从Transformer到VIT再到MAE
引言
最近一年来,Transformer在CV领域又掀起了一股新的潮流,尤其是ViT这篇文章,可以说是在CV的Transformer的应用方面挖了一个大坑,后面也如雨后春笋般掀起了一个改进和优化ViT的大潮,或者说在VIT的启发下又出现了新的方法(比方说MAE,BEIT等)。
这篇文章的主要目的是梳理从Transformer到VIT再到MAE都有什么思路上,架构上的变化,为什么要对某些地方进行修改或者提升,以及一些具体的技术细节,总的来说,是为了穿起来一个故事,来介绍这一整个趋势的前因后果和我自己的一些思考。
并且这三篇论文的写作可以说都是很成功的,从写作的角度也可以学到如何书写一篇优秀的论文。
Transfomer
先放论文链接:Attention Is All You Need
提出的背景
这篇文章在最初的时候是针对机器翻译的场景下提出的。
相对于RNN提出的主要原因
- RNN的计算是单向序列化的,当前词的状态是由钱前一个隐藏状态和当前词共同决定的,这样就保证了信息的传递。但这样带来的缺点是,计算当前状态的时候,必须要前面的状态计算完成才可以,是无法并行的,不能发挥GPU的计算优势。
- 如果当前的序列比较长,前面的状态都需要存下来,导致内存开销比较大。
相对于CNN提出的主要原因:
每个卷积核比较小(例如3*3),如果两个像素的距离比较远的话,想要融合两个像素的信息则需要很多层卷积才能办到。用注意力机制的话可以一次看到所有的输入序列。
模型架构
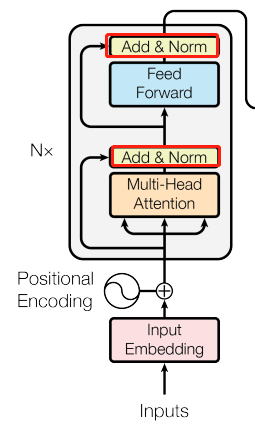
这里用的是论文里面的插图:

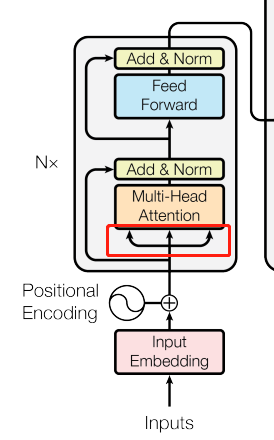
左边框内的是编码器,右边框内的是解码器,编码器解码器的层数都是N层的。
编码器:一次性可以看全句子,将输入序列的每一个元素转化为一系列的连续的向量。
解码器:自回归,在过去时刻的输出作为当前的输入,一个词一个词的往外翻译,不能看到全句。
具体细节
Add&Norm
这一层相当于是ResNet的直连和Normalization
但是需要注意的是,RseNet的Normalization是指在Batch中的Normalization,针对的场景是我们输入图片的尺寸都是相同的,这样的话可以对一个batch内的所有图片做Norm,但是对于文本序列来讲,很有可能长度是不一样的,这样在一个batch内做norm就会失去意义,因为尺度是不同的,用较短的序列求得的batch norm不一定会适合长序列,会有抖动比较大的问题。
所以,这里的Norm采用的是layer norm,是对每个样本的不同feature做的normalization,而batch norm是对同一个特征的不同样本做的normalization。
Attention:
首先来解释什么是attention,一句话解释就是有等长的value和key,按照query与key的相似度来确定每个value对输出的权重。
例如,现在有v1,v2,v3三个value和k1,k2,k3三个key,当一个新的输入query进来的时候,计算query和k1,k2,k3的相似度之后,发现query与k1最接近,所以输出的值中v1占最大的权重,v2次之,v3最小,得到最后的输出。不同的相似函数会有不同的注意力版本。Transformer用的相当于是内积。
