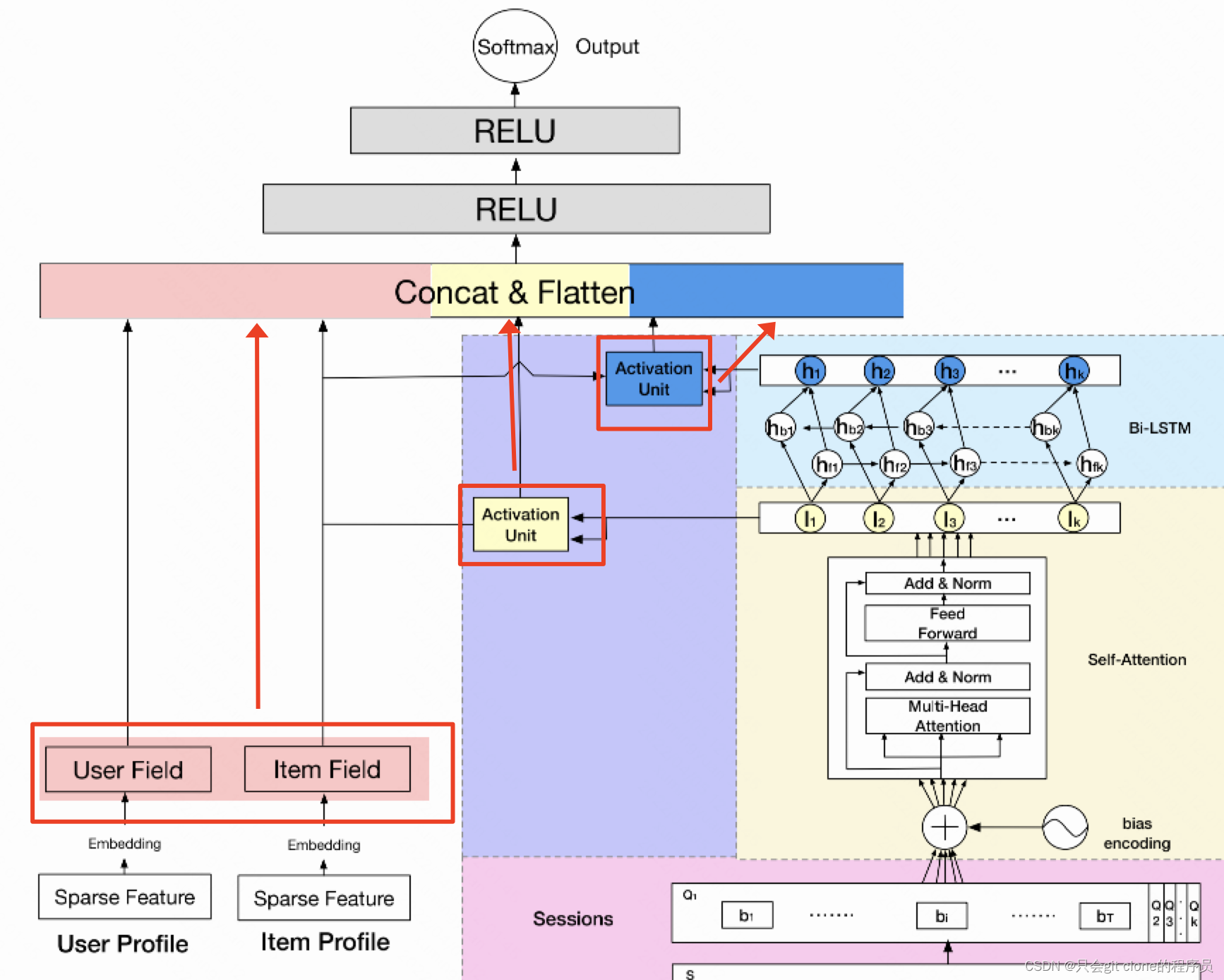
最后就是把三个模块输出的特征拼接起来,过几层FC之后计算损失预测CTR了。
效果
