������Ȼ���ԵĶ�߶ȶ�άʱ����������ʱ�̶�λ�����Ķ�
��������
�����ɲ�ѯָ������Ƶ���ƥ��ʱ�Ρ�
����˵��
V:δ������Ƶ
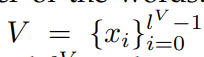
xi������Ƶ�е�֡
lV������Ƶ��֡������
S:��ѯ����
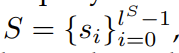
si ������������
ls�������ʵ�����Ŀ
M:���ƥ��ʱ�� ʹ��xi xj�ֱ��ʾ��ʼ�ͽ���֡
������Ƕ������Ա�ʾ
- ��ȡ��ѯ��������
�����������S�е�ÿ������Siͨ��word2vecģ��������Ƕ��ʸ��
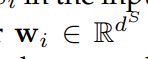
dS�������ij���
2. ������Ƕ��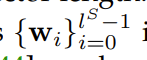
��������˫��LSTM����
3. ʹ��ƽ�������Ϊ������ӵ�������ʾ��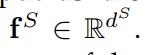
4. ��ȡ�������Բ�ѯ�������Խṹ���б���,�Ӷ���������Ȥ��ʱ�̡�
���ڶ�άʱ������map����Ƶ��ʾ
��������Ƶ������ȡʱ������(moment features),��������άʱ������ͼ
- ����һ��������Ƶ,�������Ƚ���ָ��С�ķ��ص�����ƵƬ��,ÿ��Ƭ����T��������֡���
- ����ÿ����ƵƬ��,����ʹ��Ԥ��ѵ����CNNģ����ȡ������
- Ϊ����ͨ��ά�������ɸ����ѹ����ƵƬ�α�ʾ,���ǽ���ƵƬ����������һ������dV���ͨ����ȫ���Ӳ�
- ����ѹ������ƵƬ�α���ʾΪ
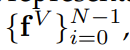
N����ƵƬ�ε����� - N����Ƶ��ʱ�̺�ѡ�ṹ�Ļ���Ԫ��,���ʹ����ƵƬ������������ѡʱ�̵�map��
- ʹ��stacked CNN���Ϊ������ͬ����,������ͬһʱ�俪ʼ��ʱ��������
- ʹ��ϡ��������ԡ�

ͨ�����ַ���,���ǶԶ̳���ʱ���ʱ�̽������ܼ�����,���س���ʱ�̱䳤ʱ,�����Ӳ��������

���ֲ������Կ��Դ����ٺ�ѡ�ص�����,ͬʱ���ͼ������� - ������������ʱ���ع�Ϊһ��2ά��ʱ������map
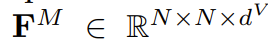
FM������ά��:ǰ����N�ֱ��ʾ��ʼ�ͽ�������,dV��ʾ����ά�ȡ�
��һ����va���Ƭ�ο�ʼ����b��Ƭ��������map���ʾΪ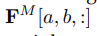
����j�������ĵ�i�������ʾΪ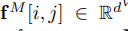
����Ӧ������ӳ���ϵ�(a,b)��λ��:

��߶ȶ�άʱ����������
- ���Ƚ���άʱ��ӳ��FM���������FS�ں�:ͨ��ȫ���Ӳ㽫������������ͶӰ��ͬһ�ӿռ�
- �ں�
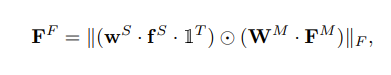
wS��WM����ȫ���Ӳ��ѧϰ����
1T����ȫ1������ת��

�������:��A=(aij)��B=(bij)������ͬ����,��cij=aij��bij,��ƾ���C=(cij)ΪA��B�Ĺ������,��ƻ�����
����A��Frobenius��������Ϊ����A����Ԫ�صľ���ֵƽ�����ܺ�,Ҳ����
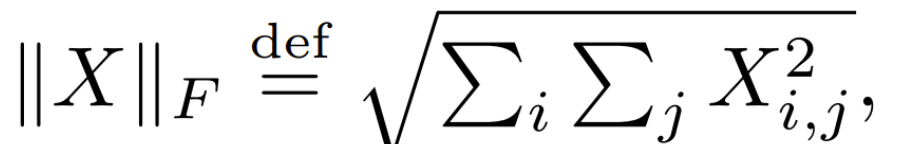
- �����߶�mapFF�ع�ΪK��߶ȵ�maps
- ������Ϊ2k���ں�����map��ȡ����k��ϡ��map,������˵:

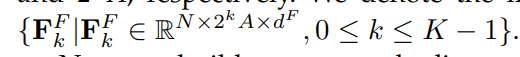
��߶�map
- �Ӷ�߶ȶ�ά����maps�Ͻ���ʱ���ٽ����硣ÿһ��map��Ӧ��L��gated convolutional ��
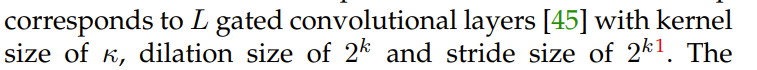
L����������������״����ͬ��(ͨ������)�C������Ƶ�ѧϰ��ѡʱ�̵IJ�ͬʱ,�ܸ��õ����������� - ͨ�����������ƵƬ�κͲ�ѯ����ƥ������������������map�ֱ�����ȫ��ͨ���sigmoid����,���ɶ�߶ȶ�ά����ͼ��
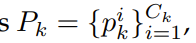
Ck��ָ��k��ͼ����Ч��ѡʱ�ε�����
stacked CNN ��Ⱦ�������
�ο�:https://blog.csdn.net/ljhjiayou/article/details/38380293
��Դ�ͼƬ����recognitionʱ,��Ҫ�õ��ලѧϰ�ķ���ȥpre-training(Ԥѵ��)stacked CNN��ÿ������,Ȼ����BP�㷨�������������fine-tuning(��),������һ��������Ϊ��һ������롣
��������֪��,convolution��pooling������Ϊʹ����ṹ������ѧϰ���IJ�����������,����ѧϰ������������һЩ������,����˵ƽ��,��ת�����ԡ��Զ�άͼ����ȡΪ��,ѧϰ�IJ���������������Ϊ����Ҫ������ͼƬ�����������뵽����,��ֻ��ѧϰ����һ����patch��������������������ڲ�����mean-pooling����max-pooling�ȷ�����
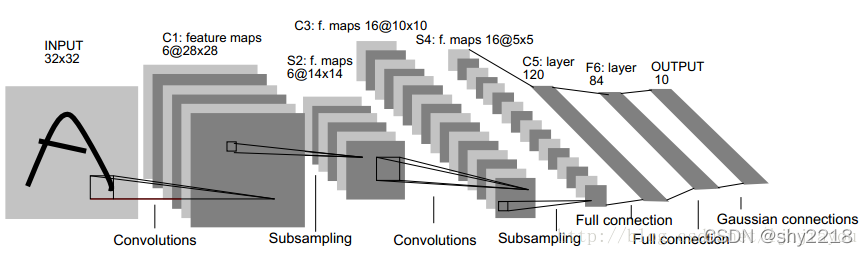
ÿ����һ��3232��С��ͼƬ,�����һ��84ά������,���������������ȡ��������������
�����C1������6��2828��С������ͼ����,����Դ��������6��55��С��patch��3232��С������ͼ����convolution�õ�,28=32-5+1,����ÿ���ƶ�����Ϊ1�����ء� ������s2��������6��1414��С������ͼ,ԭ����ÿ�ζ�4������(��22��)����pooling�õ�1��ֵ��
��S2������ͼ��1�������Ϊ150(=556,����5*5)���ڵ�,�����Ϊ16���ڵ���������convolution��
��߶�
