深度神经网络 (DNN) 已经发展到现在已经可以在计算机视觉和自然语言处理等许多任务上表现非常出色。而现在主要的研究是如何训练这些 DNN 以提高其准确性。准确性的主要问题是神经网络极易受到对抗性扰动的影响。
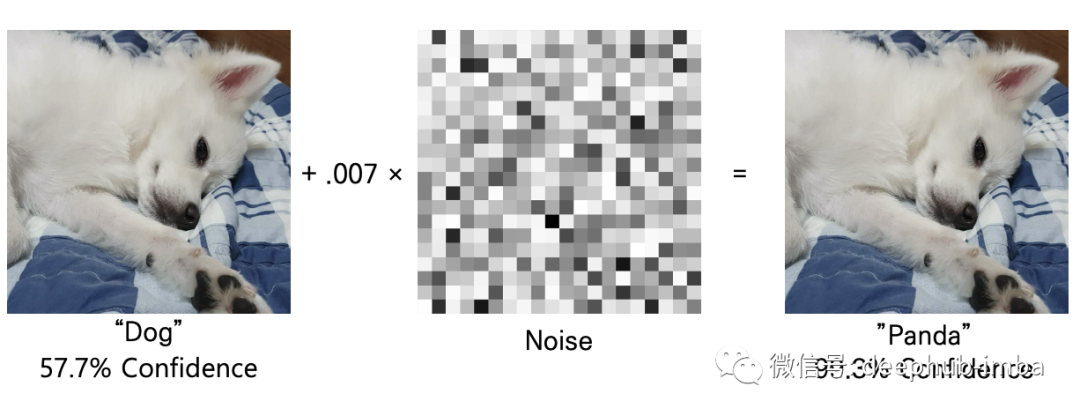
例如下面的图片,添加噪声之前和之后的两张图像对我们来说似乎相同。但对于神经网络来说,右边的图像是一个完全不同的对象――熊猫。添加到图像中的噪声是一种对抗性扰动,我们将试图通过使这些神经网络不易受扰动来解决这个问题的训练方法将被称为对抗性训练。
由于最近提出的使用未标记分布 (UID) 数据的数据增强方法,对抗性训练的缺乏训练数据的问题已被分解决了。但是它还存在一些缺点:缺乏可用性和对伪标签生成器准确性的依赖。
为了弥补这些缺点并提高对抗性和标准学习的泛化能力,论文提出了一种使用分布外 (OOD) 数据的数据增强方法:分布外数据增强训练 (OAT)。
什么是对抗训练?
为了理解为什么需要分布外数据增强训练来提高 DNN 的准确性和效率,首先要了解对抗性训练是什么以及为什么它很重要。
对抗性训练是指包含对抗性攻击图像作为其训练数据集的训练过程。对抗性训练的目标是让 DNN 更加健壮――让机器学习模型更不容易受到扰动的影响。
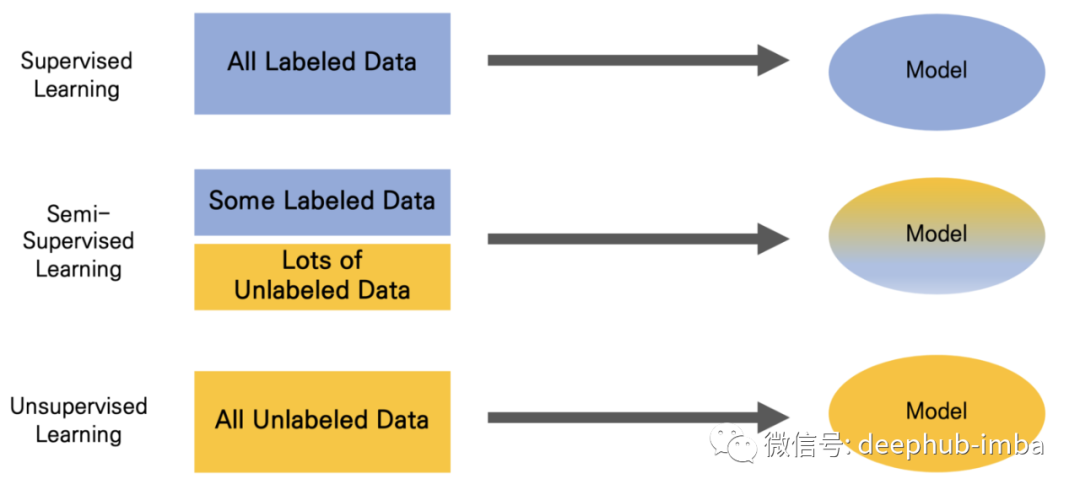
半监督学习方法
在对抗训练中需要比标准训练更多的数据集。所以仅使用标记数据是不够的,使用标记和未标记数据的混合指的就是半监督学习方法。
- 监督学习:仅使用标记数据作为其数据集
- 半监督学习:使用一些标记数据和大量未标记数据作为其数据集
- 无监督学习:仅使用未标记的数据作为其数据集
健壮和非健壮特征
由于人工智能的主要任务是模拟人类智能,因此图像识别过程也应该模拟人类。区分健壮特征和非健壮特征是不可或缺的,这是图像中两种有用的特征。
健壮的特征:人类可以感知的特征;与图像标签密切相关。
非健壮特征:人类无法感知的特征;与图像标签的相关性较弱。
已经证明,对抗性健壮性和标准准确性之间存在权衡关系。对抗性训练试图通过使非健壮特征不用于图像分类来解决这个问题。
分布外数据
分类器的算法应该能够识别扰动(不寻常的样本、离群值)。这是因为 (1) 错误分类这些扰动样本的可能性很高,(2) 错误分类的置信度很高。
分布外 (OOD) 数据非常接近正常数据――其中的大多数在人眼中看起来完全一样。这些 OOD 数据可能接近正常数据(作为模糊的、受到对抗性攻击的输入),甚至属于尚未出现在训练数据的新类别。
为什么这是必不可少的?例如, DNN 通常用于进一步用于诊断和治疗致命疾病的基因组序列细菌鉴定。在过去的几十年中发现了新的细菌类别,我们希望使用DNN 对这些细菌进行分类,但是具有高性能的分类器也可能错误地将某种疾病分类为另一种疾病,因为它是 OOD 数据――来自一个分类器尚未经过训练分类的全新类别。