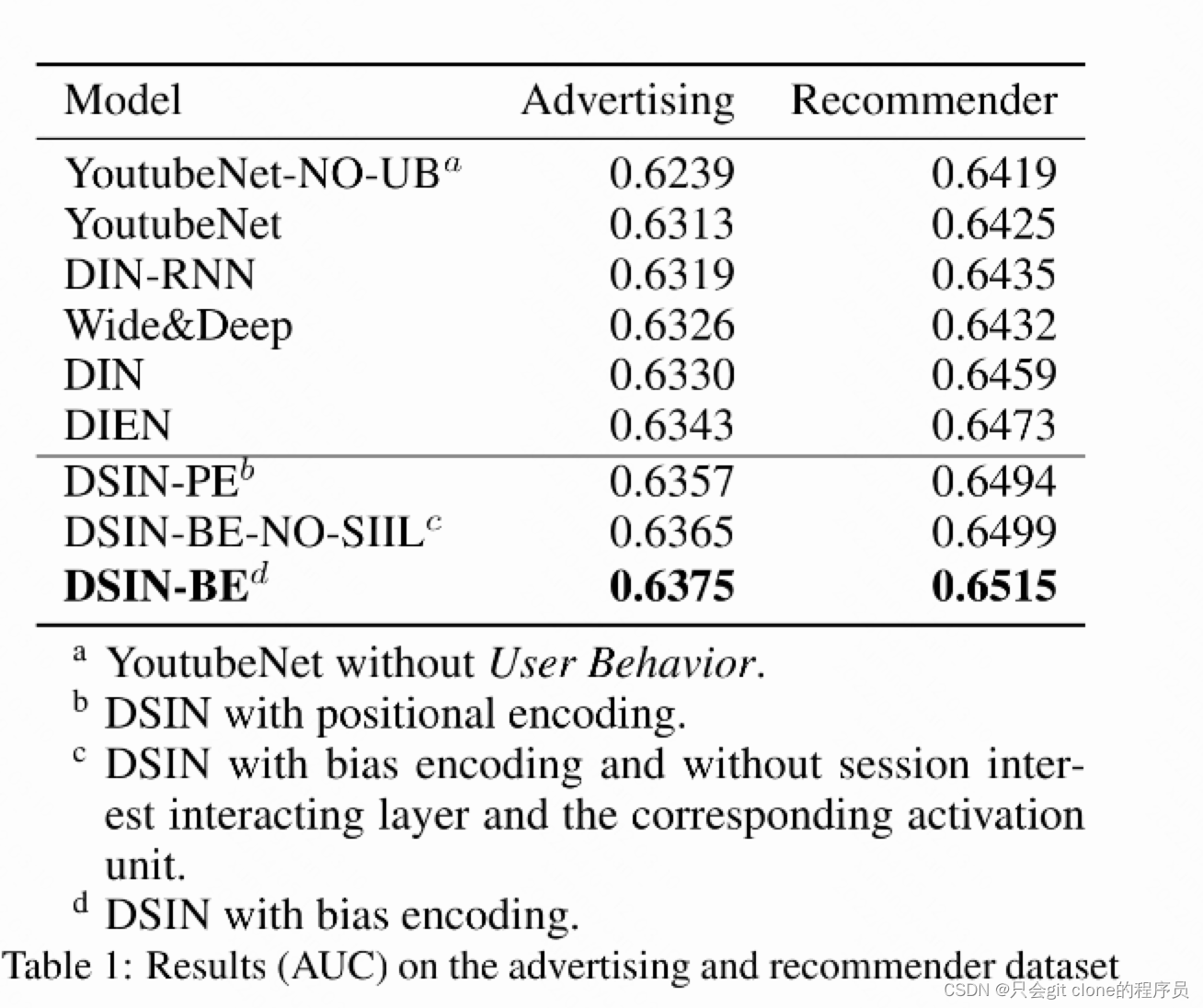
对比DIN外加了一个self-attention层和BiLSTM层,看着比DIN涨了一个点,但是结构比DIN复杂多了,所以有没有必要呢也不好说了…