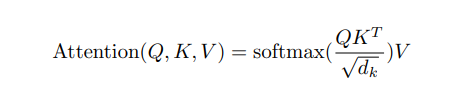
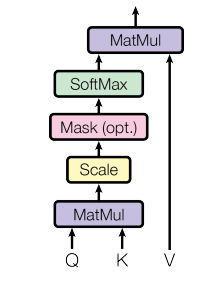
这里的Q,K,V分别是Query矩阵,Key矩阵,Value矩阵,dk代表的是每个key的维度,如果我们有n个query,每个query有dk个维度写成一个矩阵,Q就是n*dk的维度,然后我们有m个key(注意n和m可以不同的)这样的话,K矩阵就是m*dk的维度,转置之后是dk*m的维度,和Q相乘之后,是n*m的维度,算到这里,相当于我们已经计算出了query中每个q对应m个key的相似度了(这里用的是内积的方法,其实就是cos距离)然后再做一次根号dk的归一化,并且用softmax对每个q对应的m个key的相似程度进行转换,得到的n*m的矩阵就是权重,再乘以m*dv的V矩阵,就是加权的结果,一次输出了n个query的结果,并行能力大大提升! 两次矩阵乘法可以高效计算。
根号dk的归一化主要是为了解决序列过长的时候softmax输出向0或者1偏斜导致梯度过小收敛慢的问题。
Mask的作用:避免模型在t时间看到t时间之后的序列,这样具体操作就是在t时间之后的输出换成一个很大的负数,这样经过softmax之后,计算结果会趋于0,自动的抛去了。
Multi-Head Attention
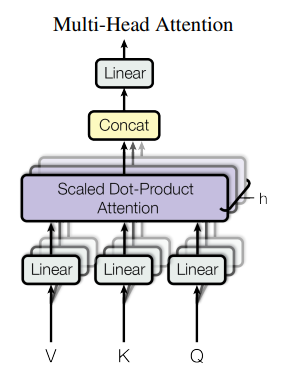
为什么做多头注意力:
从上面attention的分析来看,所有的计算都说是线性的,没有什么可供学习的参数,这里仿照CNN多通道的思路,VKQ线性投影h次到不同的低维空间(也就是给h次机会投影),其中投影的方向是可以学习的参数,然后对不同的头的结果再做一次投影回到原来的大小。也就是说,没有多头的概念模型是不能学到东西的。
自注意力机制(self attention)
这里的QKV都是从输如来的,分成了QKV,所以叫自注意力

接下来重点关注解码器的多头注意力,也就是红色标出来的地方,其中k和v是当前的输出,q来自于上一个时刻的输出,然后通过注意力机制来预测下一个时刻的输出,这样就完成了一个词一个词往外蹦的效果。即根据当前解码器的输入,去编码器的输出里面挑我感兴趣的地方。
Positional Encoding
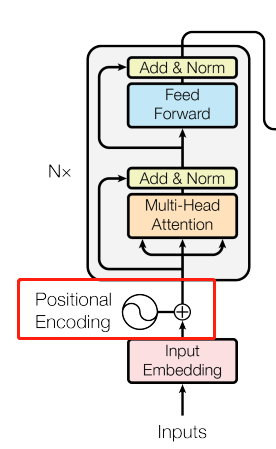
这个部分主要是为了解决输入没有序列顺序信息的问题。不像是RNN用上一个状态来表示过去的时序信息,Transformer
具体做法是用周期不同的sin和cos函数将当前词的位置信息转化成一个长为512的向量,再相加到input的向量中。
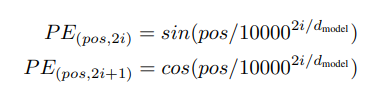
ViT
照例是论文链接:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
提出的背景:
ViT主要是针对在CV领域还没有用Transformer的情况下提出的,提出之后,可以用于同一个模型框架的多模态任务当中。卷积神经网络还是主流,但是自注意力又很香。
解决的主要困难:
- 如何把图片序列化:把224*224的图片拆分成patch,每一个大小是16*16
- 把像素级的计算转化到了patch级的计算
模型架构:

具体细节:
维度
如果输入图片大小是224*224大小,每个patch我们设定的大小为16*16,这样的话,我们能得到14*14个图像块(224/16=14),共196个图像块。每个小块的维度就是16*16*3=768,所以原来的224*224*3变成了196*768,所以到这里,一张图片就变成了196个元素,每个元素有768维度的序列。
序列信息
同样,我们注意到在Transformer当中是有位置编码部分的,我们在图像的处理中当然也需要这部分,也就是下面图里的操作:

具体的操作是有一个表,表的每一行代表了图片的顺序,列的维度是768,然后把序列信息加到187*768的维度里面,这样的话就完成了数据的预处理。
这里用到的是1-D的位置编码(1-196),另外还有2-D的位置编码,具体是用行和列共同表示,例如11,12,13…21,22,23…这样的
Class Token的作用:
即上面图片的0#token,这里借鉴了BERT里面的Class Token, 是一个可以学习的特征,和图像的特征有相同的维度(768),但只有一个token,最终将这个输出当成整个transformer的输出。这样的话就和CNN的最终输出结果很像了。
但是需要注意的是,实际上ViT的输出也可以直接做全局平均池化来得到输出而不一定非得用 CLS, 这里只是为了保证大部分的操作与Transformer是相同的。
Transformer处理任意长度的输入
理论上是可以的,但是如果输入的大小改变了,相当于计算的patch的个数增加了,与训练好的模型就不好用了,这里也可以采用插值的方式来解决。
结论:
- 因为相对于CNN缺少一些归纳偏置(局部信息和平移等变性),导致在中小数据集上的效果不是那么好。
- 目前随着数据的增加,ViT还没有达到明显的过拟合,还有提升空间。
- 自注意力可以模拟长距离的关系,即对于距离比较远的两个像素的关系。随层数的增加距离会越来越远。
MAE(CV版的BERT完形填空)
论文链接:Masked Autoencoders Are Scalable Vision Learners
提出的背景
ViT的最大问题就是用Transformer的时候还是用的有监督的方式,而NLP任务中的Transformer大部分用的是自监督的方式,如何能在Transformer的方法中使用自监督的方法,就是MAE提出的背景。
模型架构
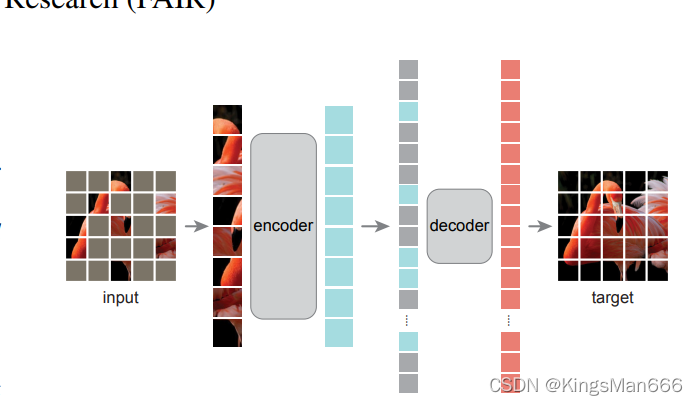
非对称的编解码器结构。非对称的意思是编码器只能看到可见的块(这样也可以极大的减少计算量),解码器可以看到全部。
一张图片进来,切小块,然后随机盖住,encoder收到的是未盖住的图片,然后我们补上缺失的序列,再送到decoder中去,得到的输出就是补全的结果。
注意的细节
图片和语言的区别
一个词是一个语义单元,但是在图片的前提下,可能一个patch里面有好几种物体。
图片的冗余性
图片的冗余性实际上是很高的,这就是为什么MAE中要去掉75%甚至80%的像素块,因为简单的确实完全可以通过插值来恢复。