与上面提到与熊猫的图像不同,即使它们被错误地分类也不会造成很大的问题,而基因组和细菌被错误地分类会导致很大的问题,这种真实的需求显示了 OOD 检测的重要性。
分布外数据增强训练
论文中提出了分布外增强训练(OAT),这是对目标数据集 D_t 和 OOD 数据集 D_o 的并集的训练。
OOD 数据集

分布外增强训练
OAT 算法是一种基于数据增强的健壮训练算法,训练经过精心设计的损失,从额外的 OOD 数据中受益。OOD 数据与随机标签一起提供给训练过程。
为所有 OOD 数据样本分配一个统一的分布标签。通过这个过程,可以利用 OOD 数据进行监督学习并且无需额外开销。这样使得 OOD 数据的限制性远低于未标记的分发中 (UID) 数据。
虽然 OOD 数据可用于提高神经网络的标准和泛化,但我们的目标是提高神经网络的分类精度。针对 OOD 数据样本对和均匀分布标签的对抗性训练会影响健壮特征和非健壮特征的权重。因此,目标数据集 D_t 和 OOD 数据集 D_o 的损失之间的平衡在 OAT 中至关重要。所以论文中引入以下算法,超参数αR^+,训练如下:
分布外增强对抗训练 (OAT-A)

**分布外增强标准训练 (OAT-S)
**
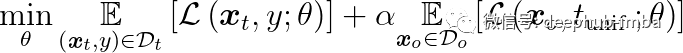
- (x_t,y) : 图像标签对
- L:损失函数
- S:一组对抗性扰动
- t_unif : 均匀分布标签
- θ : 网络参数
实验
论文结果表明,这种提供 OOD 数据的方式有助于消除对非健壮特征的依赖,从而提高健壮性。
从 8000 万小图像数据集 (80M-TI) 创建了 OOD 数据集,并将 ImageNet 的大小调整为 64x64 和 160x160 的尺寸,将它们分成包含 10 和 990 个类别的数据集,分别为 ImgNet 10 和 ImgNet990。
为 ImgNet10 上的实验调整了 Places365 和 VisDA-17 的大小,并将 Simpson Characters (Simpson) 和 Fashion Product (Fashion) 数据集裁剪为 32 × 32 的尺寸,用于 CIFAR10 和 CIFAR100 上的实验。
下面图表显示,无论目标数据集如何,OAT 都提高了测试的所有对抗性训练方法的健壮泛化能力。
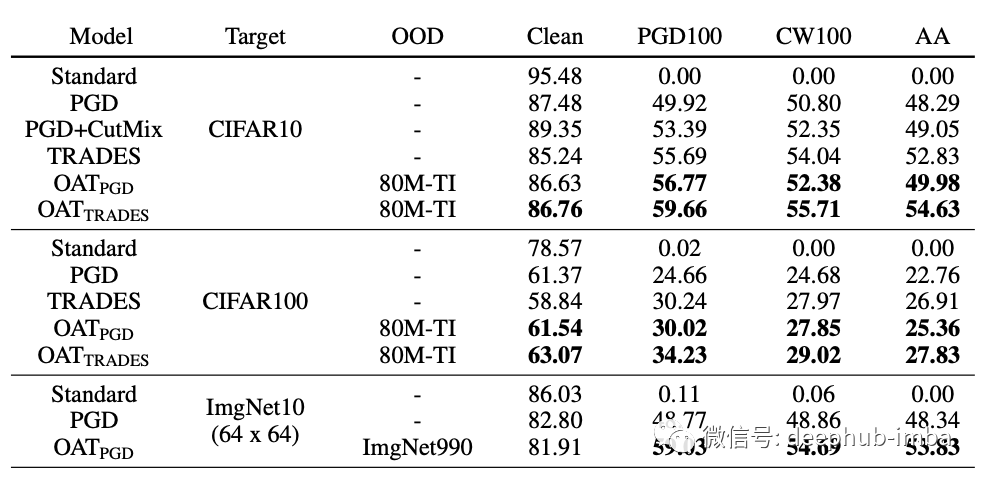
- Standard :在目标数据集上训练的模型。
- PGD:在目标数据集上使用基于PGD的对抗训练训练的模型。
