һ����Ϣ��
1. ����
����һ��������� X X X����Ϣ��,�� H H H��ʾ
�����������,��Ӧ���Ǹ���ȷ����ֵ(��������DZ仯��),����ѧ��ʹ�������������ֲ�ȷ��������:
H = �� x �� X P ( x ) ? x H = \sum_{x \in X}P(x)*x H=��x��X?P(x)?x����Ϣ��
���� x x xΪ������� X X X�IJ�ͬȡֵ
��ô����ͱ��������ھ��������(��һ���¼�)��,���������������Ϣ��
2. ��������
�ȴ�������������Ϣ��Ӧ�����������,��һ���µIJ�ȷ����Խ��(����ԽС),��ô������������Ϣ����Ӧ��Խ��,�෴,��ȷ����ԽС(����Խ��),��������Ϣ����ԽС;����̫���Ӷ�������������Ƿdz�ȷ����,��ȷ���Ժ�С,��ô�������Ҳ����ı�ʲô,Ҳ����ûʲô��Ϣ�����ɴ˵�֪,��Ϣ��Ӧ���ǹ��ڸ��ʵ���������,���СӦ�ø����ʳɷ���,���ʵķ�Χ�� [ 0 , 1 ] [0, 1] [0,1],��ô��Ϣ����Ӧ������ [ 0 , 1 ] [0, 1] [0,1]Ϊ���������������
����,��Ϣ����Ӧ�ñ�֤���Ǹ�ֵ(һ���½�¶����Ϣ��Ӧ������Ϊ0,�������Ǹ�ֵ)(Ҳ����˵��Ϣ���ڶ����� [ 0 , 1 ] [0, 1] [0,1]��ӦΪ�Ǹ�ֵ);�����ɼ���(ͬʱ��֪������,Ӧ�ñȸ�֪һ���µ���Ϣ��������)(��ʵ�ɼ��Ծ�ָʾ��Ӧ��ʹ�� l o g log log������);����ԽС,��Ϣ���������ٶ�Խ��,��֮,��Ϣ�������ٶ�Խ��,Ҳ����˵�ڶ����� [ 0 , 1 ] [0, 1] [0,1]��б��Ӧ�õݼ�(��Ȼ�ο�̫��������)
3. ��ʽ
��ô���������ĸ������ĺ���,Ҳ���Ǹ���������(�������б�İ�,���Ǹ����������dz�����),��ʽΪ ? l o g ( x ) -log(x) ?log(x)���������¼� x x x����Ϣ��,����Ϣ����Ҳ��Ϊ����Ϣ����������,��Ϣ�ص����幫ʽӦΪ:
H = ? �� x �� X P ( x ) ? l o g P ( x ) H = -\sum_{x \in X}P(x)*logP(x) H=?��x��X?P(x)?logP(x)
4. ����Ϣ����Ϣ��
����Ϣ��ʾһ��ȷ���¼�����Ϣ��,��һ���¼��IJ�ȷ����;����Ϣ�ر�ʾ�������������ϵͳ�IJ�ȷ����,����������ڲ�ͬ�¼��µ���Ϣ��������,������Ϣ��Խ��,��ʾ��ϵͳ�IJ�ȷ����Խ��
����������
H ( Y �O X ) H(Y|X) H(Y�OX),����Ϊ X X X���������� Y Y Y�������ֲ����ض� X X X����ѧ����
�������Ҳ̫š����,��������Ϊ,����֪ X X X�¼��������,�¼� Y Y Y����Ϣ������ X X X��һ����ȷ���¼�,�����Ҫͨ���� X X X��Ϊ�����¼� x x x,�ֱ���㲻ͬ x x x��Y����Ϣ��,��ʽӦΪ:
H ( Y �O X ) = �� x �� X P ( x ) H ( Y �O X = x ) H(Y|X) = \sum_{x \in X}P(x)H(Y|X=x) H(Y�OX)=��x��X?P(x)H(Y�OX=x)
��ô��Ҫ���� H ( Y �O X = x ) H(Y|X=x) H(Y�OX=x),��,��ȷ���¼� x x x��,���� Y Y Y����Ϣ��,ͬ����,��Ҫ��Ϊ Y Y Y�ľ����¼�:
H ( Y �O X ) = ? �� x �� X P ( x ) �� y �� Y P ( y �O x ) l o g P ( y �O x ) H(Y|X) = -\sum_{x \in X}P(x) \sum_{y \in Y}P(y|x)logP(y|x) H(Y�OX)=?��x��X?P(x)��y��Y?P(y�Ox)logP(y�Ox)
�����������ʵ�ת����ʽ:
H ( Y �O X ) = ? �� x �� X �� y �� Y P ( x , y ) l o g P ( y �O x ) H(Y|X) = -\sum_{x \in X} \sum_{y \in Y}P(x, y)logP(y|x) H(Y�OX)=?��x��X?��y��Y?P(x,y)logP(y�Ox)
��������Ϣ
1. ����
�����������֮��������̶ȵĶ���
2. ��ʽ
����������������� X X X, Y Y Y,��ôҪ���� Y Y Y������ X X X������Ӱ��,��Ӧ��ȥ����,��δ֪ Y Y Y����������� X X X��������Ϣ��,����֪ Y Y Y����������� X X X��������Ϣ��,��:
I ( X ; Y ) = H ( X ) ? H ( X �O Y ) I(X;Y) = H(X) - H(X|Y) I(X;Y)=H(X)?H(X�OY)
������������Ϣ�غ������صĽ���,���Ƕ����������:
I ( X ; Y ) = ? �� x �� X P ( x ) ? l o g P ( x ) + �� x �� X �� y �� Y P ( x , y ) l o g P ( x �O y ) I(X;Y) = -\sum_{x \in X}P(x)*logP(x) + \sum_{x \in X} \sum_{y \in Y}P(x, y)logP(x|y) I(X;Y)=?��x��X?P(x)?logP(x)+��x��X?��y��Y?P(x,y)logP(x�Oy)
���и���ȫ���ʹ�ʽ P ( x ) = �� y �� Y P ( x , y ) P(x) = \sum_{y \in Y}P(x, y) P(x)=��y��Y?P(x,y),�õ�:
I ( X ; Y ) = ? �� x �� X �� y �� Y P ( x , y ) ? l o g P ( x ) + �� x �� X �� y �� Y P ( x , y ) l o g P ( x �O y ) I(X;Y) = -\sum_{x \in X}\sum_{y \in Y}P(x, y)*logP(x) + \sum_{x \in X} \sum_{y \in Y}P(x, y)logP(x|y) I(X;Y)=?��x��X?��y��Y?P(x,y)?logP(x)+��x��X?��y��Y?P(x,y)logP(x�Oy)
Ȼ����Ժϲ�ͬ���� P ( x , y ) P(x, y) P(x,y):
I ( X ; Y ) = �� x �� X �� y �� Y P ( x , y ) ? l o g P ( x , y ) P ( x ) P ( y ) I(X;Y) = \sum_{x \in X}\sum_{y \in Y}P(x, y)*log \frac{P(x, y)}{P(x)P(y)} I(X;Y)=��x��X?��y��Y?P(x,y)?logP(x)P(y)P(x,y)?
