一、语音增强发展历史
1987年:Lim和Oppenheim发表语音增强的维纳滤波方法;
1987年:Boll发表谱减法;
1980年:Maulay和Malpass提出软判决噪声一直方法;
1984年:Ephraim和Malah提出基于最小均方误差短时谱幅度估计的语音增强算法;
随后随着DSP发展,相继出现:最小均方(LMS)自适应滤波语音增强算法、基于短时谱(STS)估计的语音增强法、基于小波变换的语音增强算法、改进谱减法等。
二、语音信号特征以及语音信号模型
1.语音信号特征
语音生成过程与发音器官的运动过程密切相关。例如元音发音是气流不受口腔的阻碍发出的,辅音实在口腔阻碍气流时发出的音。同时根据声带的振动与否可以分为**清辅音(声带不振动)和浊辅音(声带振动)**两种。
清音的特点:
没有明显的时域和频域特征,看上去类似于白噪声
浊音的特点:
(1) 在时域上呈现出明显的周期性
(2) 频谱中有明显的几个凸起点,他们的出现频率与声道的谐振频率相对应,这些凸起点称为共振峰,其频率成为共振峰频率。
语音增强中可以利用浊音的明显周期性来区别一直非语音噪声。
2.语音信号模型
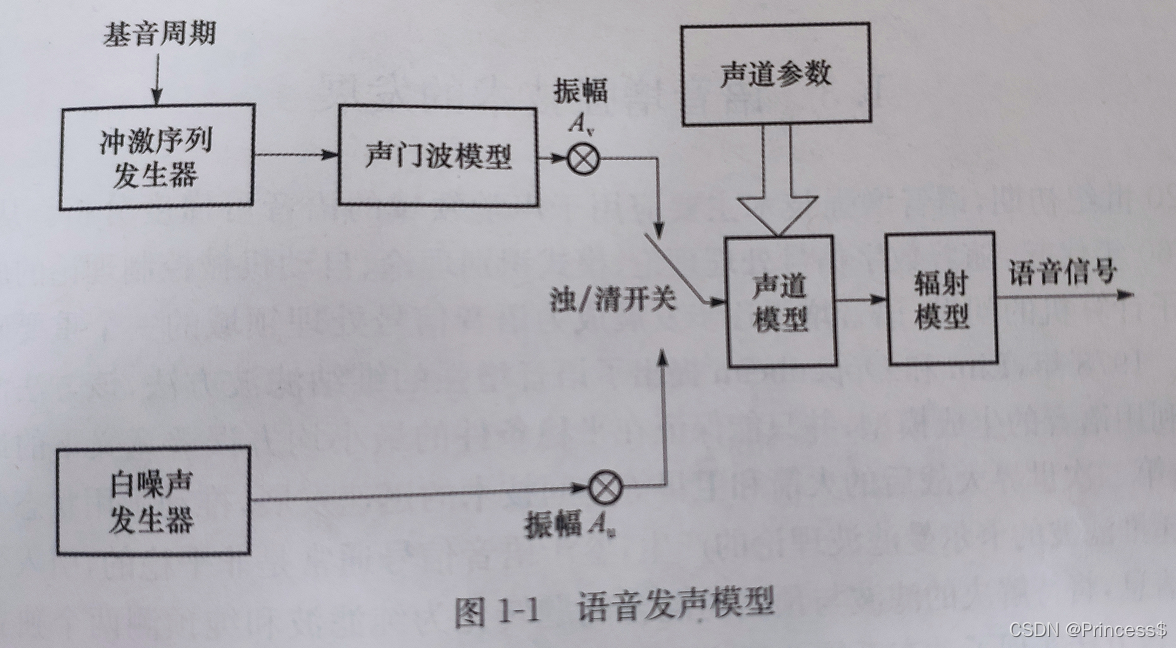
为了用计算机定量对语音信号进行模拟和处理,建立了语音发声模型 , 语音增强信号模型
1)语音发声模型
Av和Au分别为浊音和清音的激励幅度
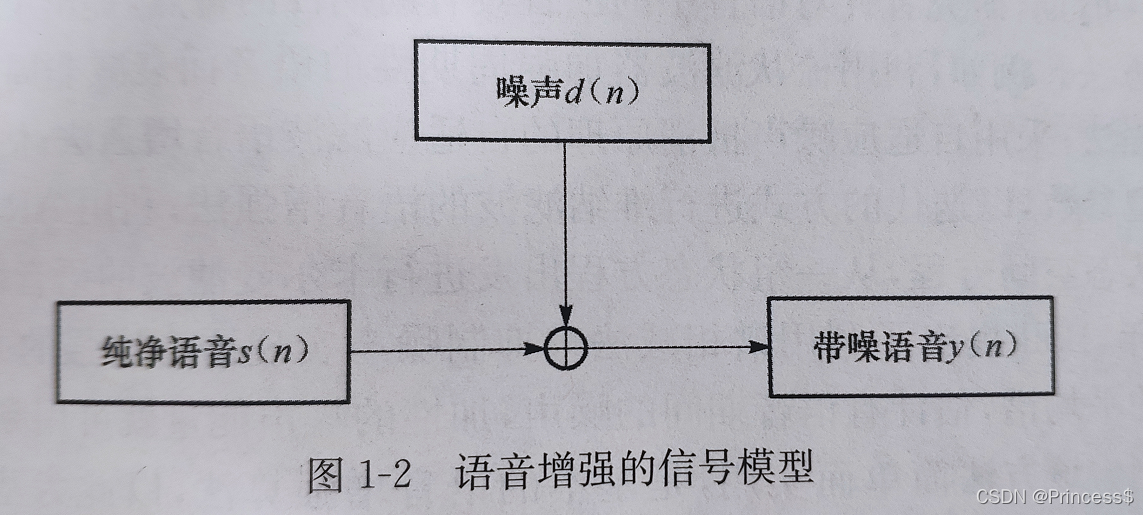
2)语音增强信号模型
表达式为 : y(n)=s(n)+d(n)
y(n) 表示带噪语音
s(n) 表示纯净语言
d(n) 表示干扰噪音
三、主要研究方法
1)谱减法
经典的谱减法通过假设噪声时平稳的加性噪声,且语音信号与噪声不相关,估计噪声频谱并减去该估计值得到估计的原声,从而实现语音增强。虽然这种方法容易实现,但这种方法在非平稳环境下处理效果不明显,并且在信噪比低的情况下,对语音的可懂度与自然度损害较大。
2)噪声对消法(自适应滤波技术)
需要采集背景噪声作为参考信号,易班采用自适应滤波技术,在输入信号与统计特征或变化未知的情况下,通过调整自身参数,来达到最佳滤波效果。有”自主学习“的过程。
四、效果评价参数
信噪比(SNR)与分段信噪比(segment-SNR)
信噪比=语音信号平均功率/噪声信号的平均功率
信噪比越大,说明噪声和失真越小,波形越接近纯净语音波形