- TRADES :在目标数据集上使用 TRADES 训练的模型。
- OAT_PGD :基于 PGD 方法使用 OAT 进行对抗训练的模型。
- OAT_TRADES :基于 TRADES 使用 OAT 进行对抗训练的模型。
- OAT_ D_o :通常使用 OOD 数据集 D_o 使用 OAT 训练的模型。
下面图表显示,即使使用了许多伪标记数据,OAT 仍然可以提高健壮泛化能力。

未来发展方向
通过在各种 OOD 数据集上进行的实验已经证明:从人类的角度来看,即使与目标数据集几乎没有相关性的 OOD 数据也可以通过论文所提出的方法受益于健壮和标准的泛化。因此可以表明:在不同的数据集之间,存在一个共同的“不受欢迎”的特征空间。还可以得出结论:当额外的 UID 数据可用时,即使使用大量伪标记数据,OAT 也可以提高泛化性能。
这是一个有意义的发现,使用 OOD 数据进行训练可以消除不需要的特征贡献。假设从实验结果来看,在对抗训练期间实施强大的对抗攻击似乎很困难――这可能是还需要进一步研究。如果使用构建的 OOD 数据来量化目标和具有强烈对抗性攻击的 OOD 数据集之间不良特征的共享程度,我们可以更接近于构建一个即使在严重扰动后也能将狗识别为狗的神经网络。
总结
感谢 Saehyung Lee 和论文“Removing Undesirable Feature Contributions Using Out-Of-Distribution Data”一文的合著者, 本博客中表达的观点和意见仅代表作者。
这篇文章基于以下论文:
Removing Undesirable Feature Contributions Using Out-Of-Distribution Data, Saehyung Lee, Changhwa Park, Hyungyu Lee, Jihun Yi, Jonghyun Lee, Sungroh Yoon?, International Conference on Learning Representations (ICLR) 2021,
https://openreview.net/forum?id=eIHYL6fpbkA
https://github.com/Saehyung-Lee/OAT
引用
data aug mentation method using unlabeled-in-distribution (UID) data.
https://papers.nips.cc/paper/2019/file/32e0bd1497aa43e02a42f47d9d6515ad-Paper.pdf
https://www.overfit.cn/post/29019f18a5894def8ccb022b5a4ba239
作者:Seyeon An