3. Ӧ��
����Ϣ����Ϣ�صĹ�ϵ����ͨ����ͼ��ʾ:
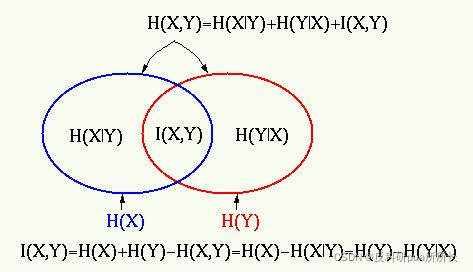
����������Ŀ����,Ҫʹ����Ϣ���,���������������¼��������,�����ѧϰ��,����������ݼ�����ϳ��ķֲ��������
���������������ͬʱ,����Ϣ���,��ʽ:
I ( X ; X ) = H ( X ) ? H ( X �O X ) = H ( X ) I(X;X) = H(X) - H(X|X) = H(X) I(X;X)=H(X)?H(X�OX)=H(X)
�ġ�������
�������������Ϣ�ص���һ������,��Ϊ������ij��������IJ�ȷ����Ҫ��������СŬ����������ȷ������������ķֲ�(����ʵ�ֲ�,��Ϊ p ( x ) p(x) p(x))ʱ,����Ŭ����ﵽ��С;�෴,����õ����Ƿ���ʵ�ֲ�(��Ϊ q ( x ) q(x) q(x))ʱ,��ҪΪ��������������IJ�ȷ���Ը�������Ŭ����������Ҫ�������ַ���ʵ�ֲ���Ҫ������Ŭ��,���õ��˽�����:
H ( p , q ) = ? �� x �� X p ( x ) l o g q ( x ) H(p, q) = -\sum_{x \in X}p(x)log q(x) H(p,q)=?��x��X?p(x)logq(x)
p ( x ) p(x) p(x)Ϊ����������ض�ȡֵ�µĸ���,����Dz����,�� l o g q ( x ) logq(x) logq(x)��ʾ��������ض�ȡֵ��,Ϊ��������ȷ������������Ŭ��,��һ������Էֲ��Ĺ�����ص�,������ȷ����,����Ŭ��С,��֮,������Ŭ����;
������ط������˸���,д���������ʽ:
H ( p , q ) = �� x �� X p ( x ) l o g 1 q ( x ) H(p,q) = \sum_{x \in X}p(x)log\frac{1}{q(x)} H(p,q)=��x��X?p(x)logq(x)1?
�塢�����,Ҳ��ΪKLɢ��
��һ��������̸��,��Ϣ�ؿ�������Ϊ,Ϊ��������ȷ��������������СŬ��,�������غ����˴��������������ķֲ�ʱ,������ȷ������������Ŭ��;��ô���ȥ�������ִ������ʱ��Ŭ��,����Ҫ��������СŬ��,����֮��IJ�����?���õ�������ء�
������������,���ǿ��Խ����Ϣ�غͽ����صĹ�ʽ(��Ȼ���� p p pΪ��ʵ�ֲ�):
D K L ( p �O �O q ) = H ( p , q ) ? H ( p ) D_{KL}(p||q) = H(p,q) - H(p) DKL?(p�O�Oq)=H(p,q)?H(p)
����,
D K L ( p �O �O q ) = ? �� x �� X p ( x ) l o g q ( x ) + �� x �� X p ( x ) l o g p ( x ) D_{KL}(p||q) = -\sum_{x \in X}p(x)logq(x) + \sum_{x \in X}p(x) logp(x) DKL?(p�O�Oq)=?��x��X?p(x)logq(x)+��x��X?p(x)logp(x)
��������,
D K L ( p �O �O q ) = �� x �� X p ( x ) l o g p ( x ) q ( x ) D_{KL}(p||q) = \sum_{x \in X}p(x)log \frac{p(x)}{q(x)} DKL?(p�O�Oq)=��x��X?p(x)logq(x)p(x)?
����������
������,����������confuse�������С������лл����ο�:
ͨ������������ - ��������� - ֪��
ʲô�ǡ�����Ϣ��? - ���ݮ�Ļش� - ֪��